정렬
정렬은 주어진 항목들을 체계적으로 정리하는 과정, 데이터를 정해진 기준에 따라 순서를 재배열하는 작업이다.
정렬은 왜 하는가?
데이터를 정렬해야 하는 이유는 탐색을 위해서이다. 사람은 수십에서 수백 개의 데이터를 다루는 데 그치지만 컴퓨터가 다뤄야 할 데이터는 보통이 백만 개 단위이며 데이터베이스 같은 경우 이론상 무한 개의 데이터를 다룰 수 있어야 한다.
탐색할 대상 데이터가 정렬되어 있지 않다면 순차 탐색 이외에 다른 알고리즘을 사용할 수 없지만 데이터가 정렬되어 있다면 이진 탐색이라는 강력한 알고리즘을 사용할 수 있다.
이진 탐색 : 컴퓨터 과학, 수학 등에서 오름차순으로 정렬된 정수의 리스트를 같은 크기의 두 부분 리스트로 나누고 필요한 부분에서만 탐색하도록 제한하여 원하는 원소를 찾는 알고리즘
정렬의 종류
1. 버블 정렬(Bubble sort) : 인접한 두 요소를 비교하여 정렬하는 방식
2. 선택 정렬(Selection Sort) : 주어진 리스트에서 가장 작은(또는 큰) 요소를 찾아서 맨 앞의 요소와 교환하는 방식
3. 삽입 정렬(Insertion Sort) : 리스트를 두 부분으로 나누고, 정렬된 부분에 새로운 요소를 삽입하는 방식
4. 병합(합병) 정렬(Merge Sort) : 분할 정복 알고리즘으로, 리스트를 반으로 나누고 각각을 정렬한 후 다시 합치는 방식
5. 퀵 정렬(Quick Sort) : 분할 정복 알고리즘으로, 피벗을 선택하여 리스트를 피벗보다 작은 요소와 큰 요소로 나누고, 재귀적으로 정렬하는 방식
6. 힙 정렬(Heap Sort) : 힙 자료구조를 이용한 정렬 알고리즘으로, 최대 힙 또는 최소 힙을 구성한 후, 힙의 루트 요소를 제거하고 정렬하는 방식
다른 정렬이 더 있지만, 비교적 간단하고 다양한 상황에서의 성능을 비교하기에 적합한 6개만 설명하겠다.
