트라이란?
트라이는 실무에 매우 유용하게 쓰이는 자료구조로서, 특히 자연어 처리(NLP) 분야에서 문자열 탐색을 위한 자료구조로 널리 쓰인다. 트라이는 1959년에 처음 공개됐으며, 검색을 뜻하는 'retrieval'의 중간 음절에서 용어를 따왔다.
트라이는 트리와 유사하지만, 지금까지 우리가 주로 살펴본 이진 트리의 모습이 아닌 전형적인 다진 트리의 형태를 띤다.
예를 들어 apple이란 단어를 찾는다고 가정해보자.(찾는 단어의 길이 N) 수백 개의 문자(M개) 중 apple이라는 단어를 찾는다고 한다면 엄청나게 큰 시간 복잡도 O(NM)를 가질 것이다.
하지만 트라이를 이용한다면 해당 문자열의 길이만큼만 탐색하면 된다. (시간복잡도 O(n))
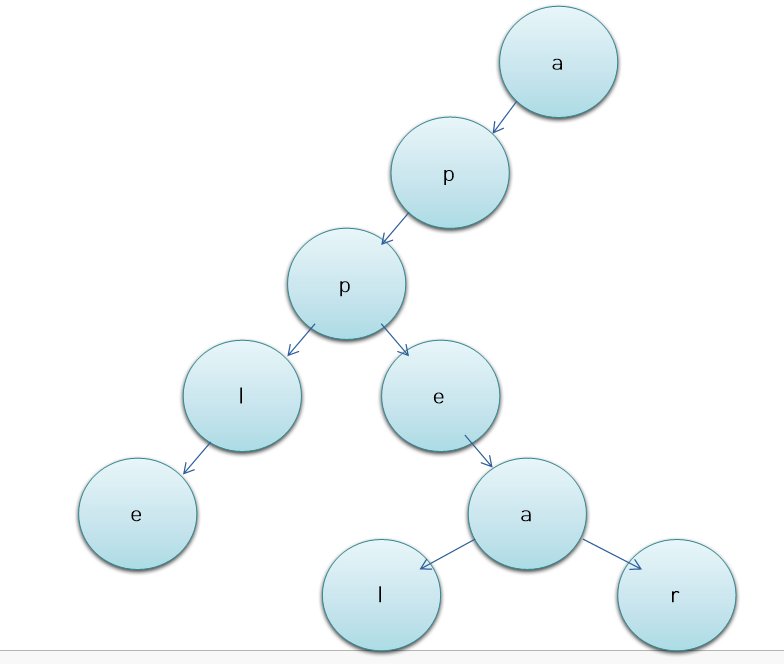
예를 들어 [apple, appear, appeal] 의 리스트에 apple이란 단어를 찾고 싶다면 루트로부터 a -> p -> p -> l -> e까지 내려가면 단어 apple을 찾을 수 있다.
트라이의 구현
- 노드 형성
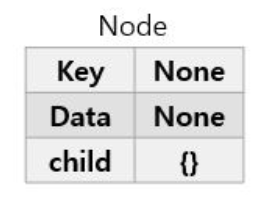
class Node(object):
def __init__(self, key, data = None):
self.key = key
self.data = data
self.children = {} 트라이를 저장할 노드는 다음과 같이 별도 클래스로 선언한다. 메서드를 포함해 같은 클래스로 묶을 수도 있지만, 이 경우 구현상 복잡도가 늘어나기 때문에 가능하면 간결하게 구현하기 위해 별도로 구분해 선언했다.
다음으로, 트라이 연산을 구현할 별도 클래스를 선언하고 삽입 메서드를 구현해보자.
- 삽입 메소드
class Trie:
def __init__(self):
self.head = Node(None)
def insert(self, word):
cur = self.head
for ch in word:
# 해당 문자열이 존재하지 않는다면
if ch not in cur.children:
# 새로운 노드 생성
cur.children[ch] = Node(ch)
# 자식 노드로 이동
cur = cur.children[ch]
# 문자열을 다 삽입하였으면 다 삽입했다는 증표인 cur.data 에 문자열을 집어넣는다.
cur.data = word
예시)
먼저, abc를 추가해보자.
