
요약
LLM의 프롬프팅 기법 중 추론(Reason Only) 및 행동 기반(Act Only) 기반의 단점을 극복하고 장점을 섞어 추론과 행동을 반복적으로 지속하는 프롬프팅 기법으로 높은 성능의 실험 성과를 도출함.
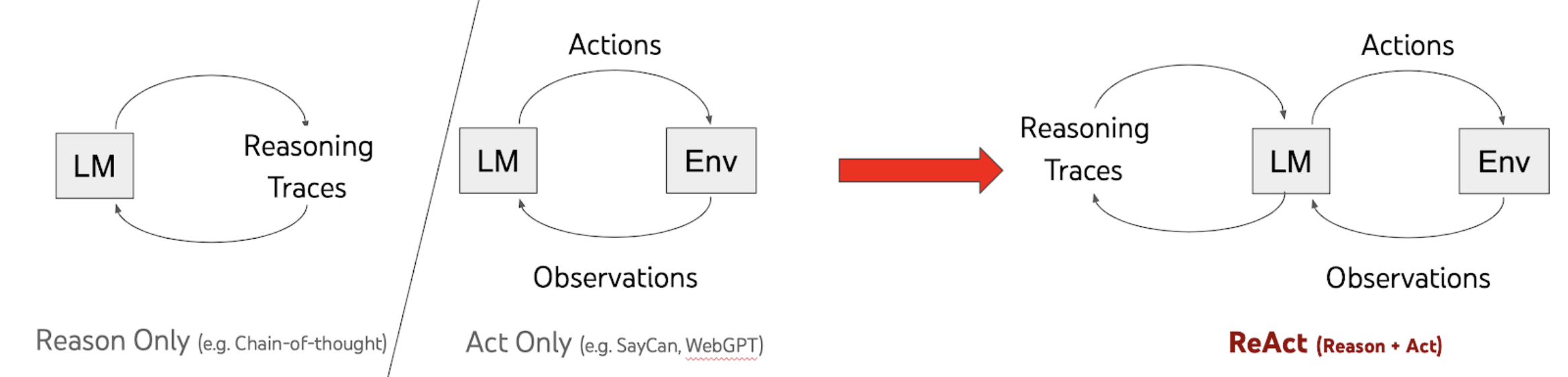
ReAct Prompting
ReAct 프롬프트는 Action에 따른 Environment Observation, 즉 사람이 작성한 추론 내역과 행동들을 기반으로한 few-shot 문제해결 trajectories로 구성됨.
직관적이고 설계상 유연성이 좋아 논문 발표 당시 몇몇 Task에서 SOTA 성능 달성함.
Trajectory : Reasoning/Thoughts, Actions, Observation 등 기본 프롬프트 질문에서 이어지는 과정을 나열한 것으로 ReAct Prompting 에서 few shot example로 제공하거나 fine tuning을 진행 후, 최종 질문을 하였을 때 학습된 Trajectory에 따라 추론, Act, Obs를 확인하도록 지시/유도함.
