지난 포스트에서 riot api를 통해 데이터를 추출해보았다.
이번 포스트에서는 Data Dragon과 이를 이용하여 유닛, 증강체, 아이템 한글 변환 방법에 대해 정리했다.
1. 추출된 데이터
지난 포스트에서 추출한 데이터는 다음과 같았다.
Game id를 입력하여 해당 게임 정보를 추출했고, 첫번째 데이터프레임의 participants를 데이터프레임으로 만들어주었다. 여기서 각 참여 유저별 특성과 유닛 데이터프레임은 다음과 같다.
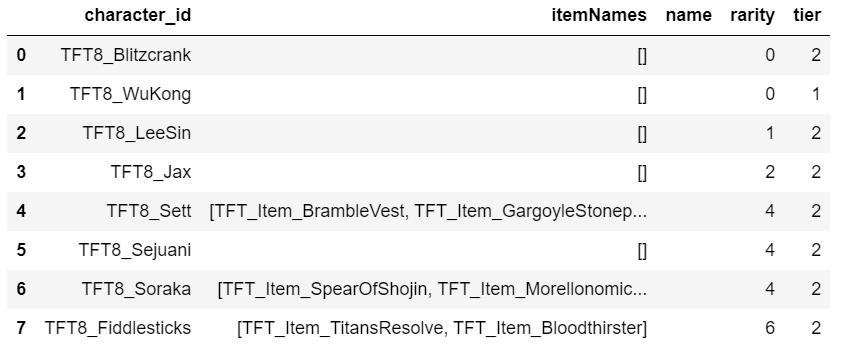
2. 영어를 한글로 변환하기
첫번째로 할 작업은 영어로된 증강체, 유닛, 아이템을 한글로 바꿔주는 작업이다. 이를 진행하기 위해서는 다음 사이트에서 게임 데이터 파일을 다운 받아야 한다.
