검색창 만들어보기 - 텍스트 필터링
Naver Developer
검색 > 블로그 Documents
Postman API Platform
flutter_bloc | Flutter Package
http | Dart Package
이번 글에서는 만들어 보면 좋을 기능에 대해서 작성해 보도록 하겠다.
개발해 볼 기능은 바로 네이버, 크롬과 같은 검색창에서 일치하는 검색어만 필터링 해주는 기능이다.
해당 기능을 개발해 보기 전에는 매우 쉽다고 생각할 수도 있는데, 전혀 그렇지 않다. 고려해주어야 할 요소도 너무 많고 다양한 텍스트를 파싱해서 필터링 해야하기 때문에 생각 보다는 많이 복잡한 기능이다.
영어인 경우 대/소 문자 구분을 해야하는데, 한글과 영어, 특수문자가 중복으로 섞이는 경우도 고려해 주어야 한다.
우선 아래 이미지를 보고 설명을 이어서 하겠다.
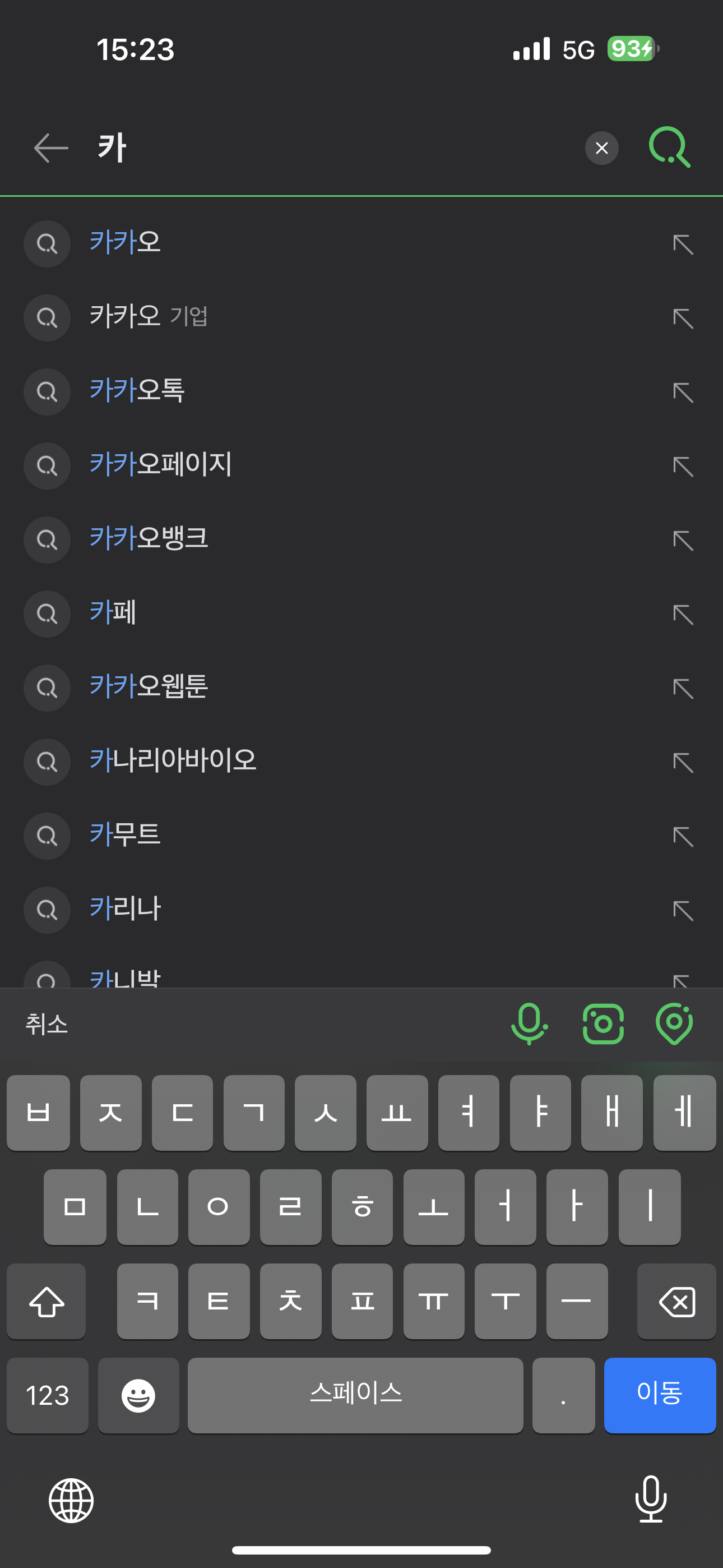 |  | 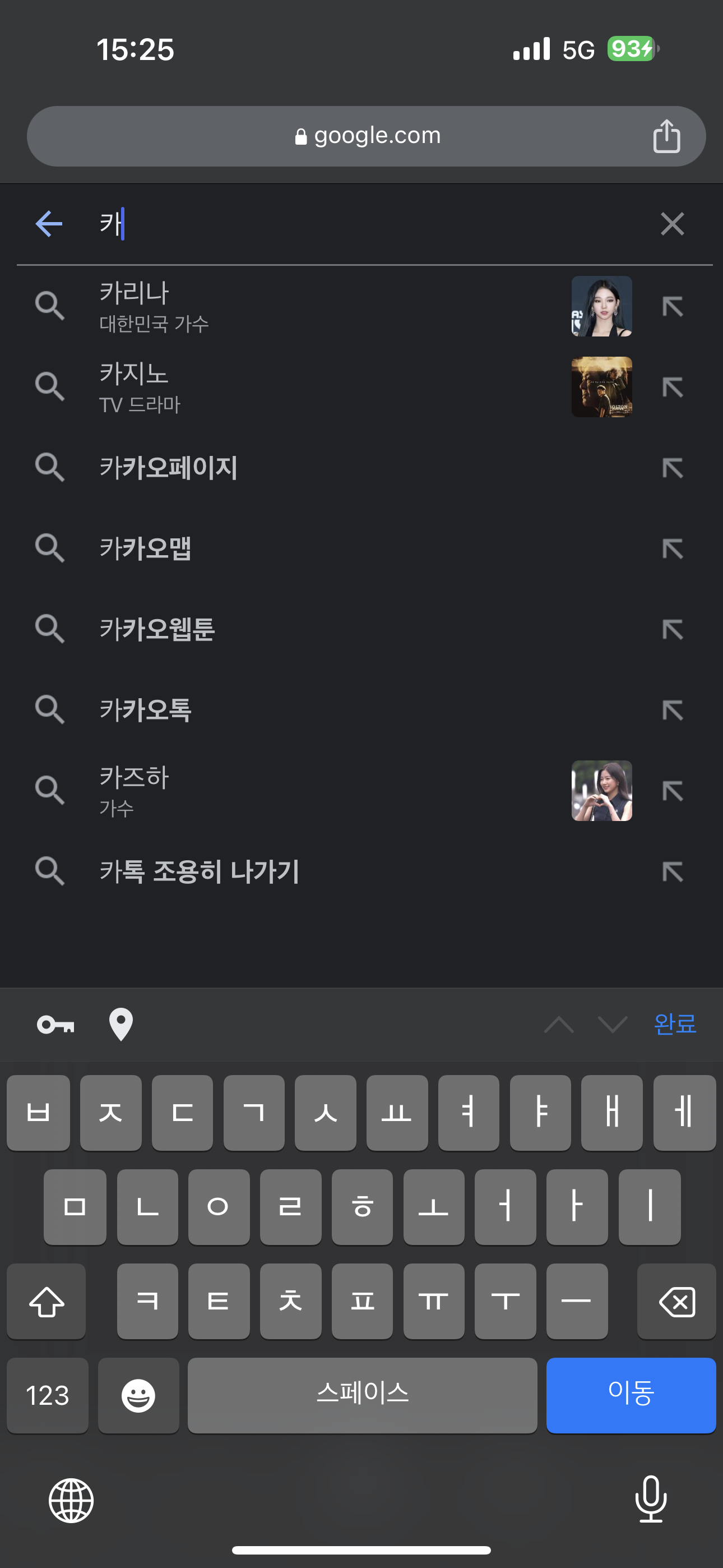 |
이러한 기능을 만들어 볼 것인데, 네이버와 크롬의 앱에서 "카"를 입력한 경우이다. 네이버인 경우 "카"와 일치하는 모든 추천 검색어에 필터링이 되는 반면, 크롬은 "카"에 해당하는 처음 글자에만 필터링을 해주고 있다.
