이번 포스트에서는 유저들의 게임 데이터를 이용, 유저들이 많이 사용한 덱을 확인해보려고 한다.
1. 분석 목표
이번 포스트에서의 목표는 게임 경기 데이터를 이용하여 유저들이 많이 사용하는 덱을 정의하는 것이다. 덱의 정보가 없기 때문에, 경기 데이터를 기반으로 클러스터링한 후, 각 클러스터의 특징을 파악하여 클러스터마다 덱 이름을 부여할 것이다.
1) 덱?
TFT에서 해당 유저가 사용한 유닛 조합을 뜻한다. 덱을 결정짓는 다양한 요소가 존재하는데, 가장 대표적인 요소가 유닛과 특성 조합이다. 어떤 유닛을 사용할건지, 특성 중 어떤 특성을 사용해서 파워가 쌘 덱을 만들 수 있는지 생각해야 한다. 상황에 맞는 덱을 사용하면서 적절히 운영해 게임을 우승하는 것이 TFT 게임의 목표이다. 현재 8.5 시즌이 시작되었지만, 바로 직전 시즌인 8 시즌에서의 유명한 덱은 다음과 같았다.
-
세트 사미라
-
선의 소라카
-
우세 드레이븐
-
우세 유미 닐라
등... 이외에도 게임이 패치되면서 강한 덱이 약해질수도, 새로운 덱이 등장하기도 했다. 높은 티어에 있는 유저들은 직접 유닛 조합을 짜가며 최고의 덱을 찾고, 해당 덱을 유튜브나 커뮤니티에 소개하기도 한다.
그렇다면, 시즌 8에 많이 사용된 덱은 무엇일까? 이를 정의하기 위해서는 어떤 덱이 있는지 확인해야 한다. 이를 랭커들이 소개한 덱을 이용하여 분류할수도 있지만, 수집한 데이터를 바탕으로 덱을 구분해보려고 한다.
2) 클러스터링?
데이터 분석에서 사용하는 분석 기법 중 하나이다. 주어진 데이터를 바탕으로 비슷한 특징을 가지는 데이터끼리 그룹화하여 여러 개의 클러스터를 형성하는 과정이다. 이 때, 한 클러스터 내에 있는 데이터들은 서로 유사하고 비슷한 특징을 가져야 하고, 다른 클러스터에 존재하는 데이터끼리는 확실한 차이가 존재해야 한다. 우리가 예측하거나 맞추어야 할 값(response variable)이 없는 상태에서, 데이터의 특징을 파악하기 위해 사용하는 방법이다.
현재 플레이어의 게임 결과 데이터에서 해당 플레이어가 어떤 덱을 썼는지 우리는 알 수 없다. 아직 우리는 어떤 덱이 있는지 정의하지 않았으니까! 데이터를 통해 비슷한 유닛 조합, 특성 조합, 아이템 조합을 사용한 플레이어끼리 클러스터를 형성하고, 클러스터에 속한 데이터의 특징을 파악하여, 해당 덱의 컨셉을 잡을 수 있다.
3) 사용한 데이터
Riot api를 개인적으로 이용할 때는 제한 사항이 존재한다. 바로 단위 시간마다 요청할 수 있는 횟수가 제한되어 있는 것인데, 2분에 100번의 요청밖에 하지 못한다. 따라서 데이터를 수집하는 데 시간이 매우 오래 걸려, 제한된 데이터를 사용할 수밖에 없었다. 사용한 데이터는 다음과 같다.
- 1월 27일(13.1c 패치)부터 3월 14일(13.5 패치)까지의 챌린저 300명의 게임 데이터 - 약 3만 게임
이를 이용하여 챌린저들이 사용한 덱 리스트를 클러스터링하기로 했다.
