
Table of Contents
- Using yfinance to Extract Stock Info
- Using yfinance to Extract Historical Share Price Data
- Using yfinance to Extract Historical Dividends Data
- Downloading the Webpage Using Requests Library
- Parsing Webpage HTML Using BeautifulSoup
- Extracting Data and Building DataFrame
!pip install yfinance==0.1.67
!pip install pandas==1.3.3import yfinance as yf
import pandas as pdExtracting Stock Data Using a Python Library
Using the yfinance Library to Extract Stock Data
Using the Ticker module we can create an object that will allow us to access functions to extract data. To do this we need to provide the ticker symbol for the stock, here the company is Apple and the ticker symbol is AAPL.
https://pypi.org/project/yfinance/
apple = yf.Ticker("AAPL")Now we can access functions and variables to extract the type of data we need. You can view them and what they represent here https://aroussi.com/post/python-yahoo-finance.
Using the attribute info we can extract information about the stock as a Python dictionary.
apple_info=apple.info
apple_info
We can get the 'country' using the key country
apple_info['country']
Extracting Share Price
A share is the single smallest part of a company's stock that you can buy, the prices of these shares fluctuate over time. Using the history() method we can get the share price of the stock over a certain period of time. Using the period parameter we can set how far back from the present to get data. The options for period are 1 day (1d), 5d, 1 month (1mo) , 3mo, 6mo, 1 year (1y), 2y, 5y, 10y, ytd, and max.
apple_share_price_data = apple.history(period="max")The format that the data is returned in is a Pandas DataFrame. With the Date as the index the share Open, High, Low, Close, Volume, and Stock Splits are given for each day.
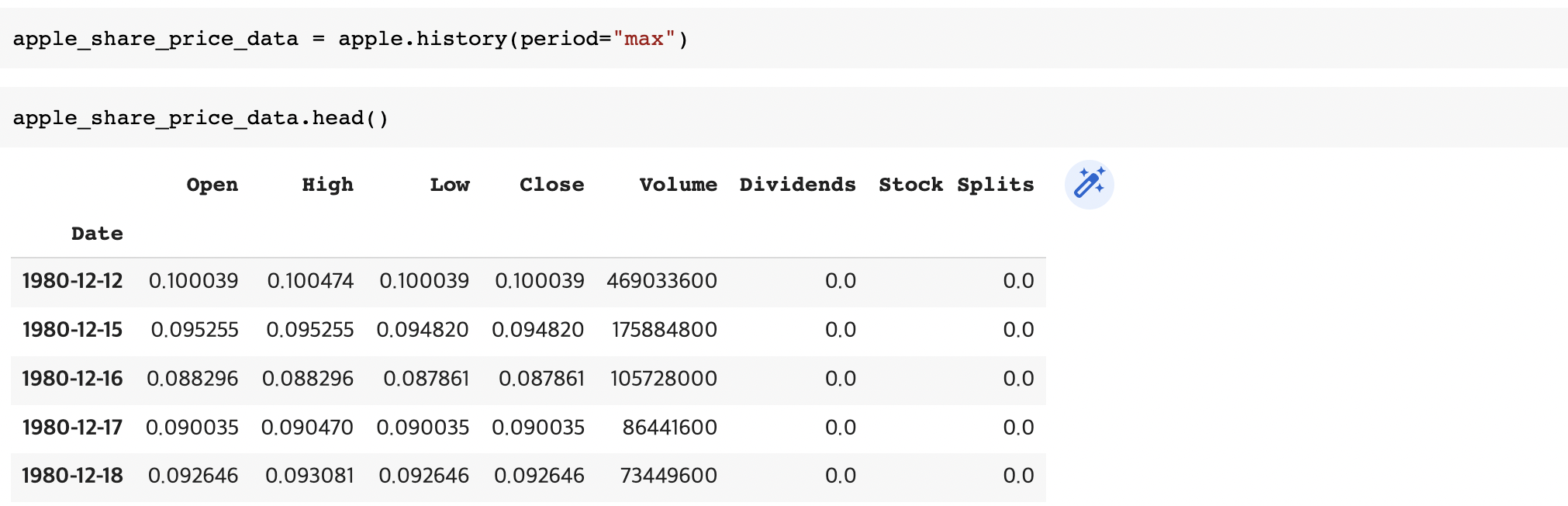
We can reset the index of the DataFrame with the reset_index function. We also set the inplace paramter to True so the change takes place to the DataFrame itself.