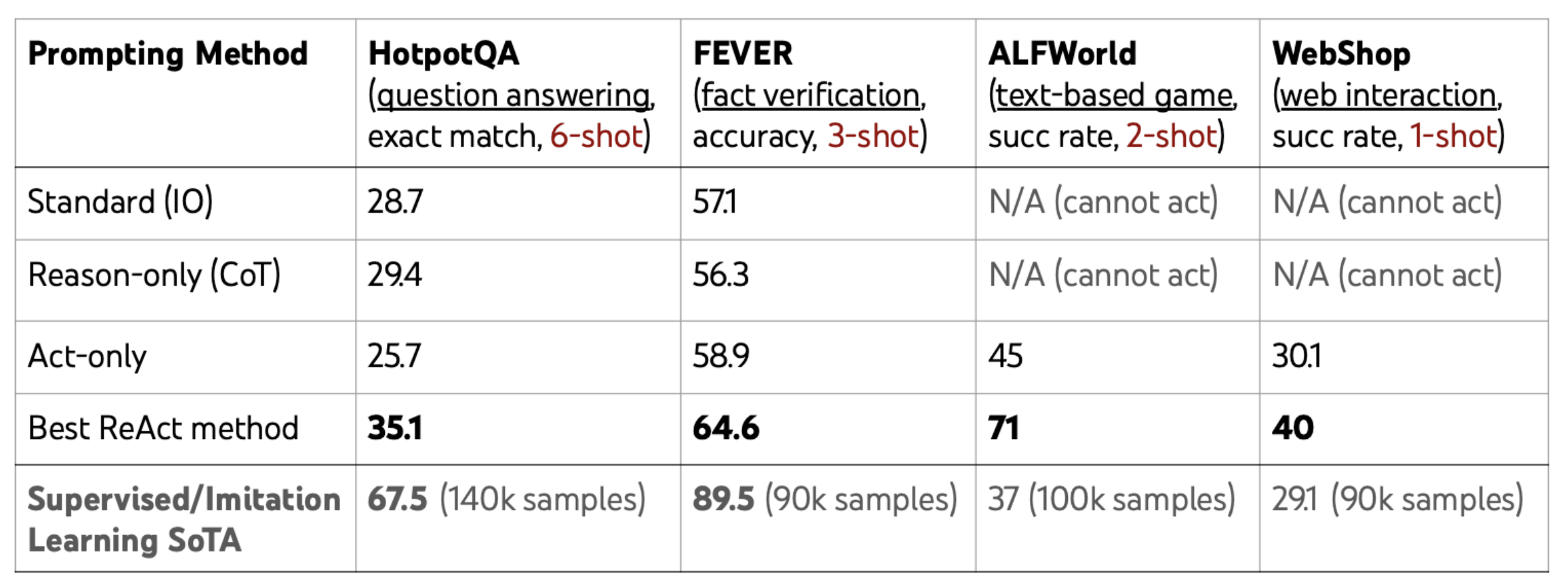
HotpotQA Example
아래 예시와 같이 Reason-only 모델은 자체 정보가 부족할 경우 Hallucination에 의한 부정확한 정보를 출력, Act-only 모델은 추론 능력 부족으로 외부 정보를 기반으로도 최종 답에 이르지 못하고 엉뚱한 대답을 하는 한계가 있다. (실제로 Action은 ReAct와 똑같이 함)
반면 ReAct는 해석가능하고 사실에 기반한 Trajectory로 task를 해결함.
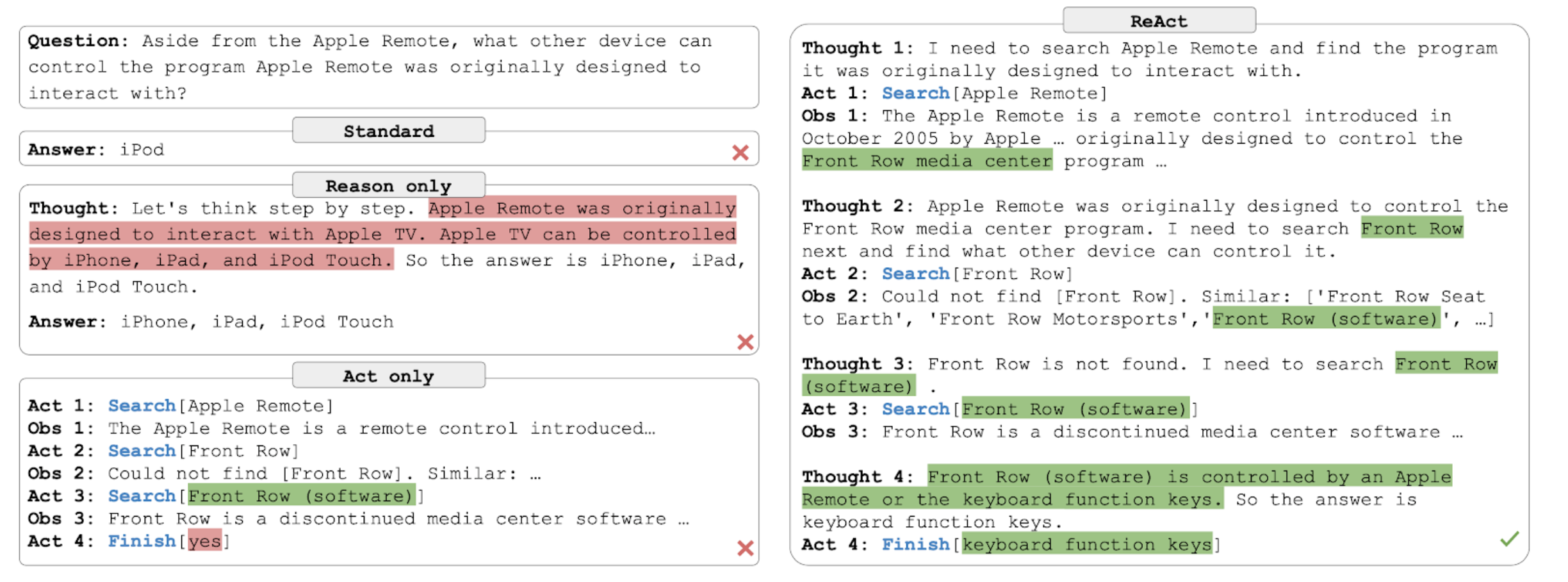
ALFWorld Example (텍스트로 구성된 방탈출 게임)
의사결정 문제에서는 추론을 위한 단서가 희소한 케이스에 인간의 추론 궤적을 설계해서 LM이 추론(Reasoning)을 수행할지 Action을 수행할 지 결정하도록 함. 아래의 ReAct 실패 사례 처럼 완벽하진 않지만, 인간의 검토 및 개입을 허용하는 새로운 접근법이라는 점에서도 의의가 있음.
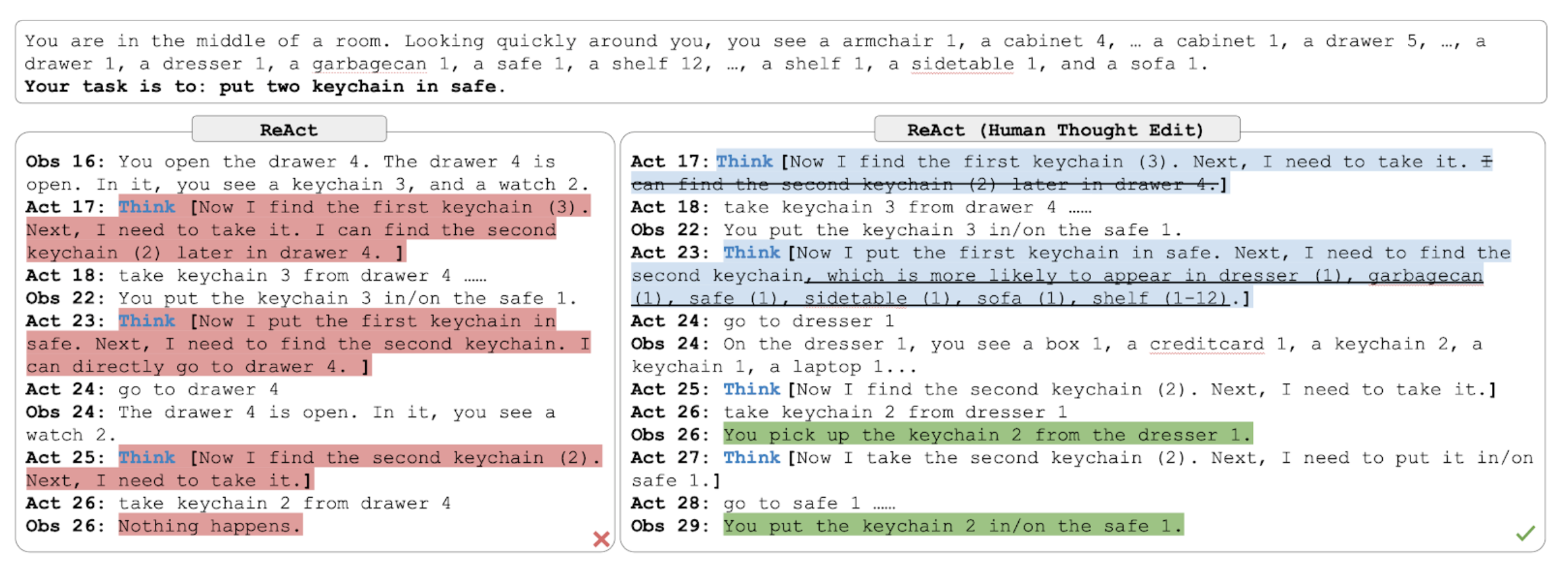
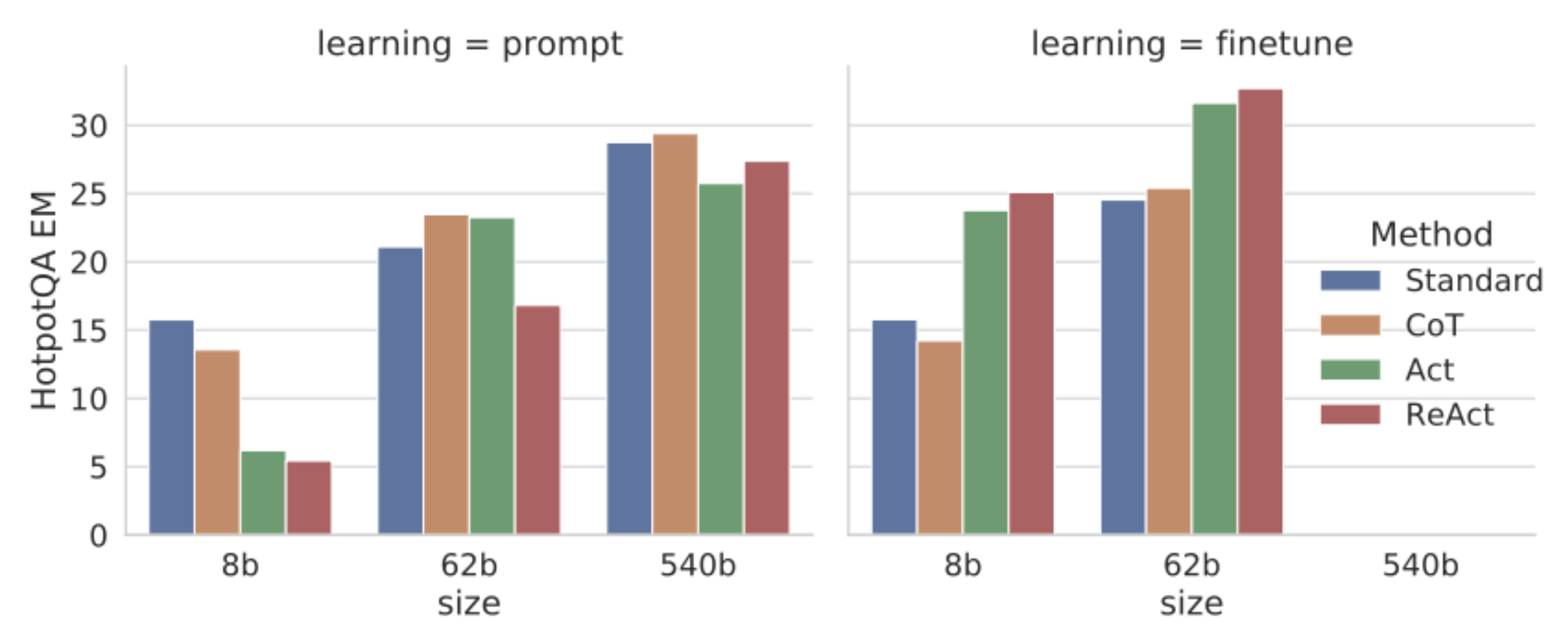