2. EDA
1) Library, Data import
데이터 분석에 필요한 library와 data를 import 했다. data의 경우 이전 포스트에서 제시한 방법을 토대로 정리했다.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import torch
import seaborn as sns
import plotly.express as px
import json
import sklearn
game_summary = pd.read_csv('challanger_game_list.csv')
unit_dataframe = pd.read_csv('challanger_game_unit_list.csv')
game_summary = game_summary.drop('Unnamed: 0', axis=1)
unit_dataframe = unit_dataframe.drop('Unnamed: 0', axis=1)
game_summary 다음과 같고
unit_dataframe은 다음과 같다.
2) 사용 챔피언 데이터프레임 만들기
덱을 구성하는 가장 기초적인 요소는 챔피언이다. 어떤 챔피언을 사용했느냐에 따라 특성이 결정되고 덱이 결정되기 때문이다. 아이템 또한 덱을 결정짓는 중요한 요소 중 하나이나, 덱을 운영하는데 꼭 필요한 아이템은 드문 편이다. 하지만 해당 챔피언이 없다면 특성을 활성화할 수 없기 때문에, 챔피언을 기준으로 덱을 분류해보려고 한다.
각 플레이어마다 사용한 챔피언의 수를 entry로 가지는 데이터프레임을 만들어주었다.
game_champ_list = {i : [0]*game_summary.shape[0] for i in summary_all['champion'].keys()}
for i in range(len(game_summary['units'])):
units = eval(game_summary['units'][i])
for unit in units:
game_champ_list[unit][i] +=1
game_champ_list = pd.DataFrame(game_champ_list)
# 해당 데이터프레임에서 필요없는 column 제거 : 황금 알, 용병 상자, 증강 보관소, '거대 대게 우르곳', '해커림', '화산 솔', '돌연변이 자크'
game_champ_list = game_champ_list.drop(['황금 알', '용병 상자',
'증강 보관소', '거대 대게 우르곳', '해커림', '화산 솔', '돌연변이 자크', '훈련 봇'], axis=1)
game_champ_list
3) 데이터프레임 EDA
(1) 요약 통계량
game_champ_list의 column별 요약 통계량은 다음과 같다.
game_champ_list.describe()
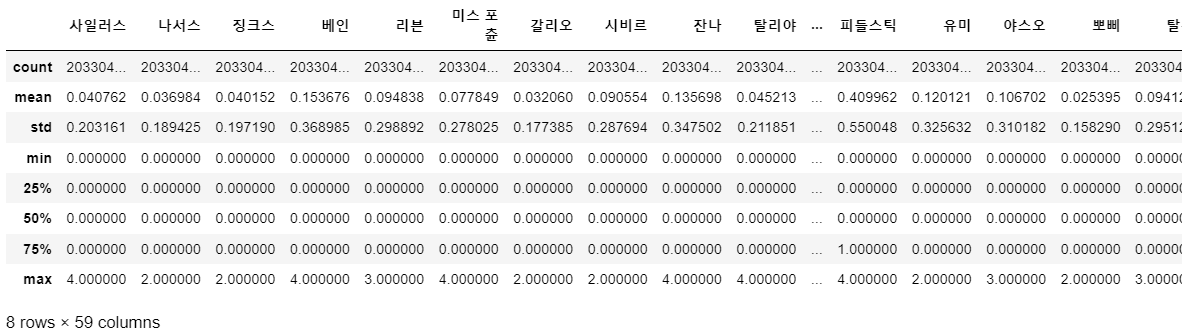
보이는 것과 같이 대부분의 column에 0이 대부분을 차지한다. 즉, sparse 데이터이다. 한 플레이어가 사용할 수 있는 챔피언의 수가 제한되어 있기 때문에(기본 9레벨에 9명, 전략가의 왕관이나 증강체, 특수한 경우에 1~4명 추가되기도 한다.) 따라서 대부분의 entry 값이 0이다. 또한, 대부분의 column의 최댓값이 4이다. 즉 0에서 4의 값을 가지는 범주형 데이터로도 생각할 수 있다. 다만, 사용한 유닛 수이므로, count data로도 생각해볼 수 있다.