apple_share_price_data.reset_index(inplace=True)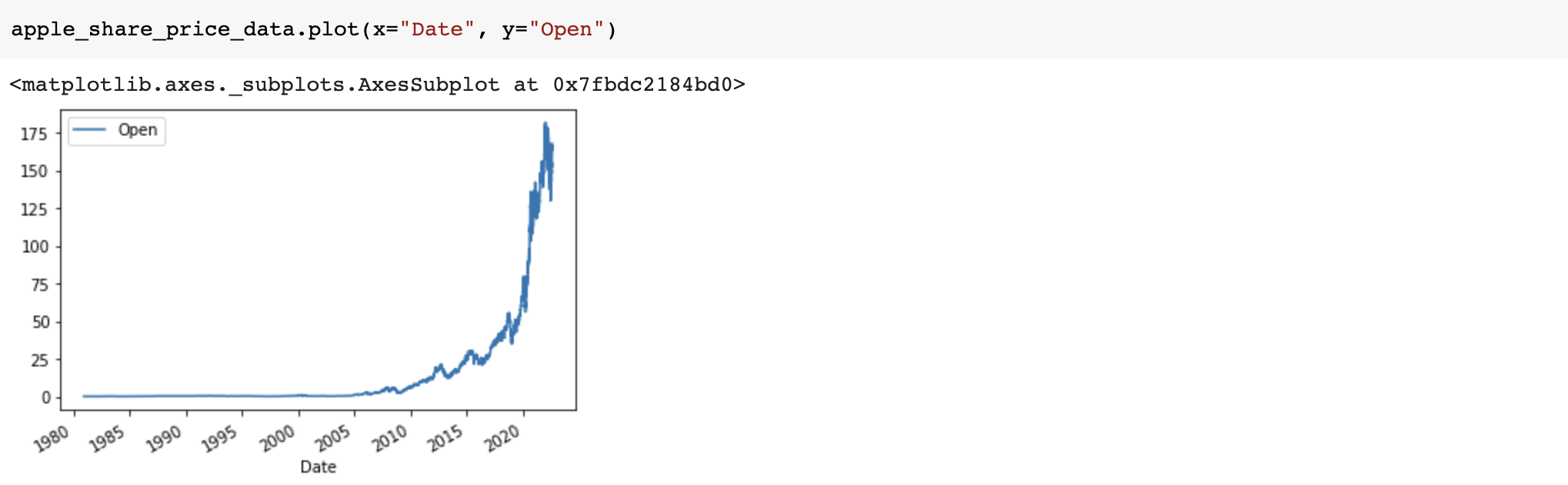
Extracting Dividends
Dividends are the distribution of a companys profits to shareholders. In this case they are defined as an amount of money returned per share an investor owns. Using the variable dividends we can get a dataframe of the data. The period of the data is given by the period defined in the 'history` function.