Finetuning (in ReAct) : Initial Results
파인튜닝 없이 테스트할 경우 PaLM-8b, 62b 사이즈에서는 오히려 4개 중 성능이 제일 낮음, 파인튜닝할 경우 모든 사이즈에서 다른 4개 보다 outperform하는 것을 보여줌 (EM : Exact Match, 단답형 문제)
Introduction
LLM의 프롬프팅 기법 중 추론(Reason Only) 및 행동 기반(Act Only) 기반의 단점을 극복하고 장점을 섞어 추론과 행동을 반복적으로 지속하는 프롬프팅 기법으로 높은 성능의 실험 성과를 도출함. 기존의 CoT 추론 방법은 Hallucination과 error propagation 발생 문제가 있었으나 ReAct에서 상당히 개선되고 좋은 성능을 보여줌
ReAct : Synergizing Reasoning + Acting
일반적인 환경과 상호작용하는 agent가 task solving 케이스에 투입 될 경우를 가정하면
Time step : t
Agent는 환경 관찰값을 ot O 를 수신
agent가 action at A 를 Policy (at|ct) 에 따라 행동하고 ct = (o1, a1, ..., ot-1, at-1, ot) ct는 agent에 있어 context가 된다.
추상적인 컨텍스트 이거나 computation이 많이 필요한 경우 ct -> at 매핑 policy 학습이 매우 어려운 경향을 보임.
여기서 ReAct에서는 A = A L 로 Language space인 L로 action space를 확장해서 고려하며 L에 속하는 action( a L) 은 추론 과정이 되며 외부 환경에 영향을 주지 않아 Observation feedback의 변화가 없는 성질을 가진다. 대신 a 현재 컨텍스트인 ct에서 추론을 통해 유용한 정보/질문을 생성해내는 역할을 하고 결론적으로 ct+1 = (ct, at)가 된다.
ReAct의 고유 강점/특징
- Intuitive and easy to design : ReAct 프롬프트 디자인은 직관적이고 자연어 사용으로 human annotator가 생각하는 정보를 직접 타이핑해서 생성할 수 있음
- General and flexible : 유연한 추론 공간 (Thought space) 와 추론-액션 포맷으로 다양한 task에 맞춰 적용될 수 있음
- Performant and robust : 새로운 유형의 Task에 대해서도 1~6의 in-context example을 이용해 좋은 성능을 낼 수 있음
- Human aligned and controllable : ReAct는 해석가능한 일련의 의사결정 및 추론 과정을 보여줄 수 있기 때문에 사람이 쉽게 추론 및 사실 관계를 확인할 수 있다. 또한 Thought editing을 통해 agent의 behavior를 직접 컨트롤 및 교정할 수도 있다.
Knowledge-Intensive Reasoning Tasks
HotPotQA
두 개 이상의 위키피디아 문단을 통해 추론을 요구하는 다중 홉(추론, 정보확인) 질의 응답 문제/답 벤치마크로 EM (exact match) 카운트가 성능 지표가 됨
FEVER
각각 문제가 제기하는 주장이 있으며 사실 검증을 위한 라벨링으로 “지원(supports)”, “반박(REFUTES)”, “정보 부족(Not ENOUGH INFO)"으로 되어 이를 위키피디아에 verification할 문단이 있는지 기반에서 결정을 내리는 문제임. (Fact Verification)
본 논문의 실험에서는 Question만 제시하고 뒷받침이 되는 위키피디아의 문단은 제공하지 않는 방식으로 진행해 LLM 자체 지식이나 action을 통해 정보를 가져와야하는 상황으로 세팅함.
