6. Training Nearual Netwarks, part 1
✔ Activation Function
1. Sigmoid
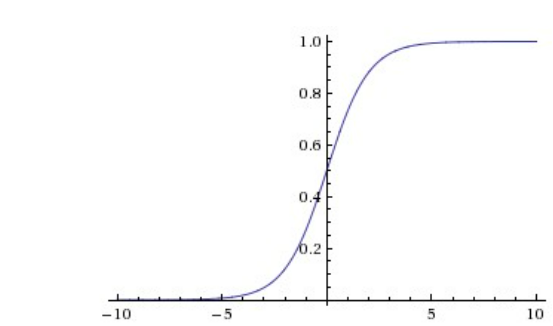
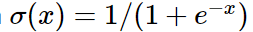
Sigmoid 함수는 모든 수를 [0,1] 사이의 수로 squash 한다. 가장 간단한 activation function이지만, 문제점이 있다.
1. satured neurons "kill" the gradients
backpropagation에서 local gradient가 0에 가까우면 gradient는 거의 없게 된다.
2. sigmoid outputs are not zero centered
input 데이터가 항상 양수라면, backpropagation 과정에서 w는 다 양수거나, 다 음수이게 된다. (zero-mean한 데이터를 사용하는 것이 좋다.)
3. exp() is a bit compute expensive
2. Tanh
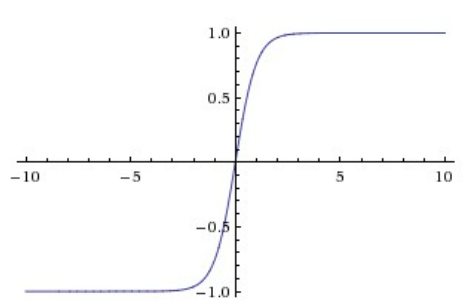
- sqaush into [-1,1]
- zero centered
3. ReLU
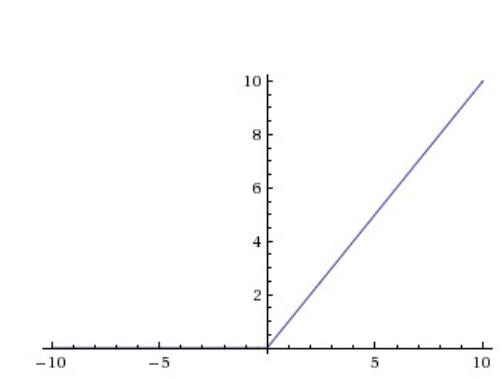
- Rectified Linear Unit
- 수렴을 급속도로 가속화 한다.
- 단순해서 계산이 효율적이다.
- positive biases 한 경우 좋다. (음수가 다 죽어버리니까)
4. Leaky ReLU
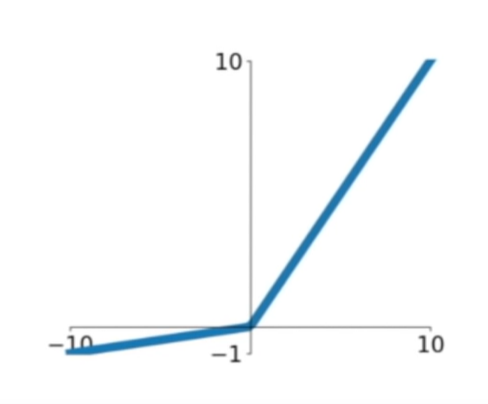
- ReLU가 음수일 때 죽는 문제를 해결하고자 등장함
- 음수일 때, 0.01의 작은 기울기 갖음
5. Maxout
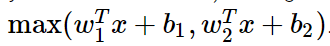
ReLU의 장점은 취하고, dying problem은 갖지 않음. 하지만 파라미터 수가 두배로 늘어난다는 문제가 생긴다.
✔ Data Preprocessing
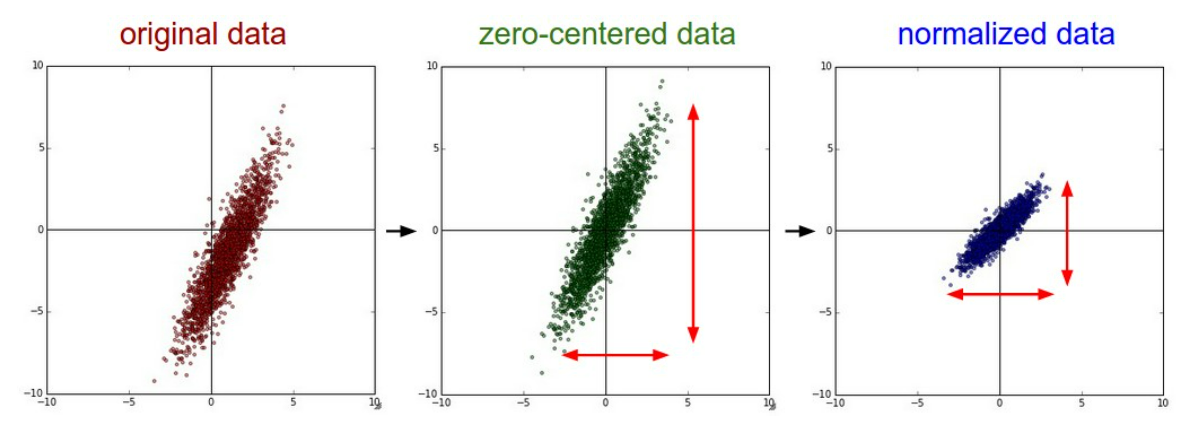
- zero-centered 하면 activation 에서도 효율적임
- normalized는 이미지에서는 많이 사용하지 않는다. 이미지에서는 위치가 충분히 의미를 갖기 때문에. 다른 머신러닝의 경우 normalization 해야 모든데이터가 비슷한 정도로 알고리즘에 기여함.