apple.dividends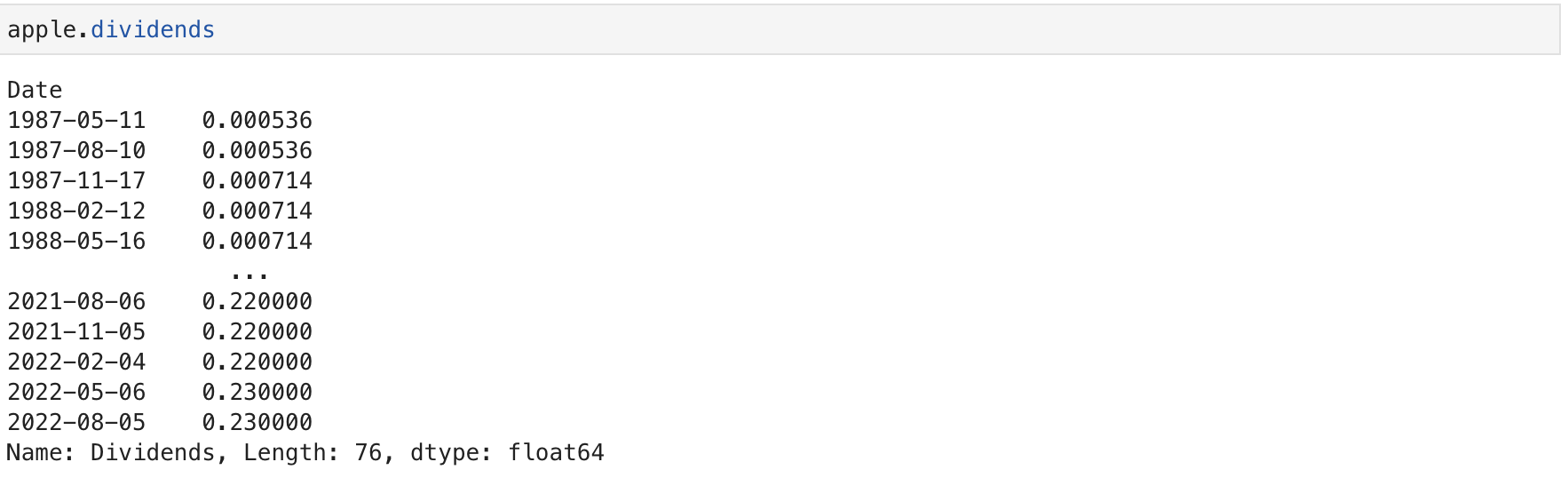
apple.dividends.plot()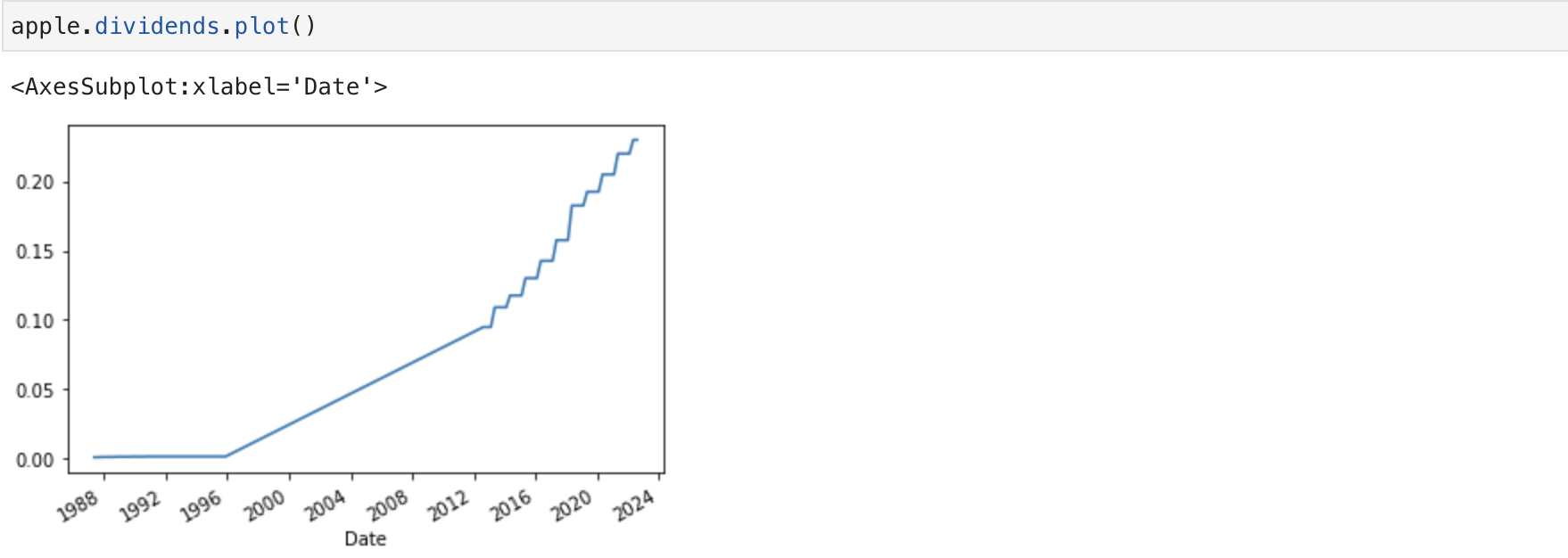
Exercise
Now using the Ticker module create an object for AMD (Advanced Micro Devices) with the ticker symbol is AMD called; name the object amd.