Settings for HotpotQA and FEVER
- Action Spaces (wikipedia web API 3개 function 연동)
Search [entity] : 검색 entity에 연동되는 위키 페이지의 첫 5문장 반환
Lookup[string] : 해당 페이지에서 string을 포함하는 문장의 다음 문장 반환
Finish[answer] : 현재 task를 종료하고 최종 answer를 반환 - ReAct Prompting
학습 데이터에서 3~6개 케이스를 추출해 ReAct 방식의 trajectory를 구성해 few-shot example 로 제공해 프롬프트를 구성 (그 이상은 성능을 높이지 않는 것을 확인함) - Baselines
Standard prompting : ReAct Trajectory 에서 Thought, Act, Obs를 제거한 기본 프롬프트로 테스트
CoT prompting : Act, Obs를 제거해 추론만 하도록 지시한 프롬프트
Acting only prompt : Thoughts를 제거해 Action 및 그에 따른 환경 Observation 정보를 받아서 답을 도출하도록 한 프롬프트 - Combining Internal and External Knowledge
- Finetuning
- Results and Observations
- Results
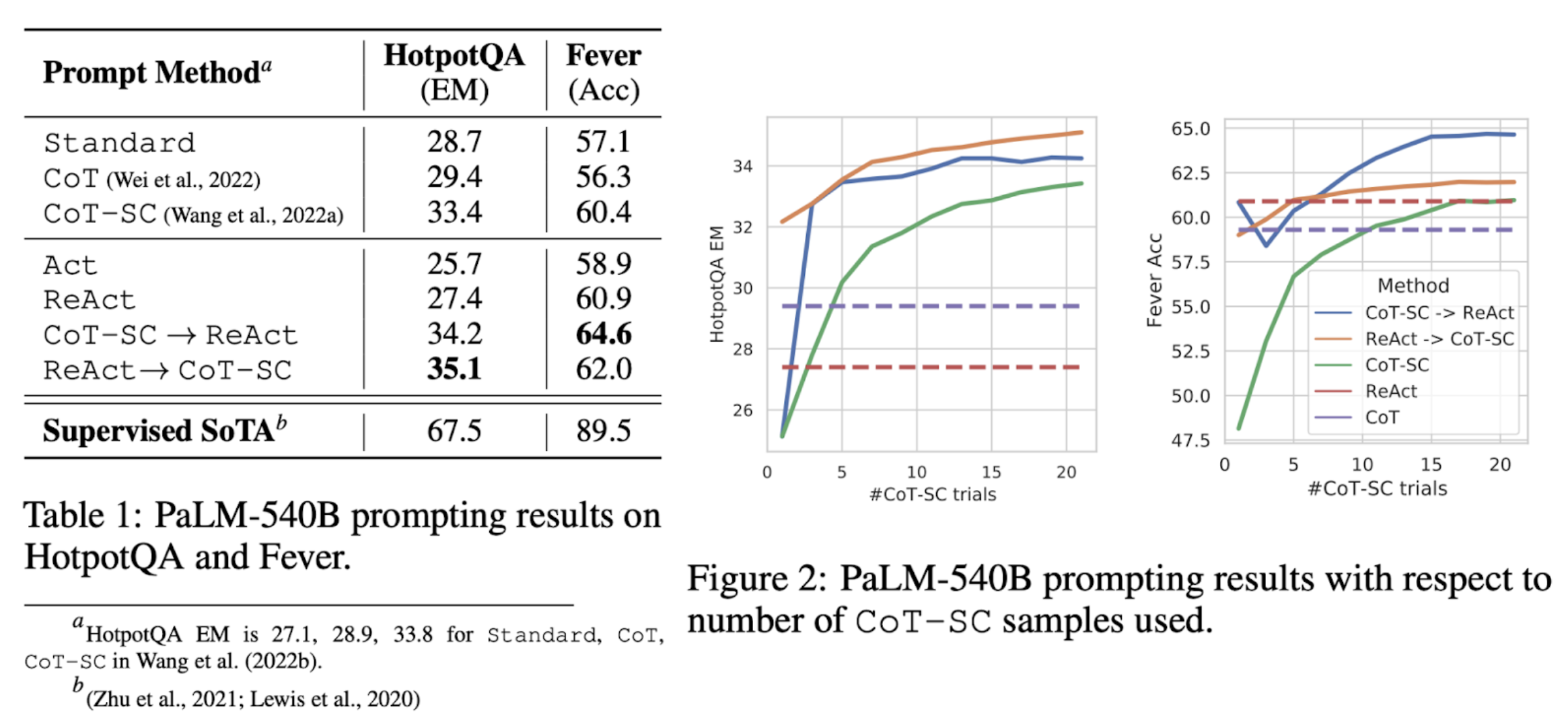
ReAct outperforms Act consistently - ReAct vs. CoT
- Hallucination is a serious problem for CoT
- While interleaving reasoning, action and observation steps improves ReAct’s groundedness and trustworthiness, such a structural constraint also reduces its flexibility in formulating reasoning steps
- For ReAct, successfully retrieving informative knowledge via search is critical. - ReAct + CoT-SC perform best for prompting LLMs
Decision Making Tasks
ALFWorld
Alfred 벤치마크에 맞춰 만들어진 텍스트 기반 게임 (방탈출과 비슷).
6개 타입의 Task가 있으며 reward가 적은 환경에서 여러 단계의 추론과 action을 거쳐 골을 성취하는 환경