이로 인해 해석을 진행할 때 조심해야 하는 경우가 있다. 바로 상관계수 분석이다.
(2) 상관관계 분석
현재 entry 값은 해당 플레이어가 특정 챔피언을 사용한 수이므로, count data이다.
column간 상관계수를 파악하여 같이 사용한 챔피언을 확인할 수 있다.
check_cor = game_champ_list.corr(method = 'pearson')
check_cor
이 중 상관계수가 높은 순서대로 나열해보았다.
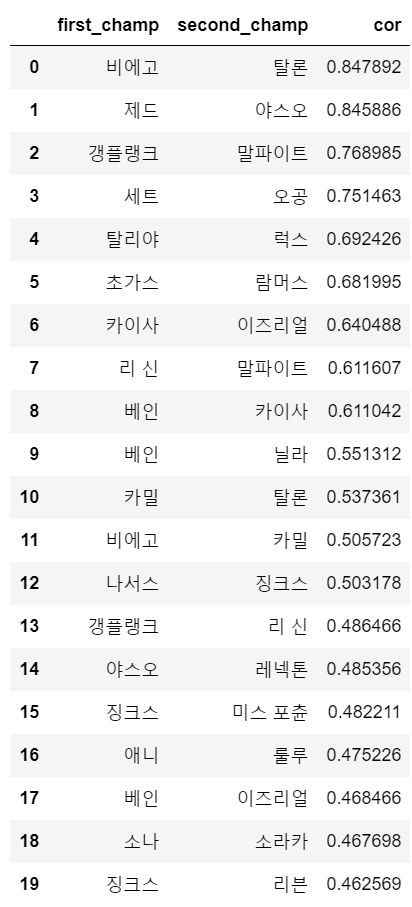
높은 값을 가지는 챔피언의 조합을 보면 납득이 가는 조합이다.
-
비에고, 탈론 : 무법자와 황소부대 시너지, 황소부대 무법자 비에고 덱에 사용되는 유닛
-
제드, 야스오 : 레이저단과 결투가 시너지, 결투가 제드 or 레이저단 제드 덱에 사용되는 유닛
-
갱플랭크, 말파이트 : 우세 시너지. 우세 기반 리롤 덱에 사용되는 유닛
그럼 상관계수가 낮은 값은 어떨까?
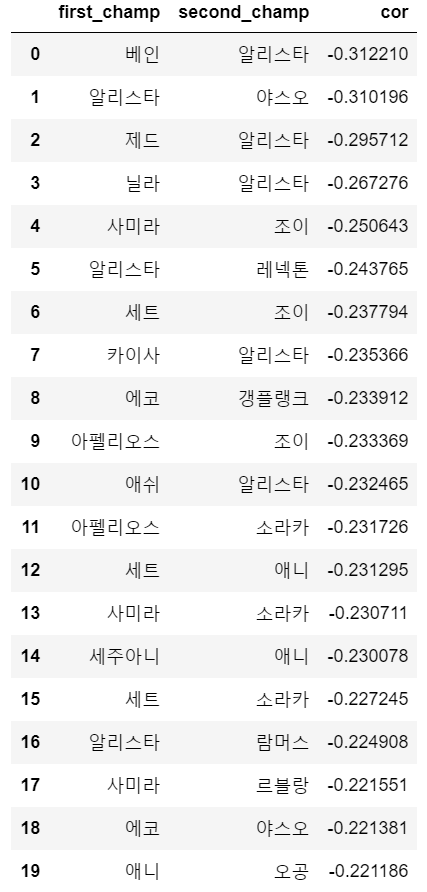
같이 사용되지 않는 유닛 조합이 나왔다.
-
베인 알리스타 : 결투가, 동물특공대, 정찰단 시너지인 베인과, 황소부대, 마스코트, 방패대 알리스타 간 겹치는 시너지가 없다. 또한, 베인이 주로 사용되는 결투가 덱과 동물특공대 덱에 알리스타가 사용되는 경우가 적다.