amd = yf.Ticker("AMD")Question 1 Use the key 'country' to find the country the stock belongs to, remember it as it will be a quiz question.
amd_info=amd.info
amd_info["country"]Question 2 Use the key 'sector' to find the sector the stock belongs to, remember it as it will be a quiz question.
amd_info["sector"]Question 3 Find the max of the Volume column of AMD using the history function, set the period to max.
amd_share_price_data = amd.history(period="max")
amd_share_price_data.max()
amd_share_price_data.head()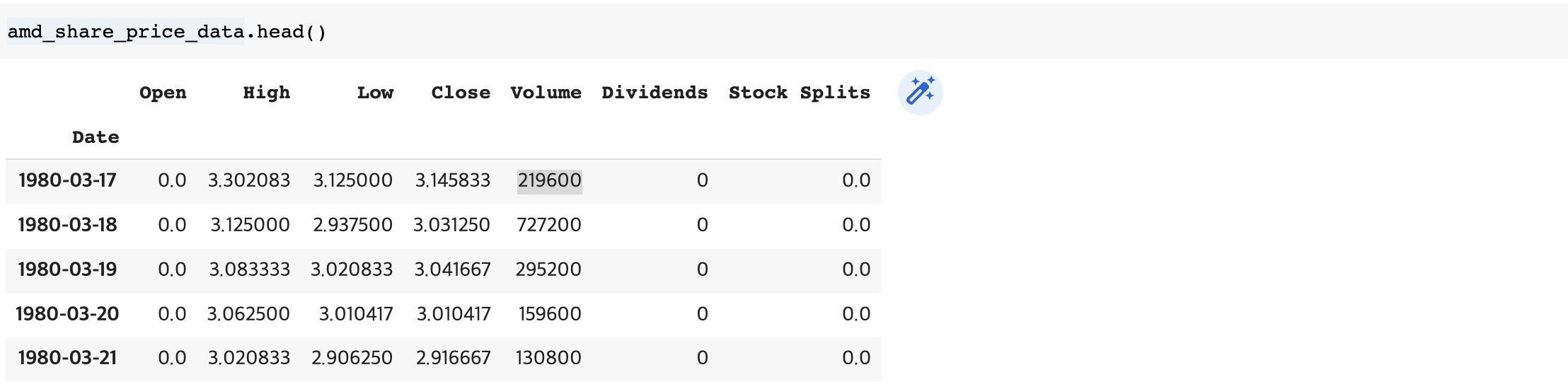
Extracting Stock Data Using a Web Scraping
#!pip install pandas==1.3.3
#!pip install requests==2.26.0
!mamba install bs4==4.10.0 -y
!mamba install html5lib==1.1 -y
!pip install lxml==4.6.4
#!pip install plotly==5.3.1import pandas as pd
import requests
from bs4 import BeautifulSoupUsing Webscraping to Extract Stock Data Example
First we must use the request library to downlaod the webpage, and extract the text. We will extract Netflix stock data https://cf-courses-data.s3.us.cloud-object-storage.appdomain.cloud/IBMDeveloperSkillsNetwork-PY0220EN-SkillsNetwork/labs/project/netflix_data_webpage.html.