WebShop
Amazon 온라인 쇼핑몰에서 추출한 환경으로 다양한 종류의 structured and unstructured 텍스트 정보가 있으며, 버튼을 눌러서 특정 상품으로 이동, 뒤로 가기, 상품 옵션 선택 등 액션이 가능함. “I am looking for a nightstand with drawers. It should be a nickel finish, and priced lower than $140” 같은 질문에 action을 통해 상품을 찾아가는 행위를 해서 groundtruth 상품에 도달할 경우 Success.

Result : ALFWorld, Webshop 모두에서 ReAct 성능이 Act 를 앞섬 (IL: Imitation Learning, RL : Reinforcement Learning)
-
ALFWorld
Best of 6 ReAct 모델이 평균 성공률 71%로 Act 45%, BUTLER 37%를 앞섬. 성능이 최저인 ReAct-IM(avg)마저 Act를 앞섬. Act대비 ReAct의 강점은 6번의 통제된 시도로 넓은 범위 (33%~90%)의 성공률이 나오게 됨. 추론 없이 단순 6번의 Action을 하는 Act모델에서는 한계가 있음 -
Webshop
One-shot Act Prompting 으로 이미 IL, IL+RL을 outperform함. 추론을 섞은 ReAct 는 상당한 성공률을 보이며 Act 대비 10%p의 향상을 보여준다. 성능 개선이 좋았으나 여전히 전문가 지수에는 못미침.
On the value of internal reasoning vs. external feedback (내부 모델 추론 vs 외부 피드백 가치 비교)
이전 연구중 ReAct와 가장 비슷한 연구는 IM (Inner Monologue) 논문이지만 해당 논문은 환경 state 정보와 목표 달성을 위한 하위 목표들이 제한적이라는 점에서 한계가 있음. ReAct의 경우 유연하고 Sparse 의사결정 space 특성으로 다각화 추론이 가능하며 이에 따라 다양한 task에 적용이 가능함.
ReAct차별점 증명을 위해 IM style Prompting을 통해서 테스트 한 결과 Table 3. 에서 보는 결과와 같이 6개 중 1개를 제외한 5개가 ReAct가 Outperform 하는 것을 확인함.
Conclusion
ReAct 여러 task에 적용가능해 유연하고, 자연어 Trajectory 확인해 해석 및 검증 가능하고, multi-hop Qa, Fact verification, Decision making 과 같은 추론이 필요한 task에서 높은 성능을 보임
