성능 데이터 모델링
: 데이터베이스의 성능을 향상시키기 위해 설계 단계부터 성능과 관련된 사항들이 모델링에 반영될 수 있다. 성능 데이터 모델링의 방법으로 정규화, 반정규화, 테이블 통합, 테이블 분할 등이 있다.
정규화
데이터 정합성(데이터의 정확성과 일관성을 유지하고 보장)을 위해 함수 종속성을 고려하여 엔티티를 작은 단위로 분리하는 과정이다. 조회성능은 처리조건에 따라 향상되는 경우도 있고 저하되는 경우도 있지만 입력, 수정, 삭제 성능은 일반적으로 향상된다.
🔷 제1정규형
모든 속성은 반드시 하나의 값만 가져야 한다. 유사한 속성이 반복되거나 하나의 속성이 여러 개의 속성값을 갖는 데이터 모델은 제1정규화 대상이 된다.
🔷 제2정규형
엔티티의 모든 일반속성은 반드시 모든 주식별자에 종속되어야 한다.
🔷 제3정규형
주식별자가 아닌 모든 속성 간에는 서로 종속될 수 없다.
반정규화
🔶 테이블 반정규화
데이터의 조회 성능을 향상시키기 위해 데이터의 중복을 허용하거나 데이터를 그룹핑하는 과정이다. 하지만 입력, 수정, 삭제 성능은 저하될 수 있으며 데이터 정합성 이슈가 발생할 수 있으며, 데이터의 무결성을 깨뜨릴 위험성을 가지고 있다.
무결성 ❓
신뢰할 수 있는 서비스 제공을 위해서 의도하지 않은 요인에 의해 데이터, 소프트웨어, 시스템 등이 변경되거나 손상되지 않고 완전성, 정확성, 일관성을 유지함을 보장하는 특성.
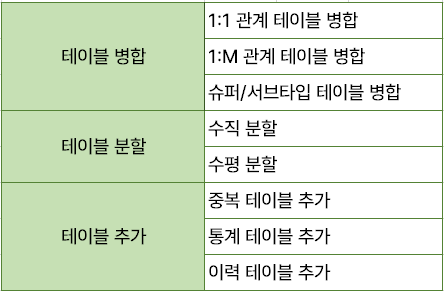
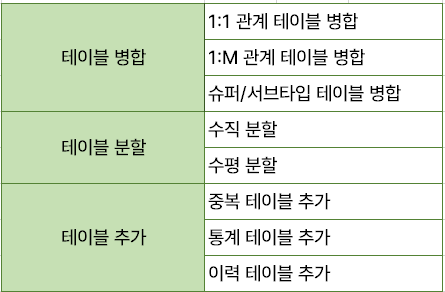
테이블 병합
테이블을 통합하는 것이 성능 측면에서 유리할 경우 고려한다.
- 1:1 관계 테이블 병합
- 1:M 관계 테이블 병합
- 슈퍼 서브 타입 테이블 병합
테이블 분할
- 테이블 수직 분할(속성 분할)
엔티티의 일부 속성을 별도의 테이블로 분리하는 것이다. 자주 사용하는 속성이 아니거나, 대부분의 인스턴스가 해당 속성값을 NULL로 갖고 있을 때 고려한다.- 테이블 수평 분할(인스턴스 분할, 파티셔닝)
엔티티의 인스턴스를 특정 기준으로 별도의 엔티티로 분할(파티셔닝)한다.
테이블 추가
- 중복 테이블 추가
- 통계 테이블 추가
- 이력 테이블 추가
- 부분 테이블 추가
🔶 컬럼 반정규화
- 중복 컬럼 추가
- 파생 컬럼 추가
- 이력 테이블 컬럼 추가
🔶 관계 반정규화 (중복 관계 추가)
업무 프로세스상 JOIN이 필요한 경우가 많아 중복 관계를 추가하는 것이 성능 측면에서 유리할 경우 고려한다. 데이터의 무결성을 깨뜨릴 위험성 없이 데이터 처리의 성능을 향상시킬 수 있다.