-
알리스타, 야스오 : 황소부대, 마스코트, 방패대 알리스타와 결투가, 레이저단 야스오 간 겹치는 시너지가 없다. 또한, 야스오가 주로 사용되는 결투가 덱과 동물특공대 덱에 알리스타가 사용되는 경우가 적다.
이처럼, 결과를 보면 어느 정도 납득이 되는 결과임을 알 수 있다. 다만, 상관계수가 음수인 경우, 상관계수의 절댓값이 상대적으로 낮은 것을 알 수 있다. 해당 이유가 무엇인지 알아보기 위해 두 챔피언간 사용 수로 분할표를 만들어보았다.
(3) 분할표 확인
상관관계 분석 부분에서는 entry값을 count 또는 연속형 데이터의 관점에서 바라보았다면, 분할표의 경우 entry 값을 0, 1, 2, 3, 4인 범주(또는 순서)형 데이터의 관점에서 바라보았다.
먼저 두 챔피언을 선택하면 분할표를 만들어주는 함수를 만들었다.
def make_contingency_table(dataframe, champion1, champion2):
result = pd.crosstab(dataframe[champion1], dataframe[champion2])
return result
- 상관계수가 높았던 두 챔피언
상관계수가 높았던 두 챔피언인 비에고, 탈론의 분할표를 확인했다.
make_contingency_table(game_champ_list, '비에고', '탈론')
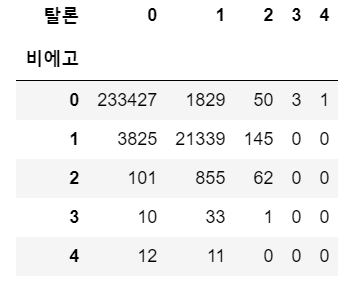
결과를 보면 알겠지만 두 챔피언은 동시에 사용되거나, 동시에 사용되지 않는 경우가 압도적으로 많았고, 그 결과 상관계수가 큰 값으로 나왔다. 범주형 또는 순서형 데이터에서 사용할 수 있는 상관관계 지표인 Cramer's V 지표 또한 확인해보았다.
def make_cramer_v(df, champion1, champion2):
dataframe = make_contingency_table(df, champion1, champion2)
x2 = stats.chi2_contingency(dataframe, correction=False)[0]
N = np.sum(np.sum(dataframe))
minimum_dimension = min(dataframe.shape)-1
return(np.sqrt(x2/N)/minimum_dimension)
make_cramer_v(game_champ_list, '비에고', '탈론')cramer_v 값은 0.22가 나왔다. 생각보다 작은 값이다. 음의 상관관계를 가졌던 베인과 알리스타는 0.11값이 나왔다. 챔피언간 cramer_v값을 모두 계산해주고, 큰 순으로 나열해주었다.
check_cramer_v = []
for i in range(correlation_df.shape[0]):
first_champ = correlation_df.first_champ[i]
second_champ = correlation_df.second_champ[i]
check_cramer_v.append(make_cramer_v(game_champ_list, first_champ, second_champ))
correlation_df['cramer_v'] = check_cramer_v
correlation_df.sort_values('cramer_v', ascending=False)
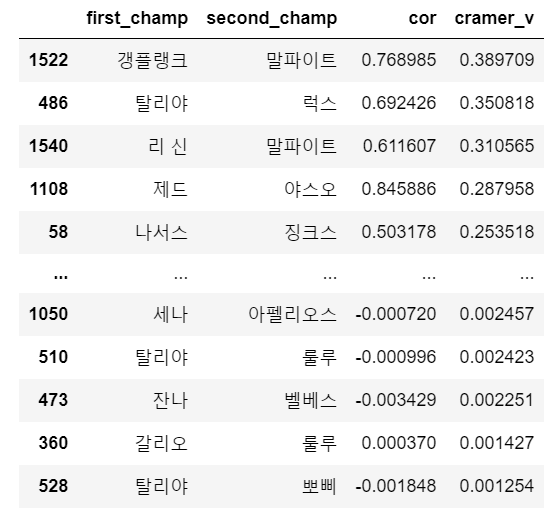
그런데 cramer_v값은 범주형 변수가 nominal일 때 사용한다. 따라서 ordinal 변수일 때 사용할 수 있는 Kendall 값을 계산하고, 크기 순으로 나열해주었다.