버블 정렬(Bubble sort)
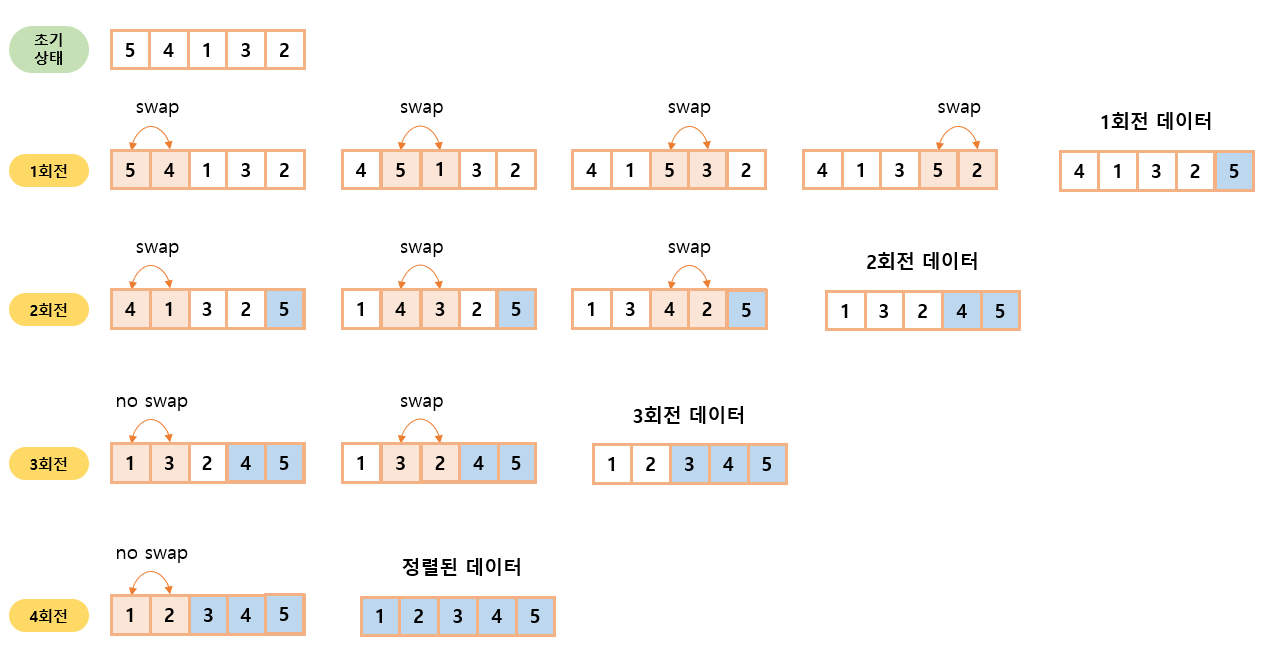
버블 정렬이란, 가장 간단한 정렬 알고리즘 중 하나로, 인접한 두 요소를 비교하여 정렬하는 방식이다. 원소를 정렬하는 모습이 마침 "버블"이 올라오는 모습같다고 해서 붙여진 이름이다. 그렇다면 어떤식으로 작동하는지 알아보자.
작동 방식
- 비교 및 교환 : 리스트의 첫 번째 요소부터 시작하여 인접한 두 요소를 비교한다. 만약 첫 번째 요소가 두 번째 요소보다 크면 두 요소의 위치를 교환한다.
- 반복: 리스트의 끝까지 이 과정을 반복한다. 이 과정을 한 번 수행하고나면 가장 큰 요소가 리스트의 마지막으로 이동하게 된다.
- 다시 시작: 리스트의 처음부터 다시 시작하여 위의 과정을 반복한다. 이 과정을 리스트가 정렬될 때까지 계속한다.
특징
구현이 간단해서 교육용으로 사용하긴 하지만 더 효율적인 데이터를 다루는 알고리즘들이 많아, 대규모 데이터 정렬에는 어울리지 않다.
구현
public static void sortByBubbleSort(int[] arr) { for (int i = 0; i < arr.length - 1; i++) { for (int j = 0; j < arr.length - i - 1; j++) { if (arr[j] > arr[j + 1]) { swap(arr, j, j + 1); } } } }
예전 영상이지만, 직접 사람들이 번호 달린 옷을 입고 연극처럼 설명해주는 유튜브인데 이해하기 더 쉽다.
알고리즘 유튜브 링크
시간 복잡도 비교
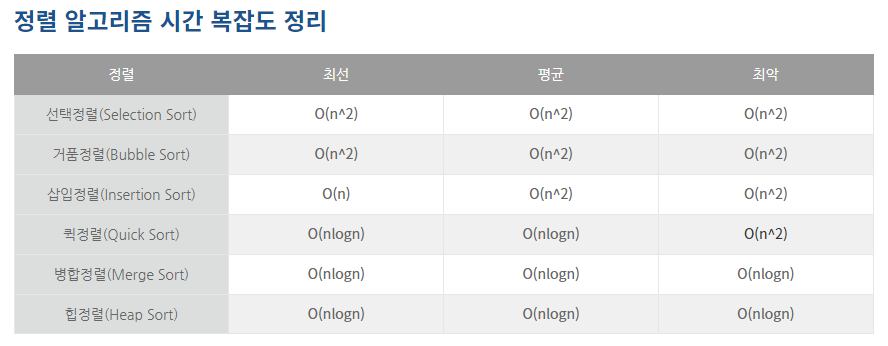
- 단순하지만 비효율적인 방법 - 삽입 정렬, 선택 정렬, 버블 정렬
- 복잡하지만 효율적인 방법 - 퀵 정렬, 힙 정렬, 병합(합병) 정렬