- test set에도 적용한다. (trn의 mean으로 tst도 preprocess 함)
- 이미지는 3 channel을 사용해 RGB 각각의 mean을 사용해서 뺀다. (batch의 평균을 사용해도 된다...?)
✔ Weight Initialization
- 모든 w를 0으로 초기화하면, 모든 layer의 gradient가 동일해지게 되고, 그럼 모든 NN이 같은 학습을 하게된다. 우리는 각각의 뉴런들이 다른 학습을 하기 바라므로 w는 모두 다른값으로 설정하는 것이 좋다.
- small random numbers로 설정하면?
- 깊은 network에서는 문제가 된다. activation이 다 0이 되어버린다 (std가 0으로)
- Xavier initialization
- 1/sqrt(n)으로 분산 규격화 (입출력의 분산을 맞춰준다)
w = np.random.randn(n) / sqrt(n)- ReLU는 출력의 절반을 줄이기 때문에 절반이 매번 0이 되어버린다.
- ReLU에 적절한 최적은
w = np.random.randn(n) * sqrt(2.0/n)
✔ Batch Normalization
- 연산을 계속하다보면 w의 scale이 커지는데, batch norm 통해서 일정하게 유지시켜줌
- 모든 레이어가 Unit Gaussian(표준정규분포) 따르게 한다.
- 높은 learning rates
- initialization의 의존도를 낮춤
- regularization의 역할을 해줌
✔ Babysitting the Learning Process
- Preprocess the data
- Choose the architecture
- Double check that the loss is reasonable. (클래스 개수를 고려했을 때, 적당한 값인지)
- train
- train with regulization and check learning rate
✔ Hyperparameter Optimization
Cross-validatoin strategy
- trn set 으로 학습, val set으로 평가
- log scale 사용해서 선택
Random Search
- Random Search를 사용하는 편이 Graid Search 보다 중요한 포인트들을 잘 잡아낸다.
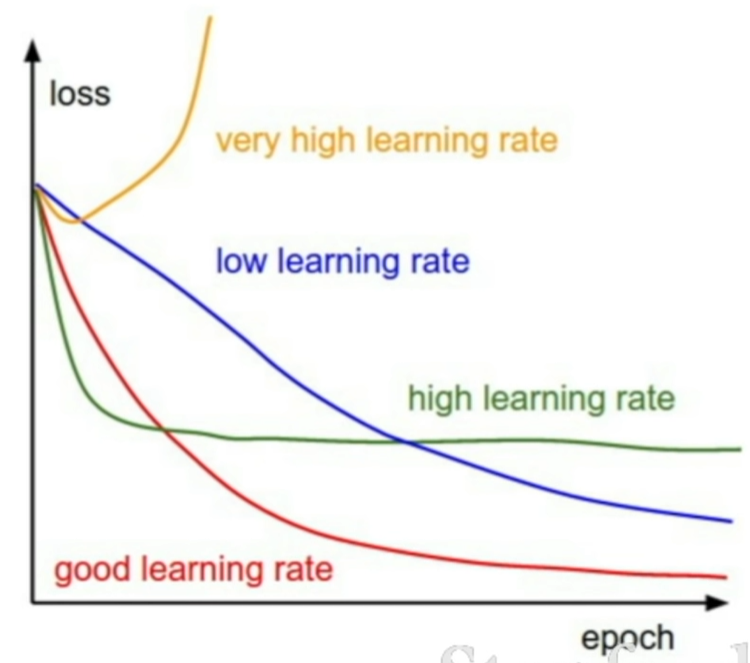
Learning rate
- Loss curve를 확인해서 learning rate가 적당한지 판단
꼼지락
앞부분에만 집중을 너무 해서 나중엔 조느라 잘 이해도 못했다. 노트까지 보려고 욕심내기 보단, 그냥 영상 들을 때 최대한으로 이해를 해야지ㅜㅜ 오랜만에 강의란 것을 들으니 너무 힘들다...

개발자가 되고 싶은 학부생의 꼼지락 기록