네이버도 웹에서 검색하면 크롬과 동일하게 나오는데, 앱은 다르게 필터링을 만든 것 같다.
우선 우리는 데이터가 없기에, 쉽게 데이터를 검색해 볼 수 있는 API를 찾던 중 Naver API에서 제공해주는 블로그 검색 결과를 사용해서 개발을 해보도록 할 예정이다.
먼저 Naver API 사용을 위해서 네이버 개발자 센터에 접속해서 애플리케이션을 등록하고 호출 키를 발급 받아와야 한다.
Flutter는 BLoC Pattern을 사용하여 구현을 할 예정인데, Naver API가 하루 호출 제한량이 있어 텍스트가 입력될 때마다 호출하면 안되고, 텍스트 입력이 멈추고 1초 후에 호출하는 로직으로 개발을 해보도록 하겠다.
검색어 필터링 방법은 우선 네이버 앱과 동일한 방법으로 일치하는 키워드에 모두 필터링을 해주는 방법으로 개발을 해보고, 이어서 단어와 정확히 일치하는 문자만 필터링을 해주는 방법을 개발해 보겠다.
Naver API 사용 방법 부터 Postman을 통한 API 호출 테스트를 해보고, 이어서 Flutter로 본격적인 개발을 진행해 보겠다.
Naver Search API
Naver Developer로 접속을 해보자. 접속 링크는 위에 공유해 놓았다.
검색 > 블로그 문서를 확인하고 API를 어떻게 호출해야 하는지에 대해서 살펴보자면, 요청 URL 뒤에 query를 같이 보내주면 된다고 한다.
우리는 데이터가 필요한 것이기에, 옵셔널 파라미터는 따로 사용하지 않을 예정이다.
반환 형식으로는 JSON을 사용할 예정이다.

클라이언트 아이디와 클라이언트 시크릿을 추가하여야 한다. 해당 값들을 header에 요청해야 하기에 애플리케이션을 등록하고 아이디와 시크릿을 발급 받아보자.
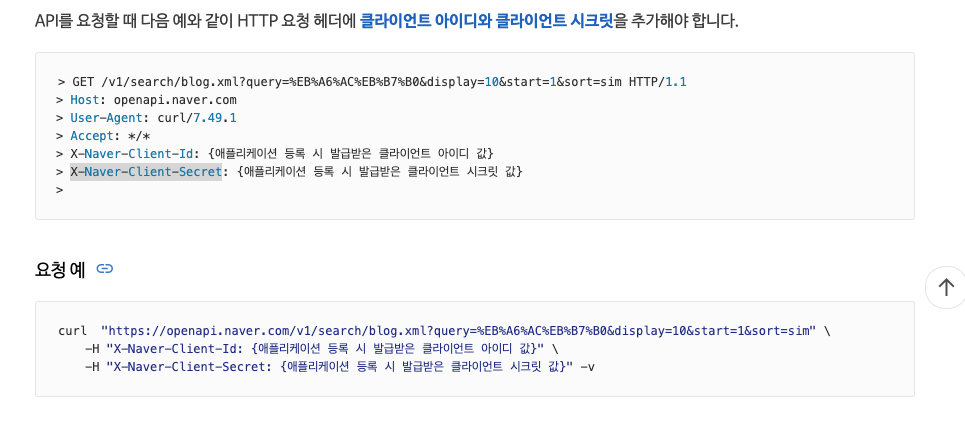
Create Application
상단 탭바의 Application 탭을 선택하여 애플리케이션 등록을 진행해보자.