check_kendall = []
for i in range(correlation_df.shape[0]):
first_champ = correlation_df.first_champ[i]
second_champ = correlation_df.second_champ[i]
check_kendall.append(make_kendall(game_champ_list, first_champ, second_champ))
correlation_df['kendall'] = check_kendall
correlation_df.sort_values('kendall', ascending=False)
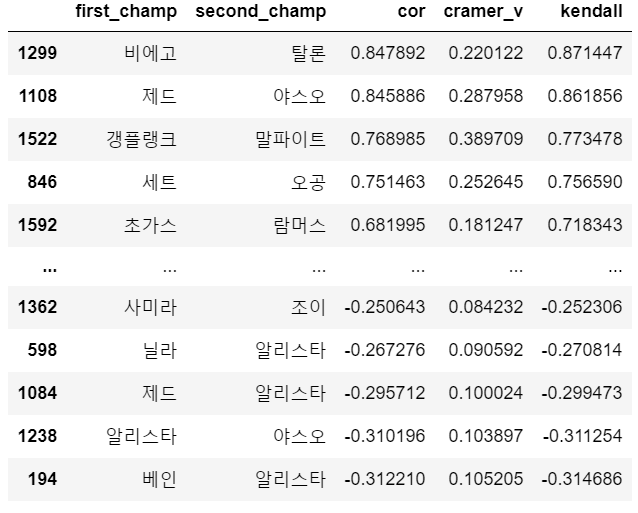
Kendall 값은 correlation이랑 비슷한 경향을 가지는 것을 확인할 수 있다.
Kendall 값이 0 근방인 챔피언 조합은 다음과 같다.
correlation_df.sort_values('kendall', key= lambda x : abs(x))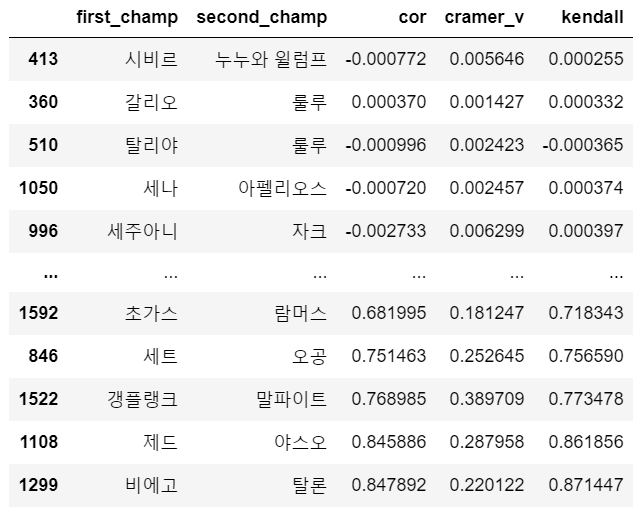
시비르와 누누와 윌럼프 간 분할표를 생성하면 다음과 같다.
make_contingency_table(game_champ_list, '시비르', '누누와 윌럼프')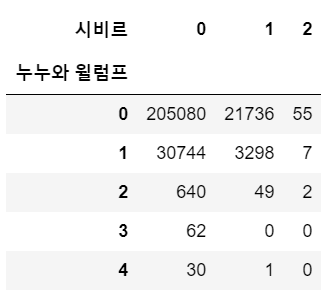
두 챔프가 동시에 사용 안된 경우가 다른 경우보다 압도적으로 많다. 따라서 두 챔프 중 한 챔프를 사용한 경우가 동시에 사용한 경우보다 많더라도 음의 값을 가지지 않는다.