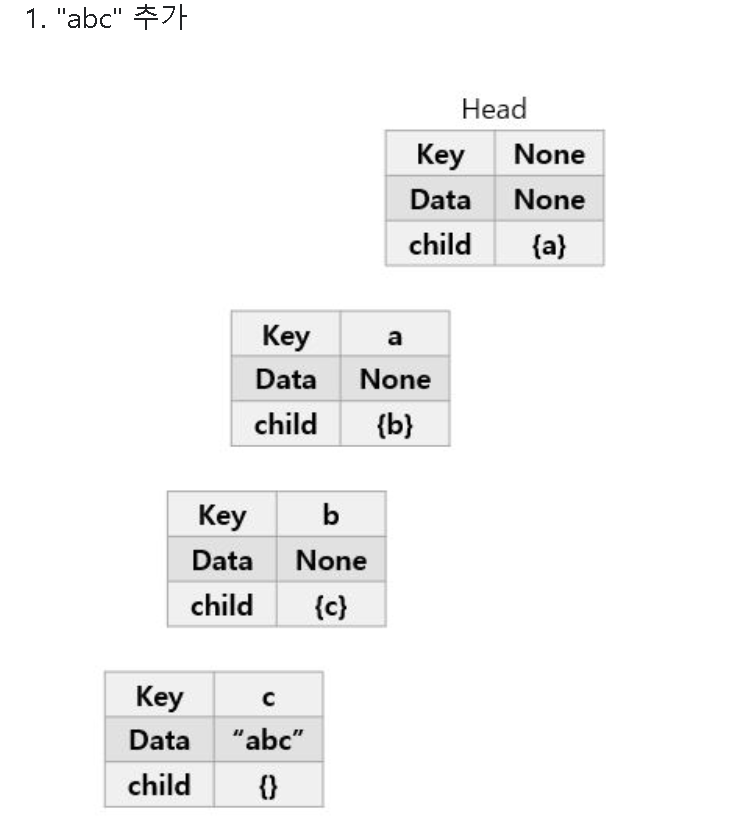
다음으로, ab를 추가해보자.
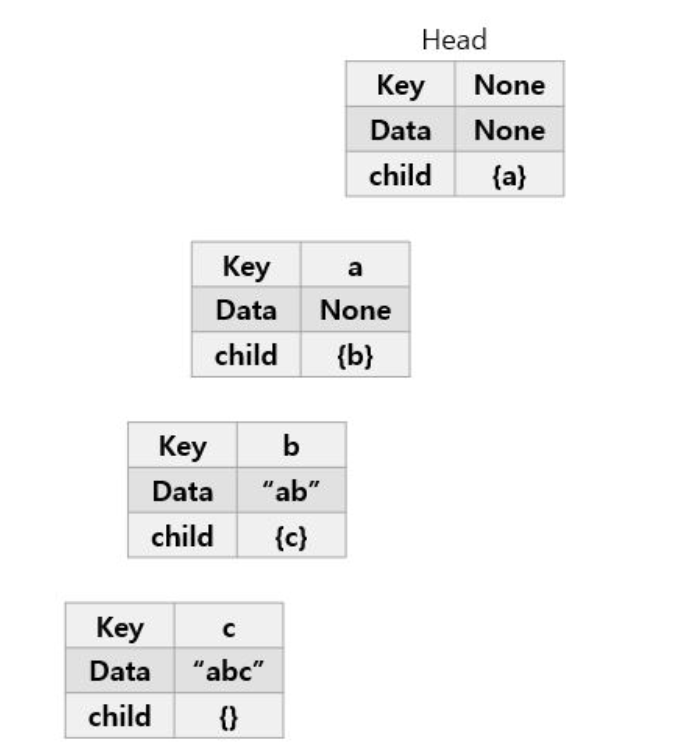
이런식으로 진행된다.
- 탐색 메서드
def search(self, word):
cur = self.head
#찾고자 하는 문자를 탐색
for ch in word:
if ch not in cur.children:
return False
cur = cur.children[ch]
# cur.data(삽입했을 때 해당 문자가 있다는 것을 표시했음)
if cur.data != None:
return False
else:
return True
다른 사람들이 이해하기 쉽게 기록하고 공유하자!!