애플리케이션 등록 페이지에서 각자의 애플리케이션 이름을 자유롭게 지정해 주고, 아래 사용 API를 검색으로 선택하도록 하자.
검색 API는 비로그인 오픈 API 환경만 생성해주면 되서, 각자의 앱 패키지 이름으로 앱 등록을 해주자.
테스트에서만 사용할 거라면 아무렇게나 써도 상관은 없다.
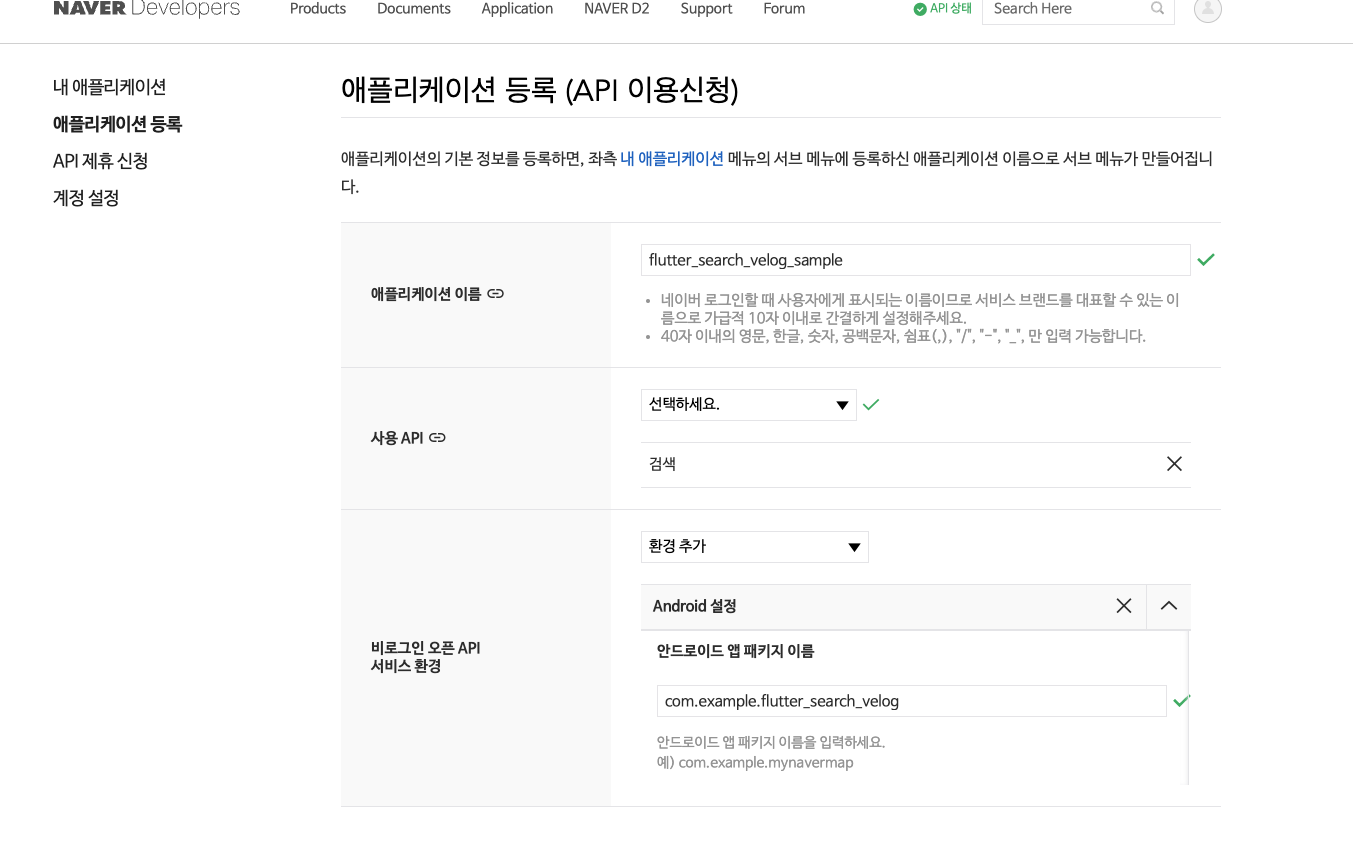
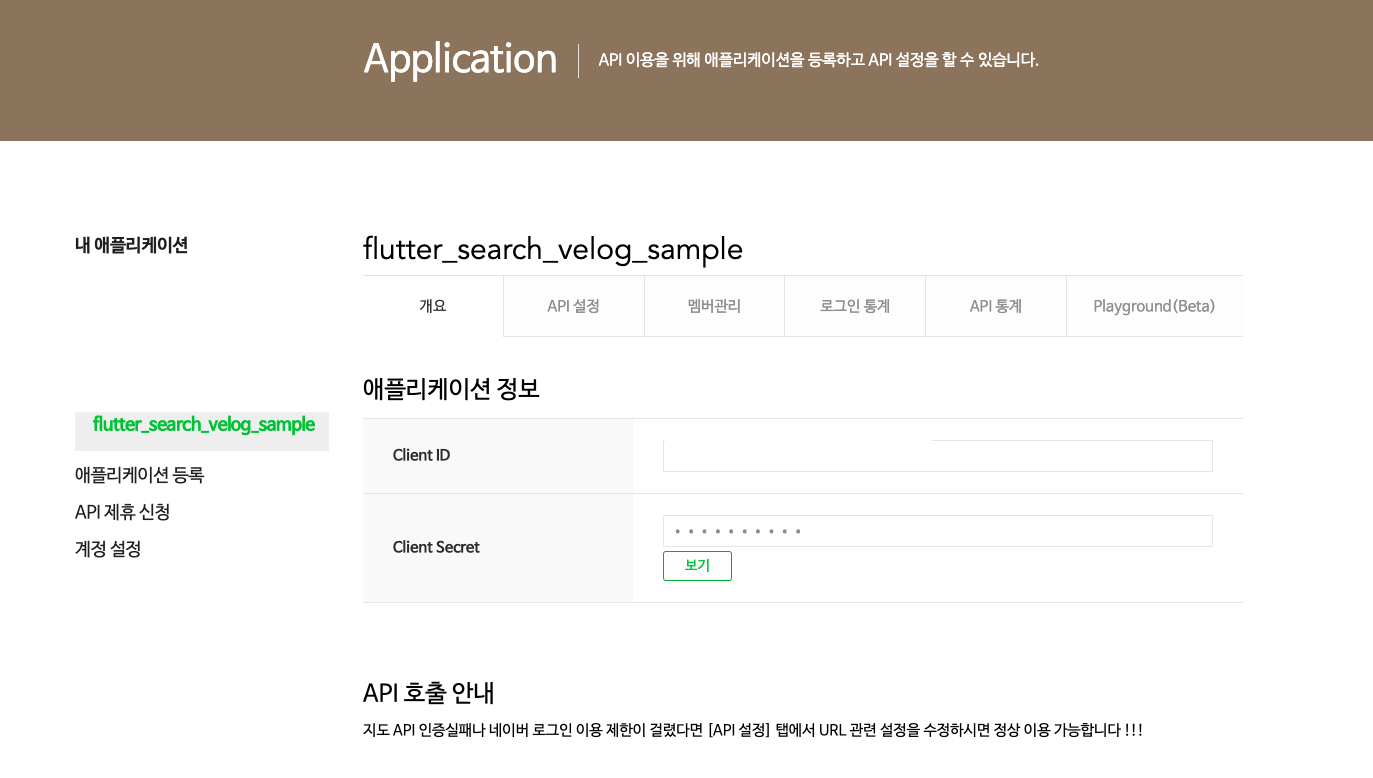
이제 생성을 하면 아래와 같이 정상적으로 생성이 되고, 우리가 필요한 클라이언트 아이디와 클라이언트 시크릿 키가 발급되있는 것을 확인할 수 있다.