마지막으로 Kendall 의 분포는 다음과 같다.
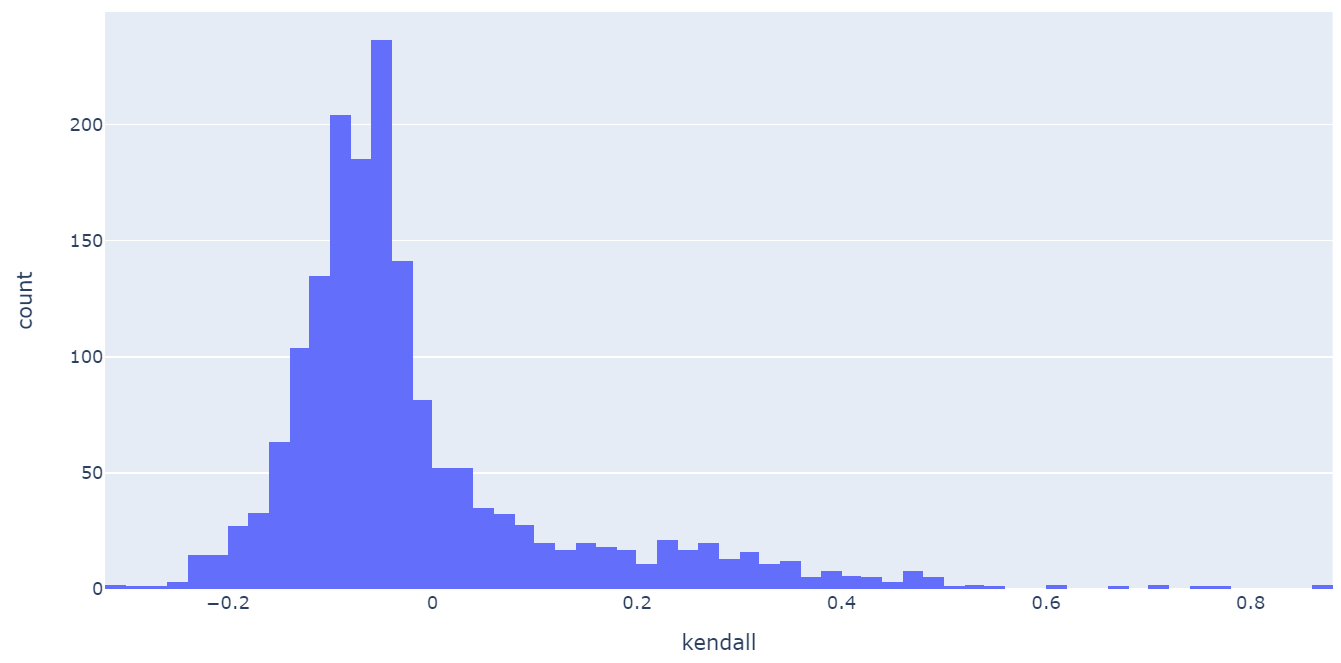
또한 Kendall 를 이용하여 heatmap을 만들면 다음과 같이 만들 수 있다.
