KMP 알고리즘이란?
특정한 문자열이 있을 때 그 글 안에서 하나의 문자열을 찾는 알고리즘입니다. KMP에 대해 다루기 전에 먼저 단순 비교 문자열 매칭 알고리즘에 대해 알아봅시다. 단순 비교 알고리즘은 말그래도 하나씩 확인하는 알고리즘입니다.
단순 비교 문자열 매칭 알고리즘
ABCDEF에서 DEF라는 문자열을 찾고 싶다면 다음과 같은 방식으로 찾을 수 있다.



위와 같이 매칭한 경우 정확히 매칭이 이루어진 것을 알 수 있습니다. 이러한 방식을 이용하면 O(NM)의 시간 복잡도를 가지게 됩니다. 효율적이진 않지만 매우 직관적이라고 할 수 있습니다.
KMP(Knuth-Morris-Pratt)
앞서 살펴본 단순 비교 문자열 알고리즘의 비효율적인 면을 보완하기 위해 만들어진 알고리즘이 바로 KMP알고리즘입니다. KMP 알고리즘은 접두사와 접미사의 개념을 활용하여 반복되는 연산을 얼마나 줄일 수 있는지를 판별하여 매칭할 문자열을 빠르게 점프하는 기법입니다.
일단 접두사와 접미사는 말 그대로 앞에 있는 문자열과 뒤에 있는 문자열을 의미합니다. 이때 우리가 구해야할 것은 위와 같이 접두사와 접미사가 일치하는 최대 길이 입니다.
위와 같이 접두사와 접미사를 구하게 되면 접두사와 접미사가 일치하는 경우에 한해서는 점프를 수행할 수 있다는 점에서 몹시 효율적입니다. 이제 위와 같은 접두사와 접미사의 최대 일치 길이는 어떻게 구할 수 있을지 알아봅시다.
# 접두사와 접미사의 최대 일치 길이를 나타내는 배열
table = [0] *(len(pattern))
def find_pattern_length(pattern):
#접두사 같은 느낌
j = 0
for i in range(1,len(pattern)):
while j > 0 and pattern[i] != pattern[j]:
j = table[j-1]
if pattern[i] == pattern[j]:
j += 1
table[i] = j위와 같이 접두사와 접미사를 구하게 되면 접두사와 접미사가 일치하는 경우에 한해서는 점프를 수행할 수 있다는 점에서 몹시 효율적입니다. 이제 위와 같은 접두사와 접미사의 최대 일치 길이는 어떻게 구할 수 있을지 알아봅시다.
이제 만들어진 table을 활용하여 주어진 글(word)에 해당 패턴(pattern)을 찾아봅시다.
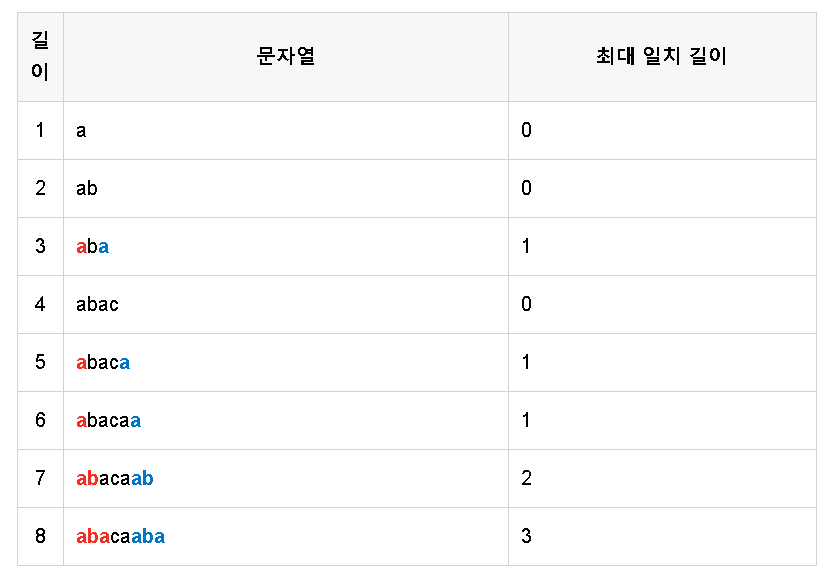
word : ababacabacaabacaaba
pattern : abacaaba
위와 같이 긴 글과 찾을 문자열이 있을 때 테이블이 구축되어있을 때 다음과 같이 찾을 수 있습니다.

먼저 긴 글과 찾을 문자열을 하나씩 비교합니다.
계속 같은 문자가 나오므로 넘어갑니다.

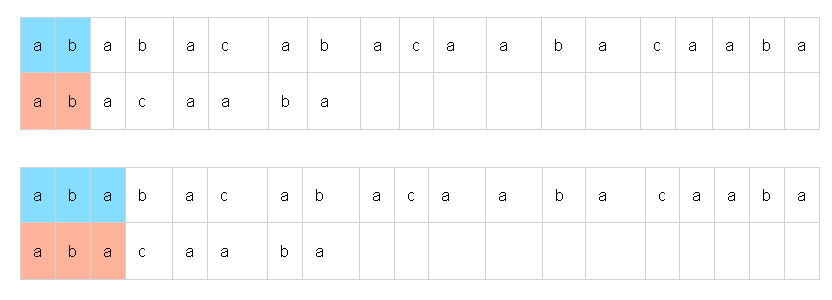
위와 같이 서로 다른 문자가 발견되면 일치하는 접두사 크기에 한해서 부분 문자열의 인덱스를 이동시킵니다.

기본적으로 ab까지는 여전히 일치하다는 점을 이용한 것입니다.

다시 위와 같이 하나씩 비교합니다. 이제 이런 식으로 일치하지 않을 때는 접두사가 일치하는 한 가장 큰 길이만큼 이동시켜나가면 됩니다. 결과적으로 계속 진행하여 다음과 같은 경우에서 끝납니다.

전체 코드는 다음과 같습니다.
#최대로 일치하는 접두사와 접미사를 구하는 함수
def find_pattern_length(pattern):
j = 0
for i in range(1, len(pattern)):
while j > 0 and pattern[i] != pattern[j]:
j = table[j-1]
# 문자열이 같을 경우
if pattern[i] == pattern[j]:
j += 1
table[i] = j
def KMP(word,pattern):
j = 0
for i in range(1,len(word)):
while j > 0 and word[i] != pattern[j]:
j = table[j-1]
if word[i] == pattern[j]:
if j == len(pattern) - 1:
print("패턴을 찾았습니다.")
j = table[j]
else:
j + =1
find_pattern_length(pattern)
KMP(word,pattern)