최신 패치 폴더(현 시점 기준 13.5이다.) - cdragon - tft - ko_kr.json 파일을 다운 받으면 된다.
해당 파일을 python에 불러오자
import json
file_path = './item_data.json'
with open(file_path, 'r') as json_file:
data_dragon = json.load(json_file)
data_dragon의 keys는 3가지로 구성되어 있다.
- items : 전체 시즌에 사용된 아이템, 증강체 정보 데이터, apiName, 효과, 조합아이템 유무, 아이콘, id, 한글 이름, unique 여부로 구성되어 있다.
items = pd.DataFrame(data_dragon['items'])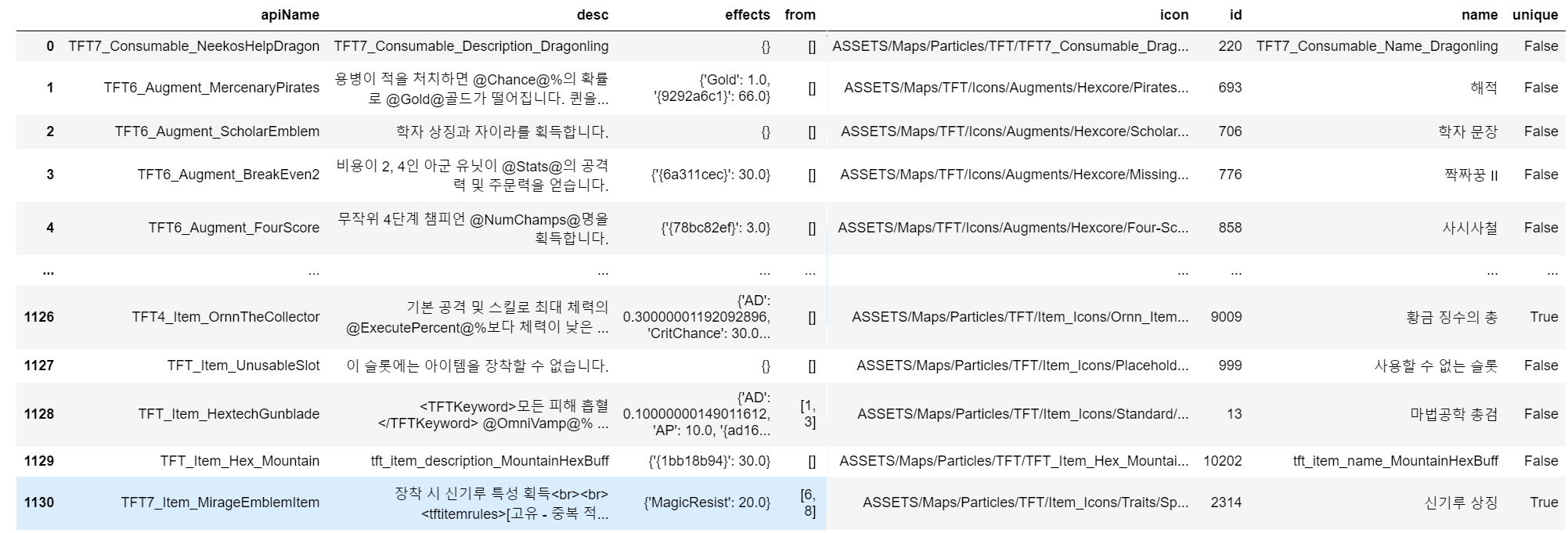
- setData : 시즌별 유닛 정보 데이터이다. mutator를 통해 원하는 시즌을 선택하면 된다. 현재 시즌 8이므로 TFTSet8 데이터를 살펴보면 된다.
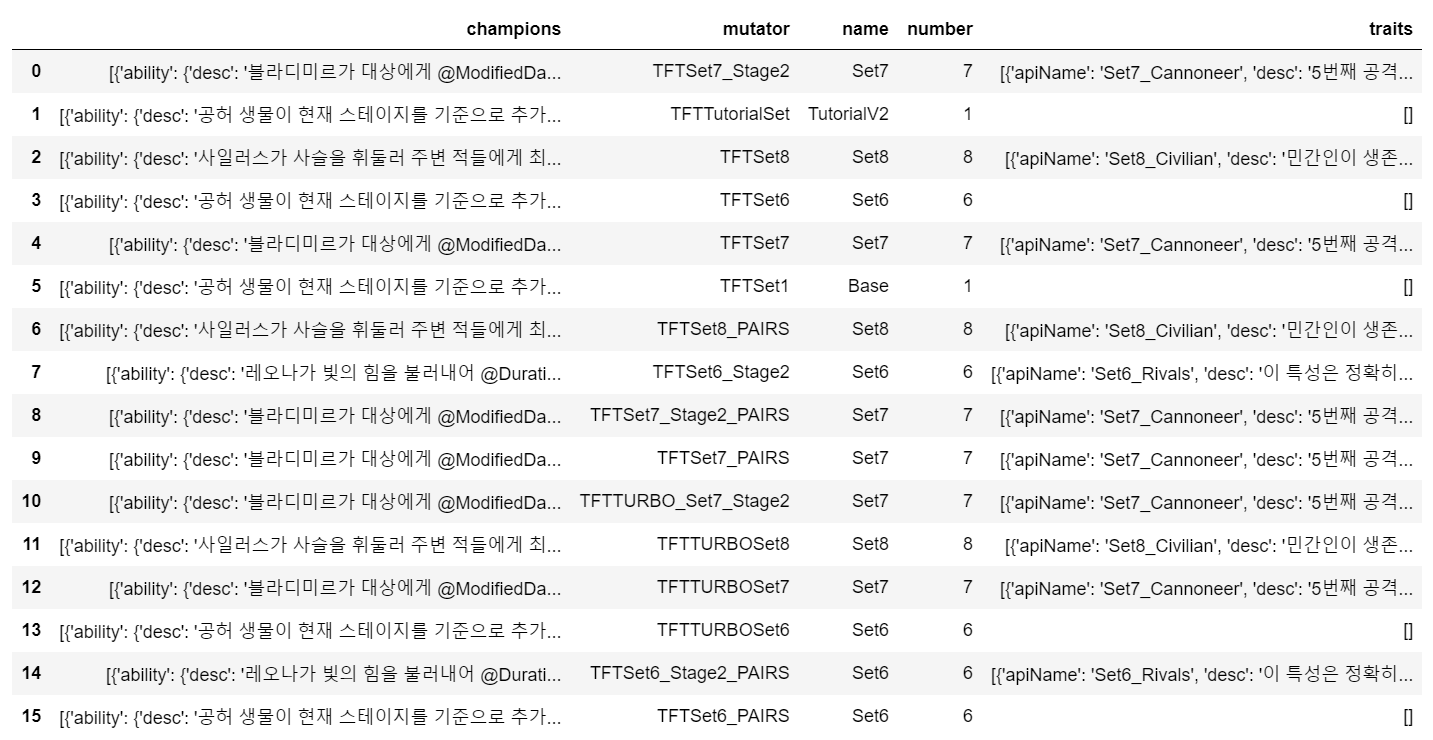
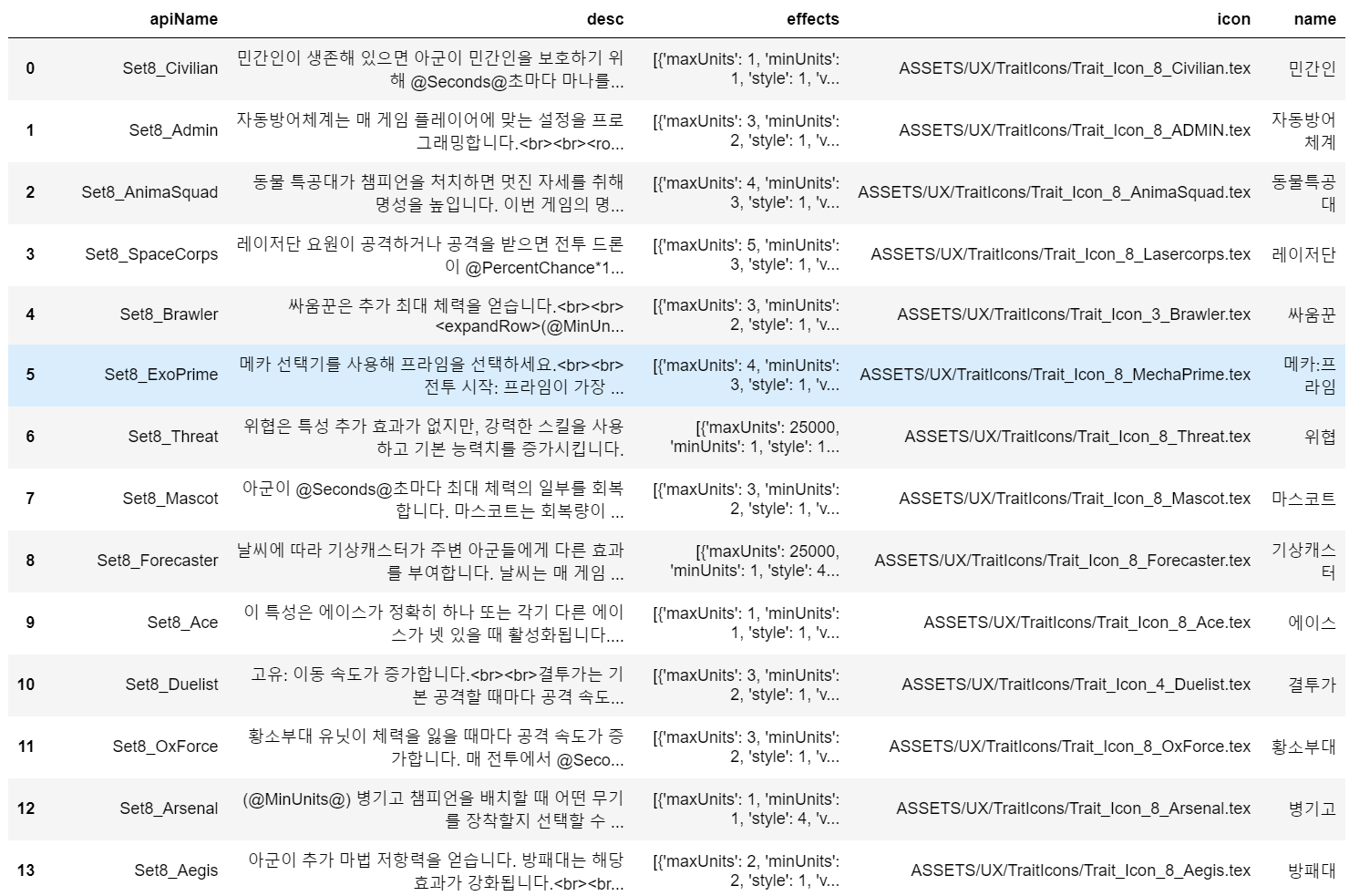
- sets : 최근 시즌 특성, 유닛 정보 데이터이다. name이 set8인 부분을 확인하면 된다.