url = "https://cf-courses-data.s3.us.cloud-object-storage.appdomain.cloud/IBMDeveloperSkillsNetwork-PY0220EN-SkillsNetwork/labs/project/netflix_data_webpage.html"
data = requests.get(url).textNext we must parse the text into html using beautiful_soup
soup = BeautifulSoup(data, 'html5lib')Now we can turn the html table into a pandas dataframe
netflix_data = pd.DataFrame(columns=["Date", "Open", "High", "Low", "Close", "Volume"])
# First we isolate the body of the table which contains all the information
# Then we loop through each row and find all the column values for each row
for row in soup.find("tbody").find_all('tr'):
col = row.find_all("td")
date = col[0].text
Open = col[1].text
high = col[2].text
low = col[3].text
close = col[4].text
adj_close = col[5].text
volume = col[6].text
# Finally we append the data of each row to the table
netflix_data = netflix_data.append({"Date":date, "Open":Open, "High":high, "Low":low, "Close":close, "Adj Close":adj_close, "Volume":volume}, ignore_index=True) netflix_data.head()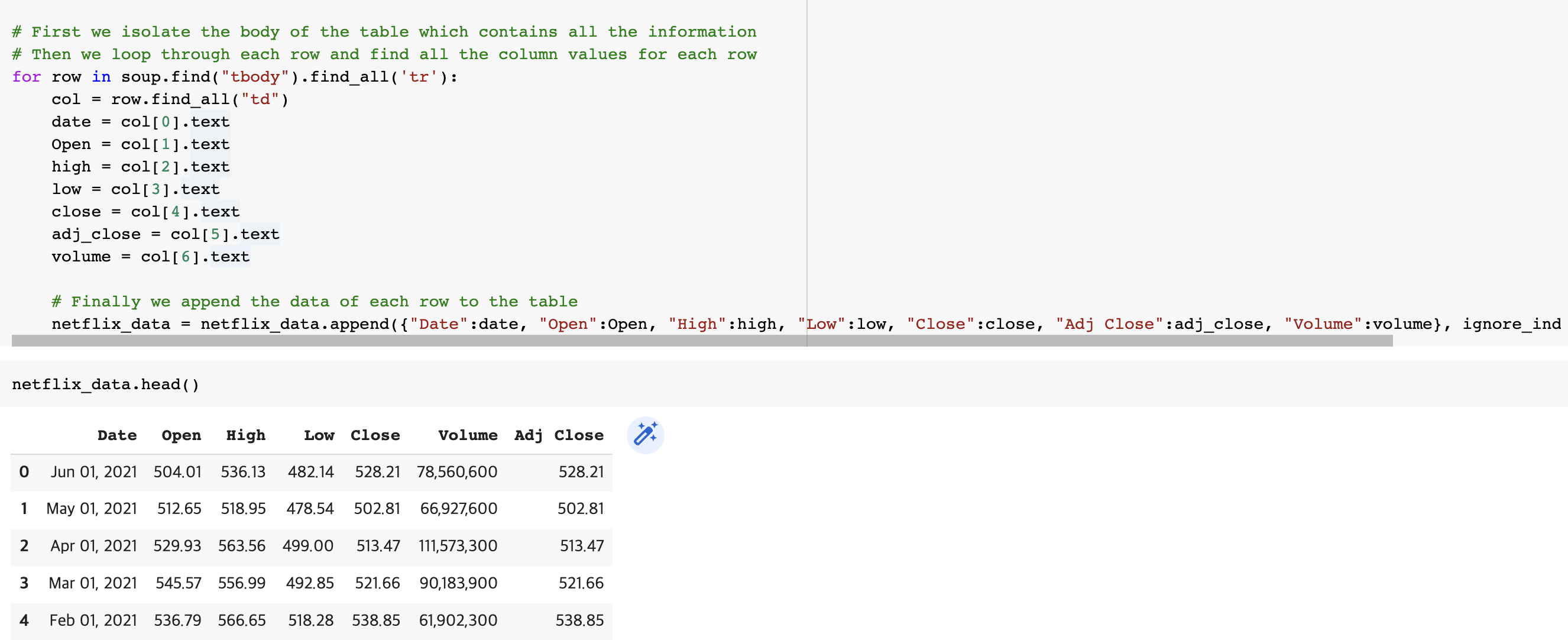
We can also use the pandas read_html function using the url
read_html_pandas_data = pd.read_html(url)Or we can convert the BeautifulSoup object to a string