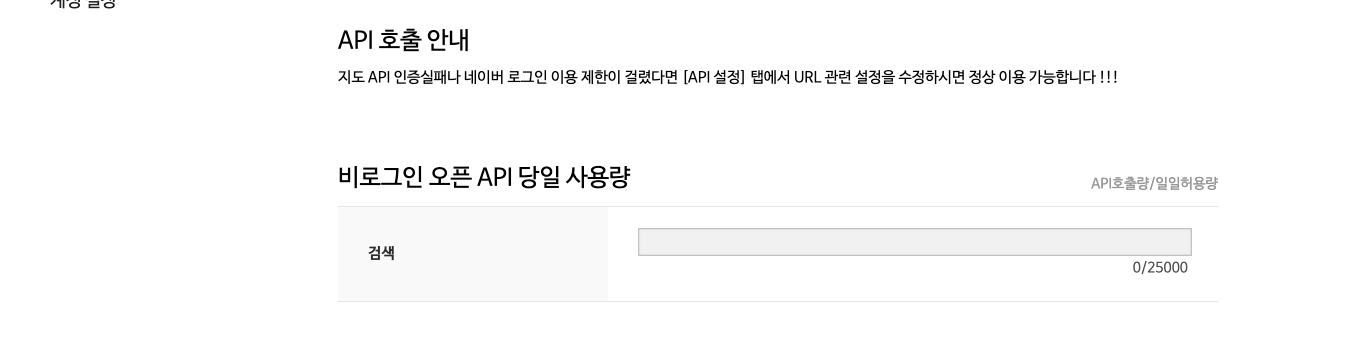
하단으로 이동해보면 API 호출 안내라고해서 사용량 제한을 볼 수 있도록 해준다. 25000건 이상의 호출은 안되는데, 테스트 용도로는 전혀 문제되지 않는다.
Postman
Postman을 사용해서 정상적으로 호출이 되는지 테스트 하도록 해보자. 위의 링크를 통해 Postman에 접속하자.
로그인을 진행하고 My Workspace를 클릭하자.
My Workspace 공간의 상단 추가하기 버튼을 누르면 API 요청을 진행할 수 있다.