game_set = pd.DataFrame(data_dragon['sets'])
season8_trait = pd.DataFrame(pd.DataFrame(data_dragon['sets']).loc['traits', '8'])
season8_champ =
pd.DataFrame(pd.DataFrame(data_dragon['sets']).loc['champions', '8'])

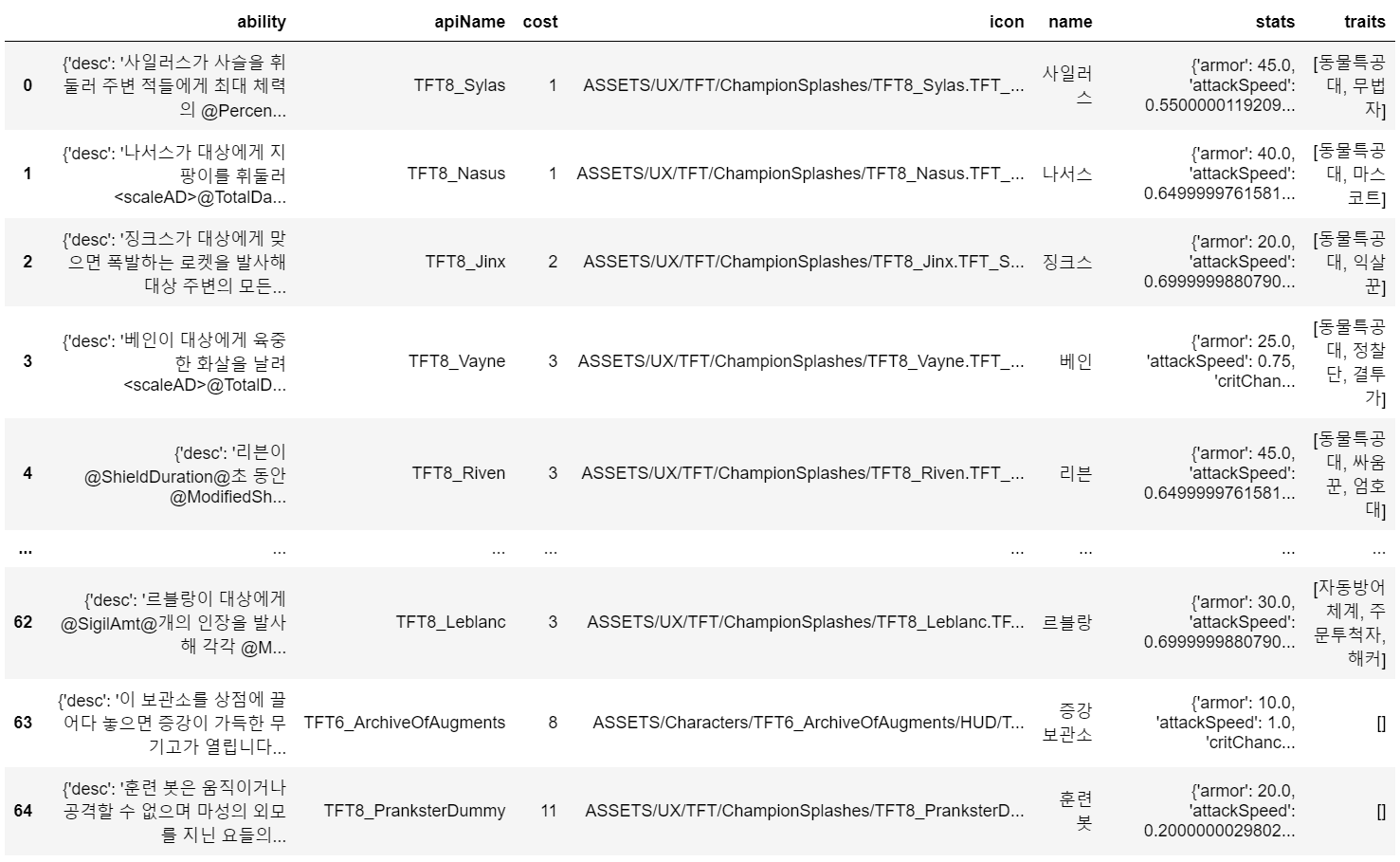
3개의 key 중 우리는 items, sets에 해당하는 데이터를 사용하면 된다. 코드에서는 items(아이템, 증강체 정보), season8_trait(특성 정보), season8_champ(유닛 정보)로 지정해주었다.
경기 데이터에서 사용하는 증강체이름, 유닛 이름, 아이템 이름은 모두 apiName에 해당한다. 따라서 각각의 apiName에 해당하는 한글 이름을 찾은 후, 변환해주면 된다.
# apiName과 name을 짝지어놓은 dictionary
item_aug_list = {items.loc[i, 'apiName'] : items.loc[i, 'name'] for i in range(items.shape[0])}
trait_list = {season8_trait.loc[i, 'apiName'] : season8_trait.loc[i, 'name'] for i in range(season8_trait.shape[0])}