read_html_pandas_data = pd.read_html(str(soup))Beacause there is only one table on the page, we just take the first table in the list returned
netflix_dataframe = read_html_pandas_data[0]
netflix_dataframe.head()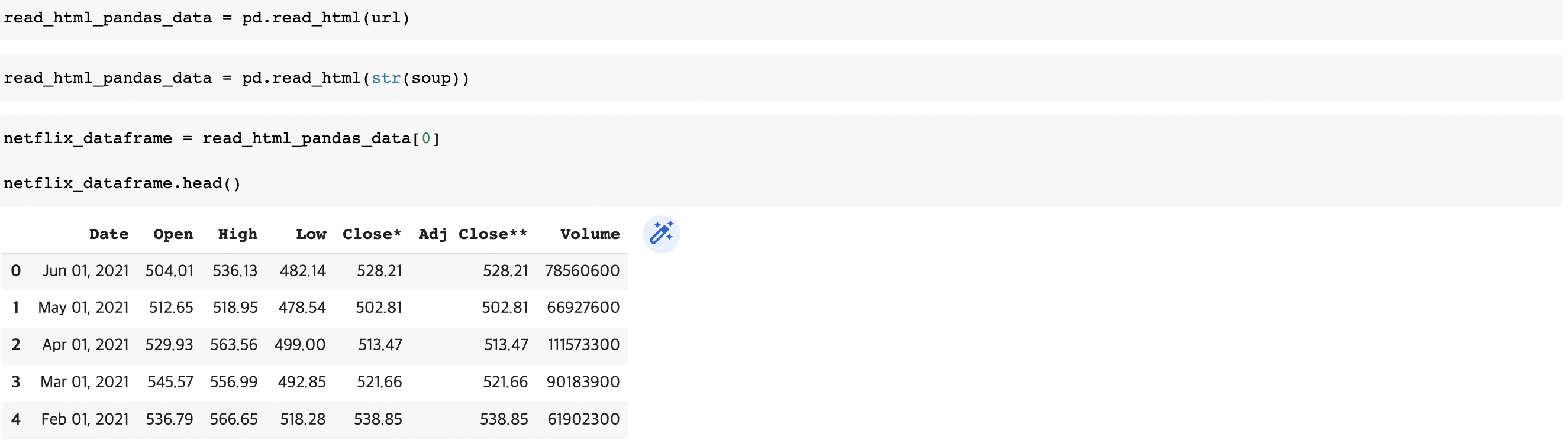
Using Webscraping to Extract Stock Data Exercise
Use the requests library to download the webpage https://cf-courses-data.s3.us.cloud-object-storage.appdomain.cloud/IBMDeveloperSkillsNetwork-PY0220EN-SkillsNetwork/labs/project/amazon_data_webpage.html. Save the text of the response as a variable named html_data.
url = "https://cf-courses-data.s3.us.cloud-object-storage.appdomain.cloud/IBMDeveloperSkillsNetwork-PY0220EN-SkillsNetwork/labs/project/amazon_data_webpage.html"
data = requests.get(url).textParse the html data using beautiful_soup.
soup = BeautifulSoup(data, 'html5lib')Question 1 What is the content of the title attribute:
print(soup.title)Using beautiful soup extract the table with historical share prices and store it into a dataframe named amazon_data. The dataframe should have columns Date, Open, High, Low, Close, Adj Close, and Volume. Fill in each variable with the correct data from the list col.