heatmap_df = pd.DataFrame({i : [0]*len(game_champ_list.columns) for i in game_champ_list.columns})
heatmap_df.index = game_champ_list.columns
for i in range(heatmap_df.shape[0]):
for j in range(heatmap_df.shape[1]):
first_champ = heatmap_df.index[i]
second_champ = heatmap_df.columns[j]
kendall = make_kendall(game_champ_list, first_champ, second_champ)
heatmap_df.iloc[i, j] = kendall
px.imshow(heatmap_df, color_continuous_scale = 'RdBu')
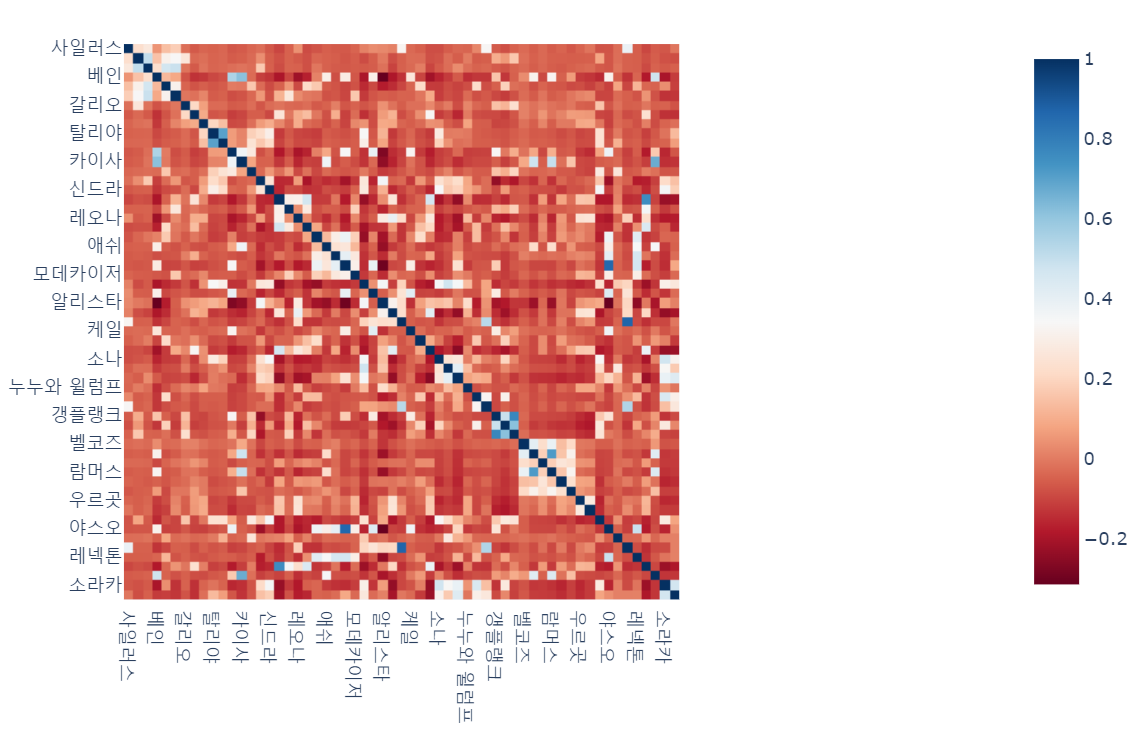
푸른색 계열을 가지는 entry의 뜻은 해당 entry에 해당하는 두 챔피언이 동시에 사용되었다는 뜻이다. 대부분의 값이 0 근방에 존재하는데, 이는 대부분 데이터가 0의 값을 가지기 때문이다. 두 챔피언 중 한 챔피언만 사용된 경우가 많더라도, 그보다 두 챔피언이 동시에 사용되지 않은 경우가 많기 때문이다.
(4) 정리
EDA를 통해 다음의 정보를 얻었다.
① 현재 dataframe에는 0이 많은 sparse 데이터셋이다.
② 그로 인해 상관관계 분석시 두 챔피언이 같이 쓰인 정보만 확실히 확인할 수 있다.
③ 즉 여러 챔피언에 대한 관계, 두 챔피언 중 한 챔피언만 쓰인 경우는 정확하게 확인할 수 없다.
④ Column의 개수가 59개로 많은 편이다.
본격적인 클러스터링을 진행하기 전, sparse data 문제와 high-dimension 문제를 먼저 해결해야 한다.
다음 포스트에서 sparse data와 high dimensional data 처리 및 클러스터링을 포스트할 예정이다.
