1. QLoRA: 효율적인 모델 학습의 핵심 🧠
거대 모델을 전체 튜닝하기에는 자원 소모가 너무 큼. 이를 해결하기 위해 QLoRA(Quantized Low-Rank Adaptation)를 도입함.
💡 핵심 메커니즘
- Freeze: 기존 모델의 가중치()를 4비트 양자화 상태로 고정하여 메모리 점유율을 최소화함.
- Adapter: 별도의 작은 행렬(, )만 추가하여 이 부분만 학습함.
- 수학적 원리: 여기서 와 는 저차원(Rank) 행렬로, 학습 파라미터를 수백만 개에서 수십만 개 수준으로 줄여줌.
🛠️ 레이어 구조 (q_proj 예시)
(q_proj): lora.Linear4bit(
(base_layer): Linear4bit(in_features=3072, out_features=3072, bias=False)
(lora_A): Linear(in_features=3072, out_features=32, bias=False)
(lora_B): Linear(in_features=32, out_features=3072, bias=False)
)- Rank(r=32): 원래 크기의 변화를 학습하는 대신, 중간에 32차원을 둔 두 개의 행렬로 분해함. 약 940만 개의 파라미터를 19만 개로 압축한 효과임.
2. 모델 구조 분석: Attention vs MLP 🔍
LLM의 내부는 크게 '소통'을 담당하는 Attention과 '지식'을 담당하는 MLP로 나뉨.
| 구분 | 역할 |
|---|---|
| Attention | 단어 간의 관계(Context) 파악 |
| MLP | 개별 토큰의 의미 분석 및 지식 추출 |
Llama 3의 SwiGLU 구조
Llama 3 모델은 성능 향상을 위해 개선된 MLP 구조를 사용함.
- gate_proj / up_proj: 입력을 8192차원의 고차원으로 확장하여 복잡한 특징을 추출함.
- SiLU 활성화 함수: 비선형성을 도입하여 복잡한 논리 구조를 학습함.
- down_proj: 처리된 정보를 다시 3072차원으로 압축하여 다음 레이어로 전달함.
3. 학습 프로세스와 하이퍼파라미터 ⚙️
모델 학습은 순전파 → 손실 계산 → 역전파 → 최적화의 4단계 사이클을 반복함.
🔄 Training 4-Steps
- Forward Pass: 입력 데이터를 통해 다음 토큰을 예측함.
- Loss Calculation: 예측값과 정답 간의 차이를 계산함.
- (정답 확률에 음의 로그를 취함)
- Backward Pass: 오차를 역으로 전달하며 각 파라미터의 기여도(Gradient)를 계산함.
- Optimization: Paged AdamW 옵티마이저를 사용해 가중치를 미세하게 조정함.
📊 주요 설정값
| 항목 | T4 GPU(Lite version) | A100 GPU(Full version) |
|---|---|---|
| Epochs | 1 | 3 |
| Batch Size | 32 | 256 |
| LoRA Rank (r) | 32 | 256 |
| Learning Rate | 1e-4 (Cosine) | 1e-4 (Cosine) |
T4 환경과 A100 환경에서 데이터셋의 크기가 다름.
4. 훈련 모니터링
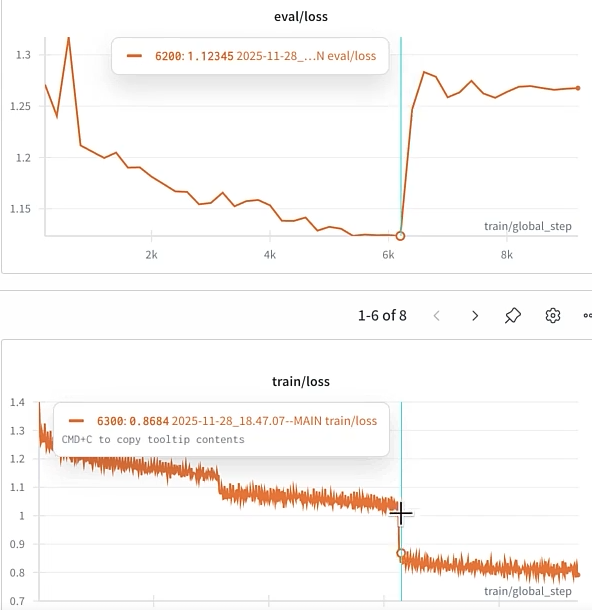
학습 도중 특정 시점에서 성능이 급격히 저하되는 현상을 포착함.
Weights and Biases 를 통해 모니터링.
⚠️ 과적합(Overfitting) 탐지
아래 그래프를 보면 6,200 Step(약 2-Epoch) 지점에서
train/loss는 급격히 떨어지는 반면,eval/loss는 급격히 튀어 오르는 것을 확인할 수 있음. 이는 모델이 훈련 데이터의 노이즈까지 암기하기 시작했다는 강력한 신호임.
✅ 해결 방안 및 개선 아이디어
- Weight Decay 상향: 가중치의 제곱 합을 손실 함수에 더해 모델의 복잡도를 강제로 제한함. 가중치를 작게 유지하여 '부드러운' 함수를 만듦.
- Learning Rate 하향: 보폭을 줄여 손실 함수의 최저점에 더 세밀하게 접근함.
- Cosine Scheduler 최적화: 후반부 학습률을 더 낮게 설정하여 안착을 도움.
- Dropout 활용: 학습 시 뉴런을 무작위로 비활성화하여 특정 경로에 의존하지 않도록 함 (현재 0.1 설정 유지).

I Enjoy Learn-and-Run Vibe😊