amazon_data = pd.DataFrame(columns=["Date", "Open", "High", "Low", "Close", "Volume"])
for row in soup.find("tbody").find_all("tr"):
col = row.find_all("td")
date = col[0].text
Open = col[1].text
high = col[2].text
low = col[3].text
close = col[4].text
adj_close = col[5].text
volume = col[6].text
amazon_data = amazon_data.append({"Date":date, "Open":Open, "High":high, "Low":low, "Close":close, "Adj Close":adj_close, "Volume":volume}, ignore_index=True)Print out the first five rows of the amazon_data dataframe you created.
amazon_data.head()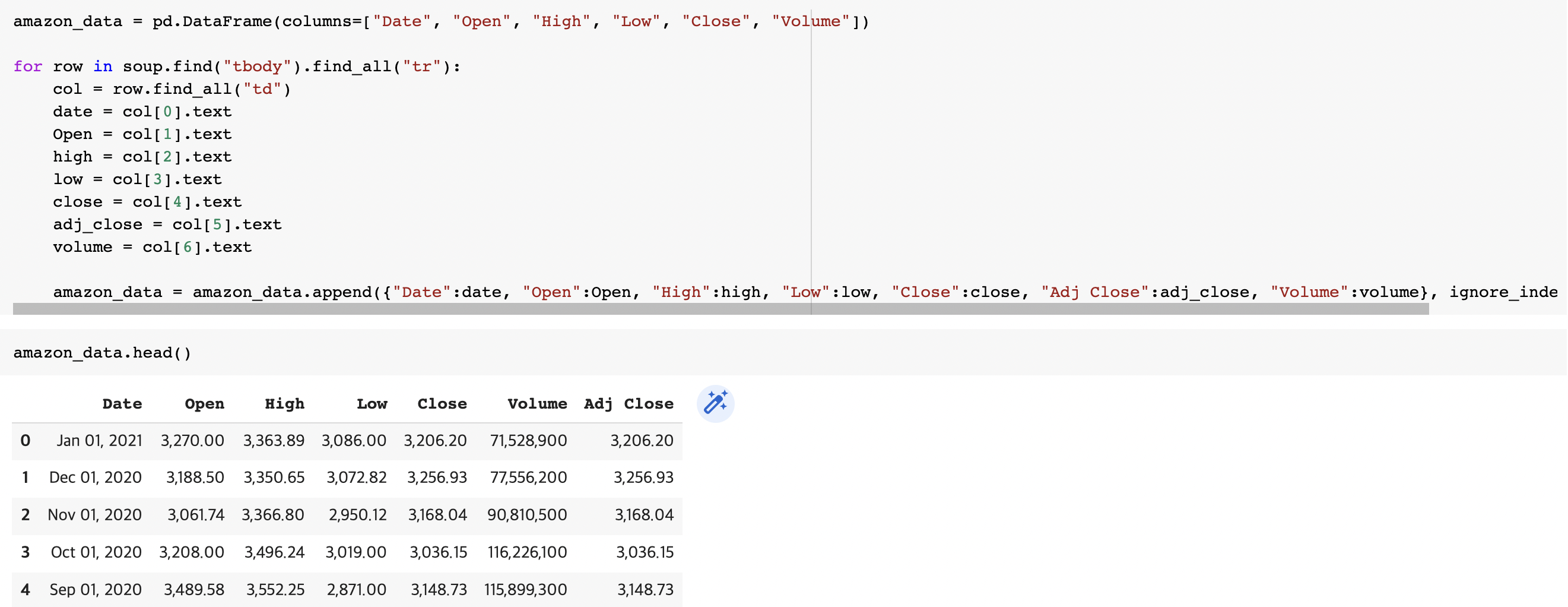
Question 2 What is the name of the columns of the dataframe
#Date, Open, High, Low, Close, Volume, Adj Close
Question 3 What is the Open of the last row of the amazon_data dataframe?