champ_list = {season8_champ.loc[i, 'apiName'] : season8_champ.loc[i, 'name'] for i in range(season8_champ.shape[0])}
# 증강체 변환 함수
def change_augments(dataframe, augments_list):
result = []
for i in range(dataframe.shape[0]):
check = dataframe.loc[i, 'augments']
change_aug = []
for j in check:
change_aug.append(augments_list[j])
result.append(change_aug)
dataframe['augments'] = result
return dataframe
# 특성 변환 함수
def change_traits(dataframe, trait_list):
result = []
for i in range(dataframe.shape[0]):
check = dataframe.loc[i, 'name']
result.append(trait_list[check])
dataframe['name'] = result
return dataframe
# 아이템, champion 이름 변환 함수
def change_champ_item(dataframe, champ_list, item_list):
result_champ = []
result_item = []
for i in range(dataframe.shape[0]):
check_champ = dataframe.loc[i, 'character_id']
result_champ.append(champ_list[check_champ])
check_item = dataframe.loc[i, 'itemNames']
check_item += ['None']*(3-len(check_item))
item_per_unit = []
for j in check_item:
if j=='None':
item_per_unit.append(j)
else:
item_per_unit.append(item_list[j])
result_item.append(item_per_unit)
dataframe['character_id'] = result_champ
dataframe['itemNames'] = result_item
return dataframe
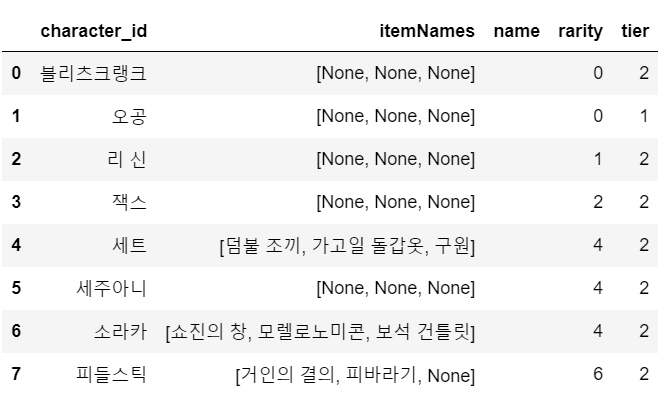
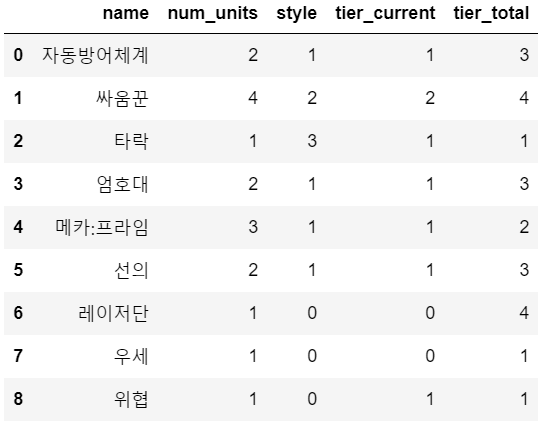
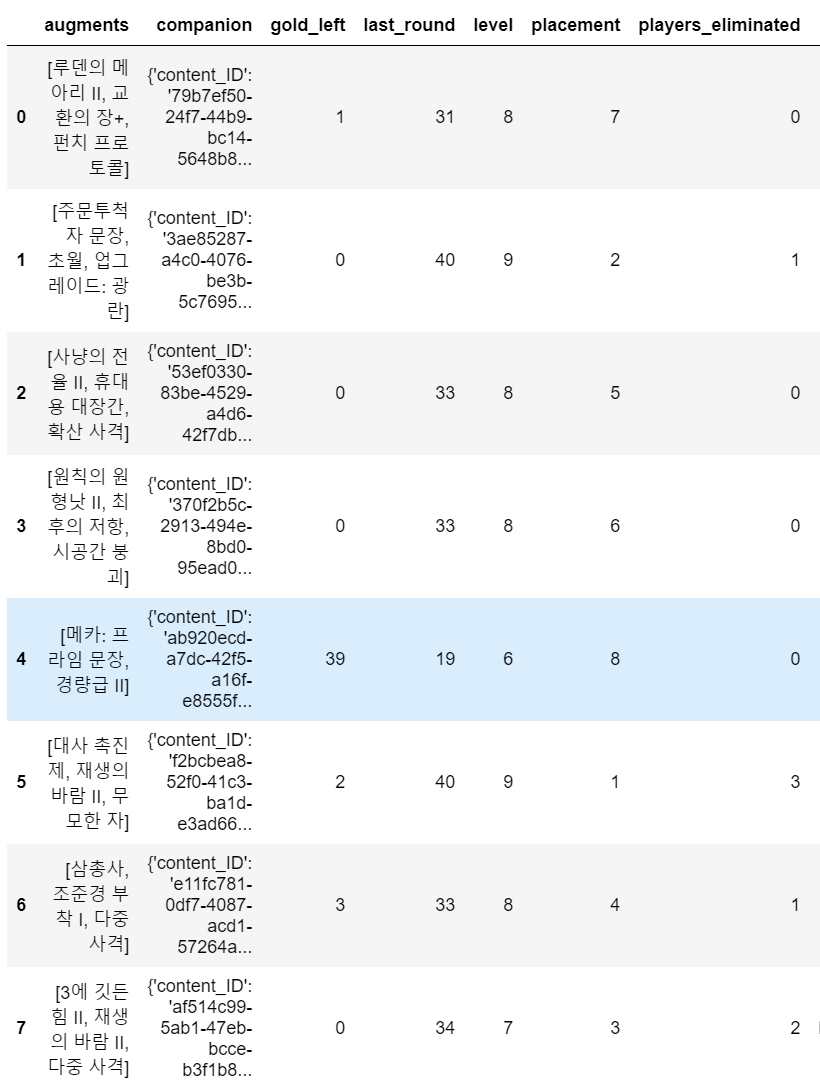
짠! 다음과 같이 변경된 것을 알 수 있다.
다음 포스트에서는 계속해서 데이터프레임을 정리할 것이다.

데이터 분석가 새싹