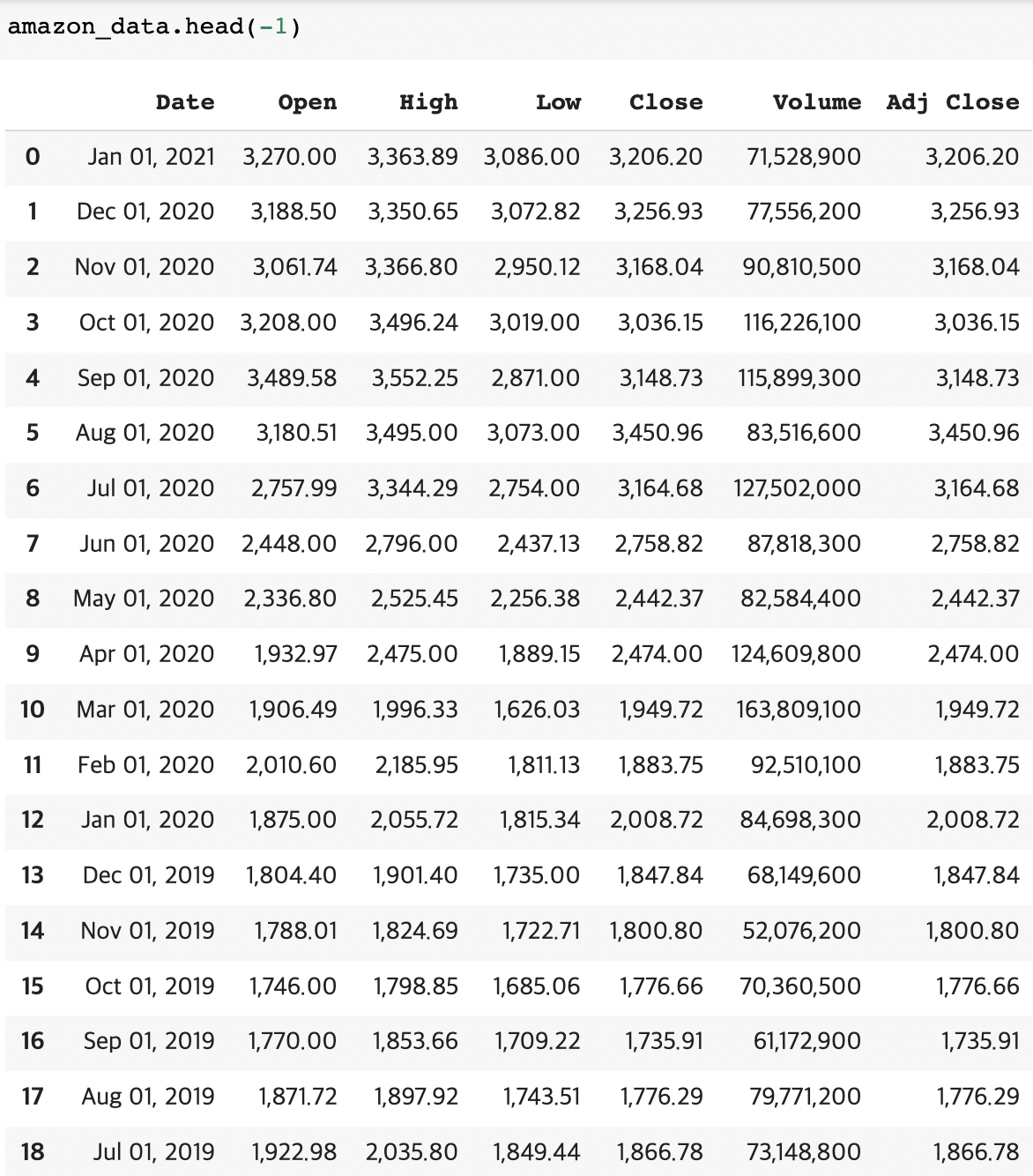

2개의 댓글

The goal of brand management, a subset of marketing, is to create and maintain positive public perceptions of a company's products and services. It involves creating brand-focused programs and procedures to aid in promoting brand awareness, recognition, and respect for the company. Hire a brand marketer right away to start expanding your company! Visit our website and explore more about professional brand marketing services!
who need help improving their coding skills c necklace , daily game solve cross