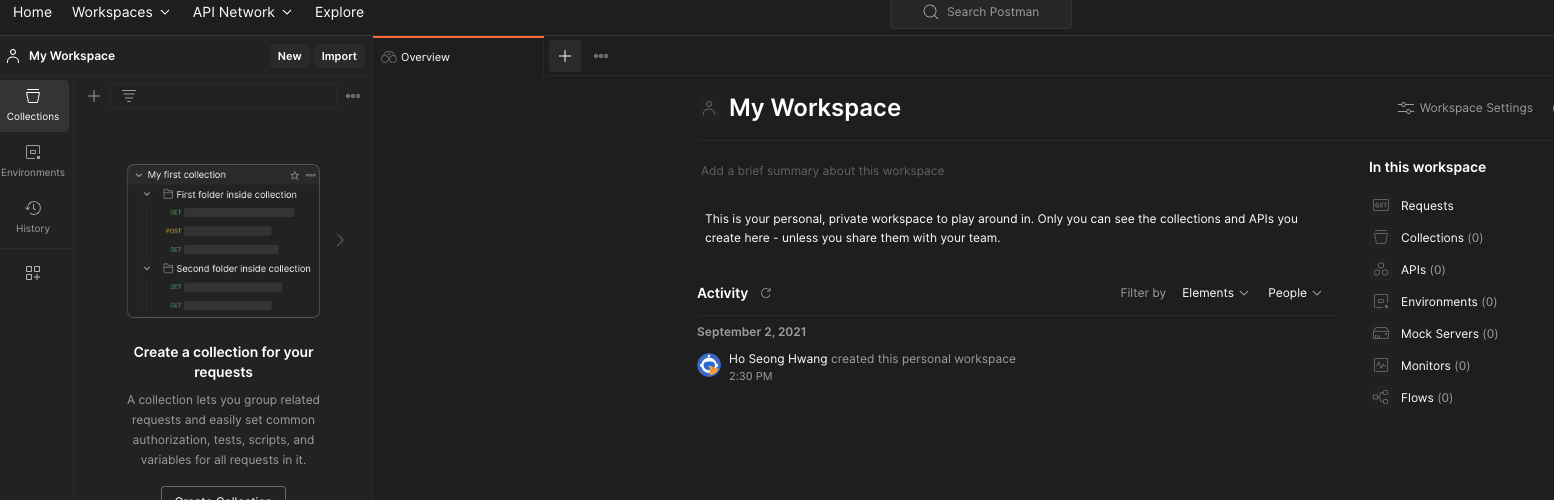
REST API 호출 방식은 GET으로 해주고, 아래의 값을 넣어주자.
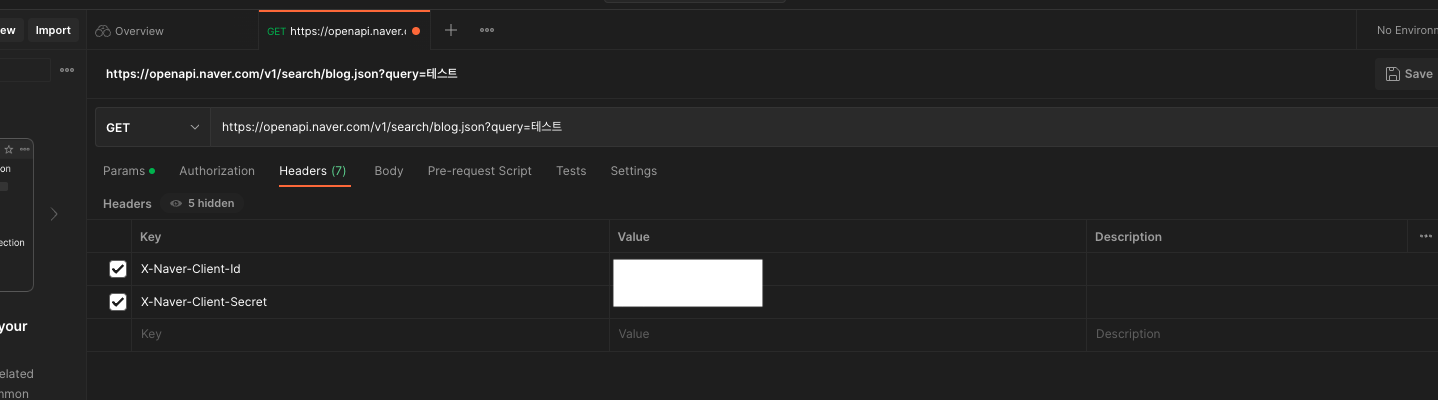
탭을 Headers로 이동을해서 Key-Value에 각자의 Client ID, Client Secret 키를 입력해주면 된다.
Key에 아래의 값들을 순서대로 넣어주자.
X-Naver-Client-Id
X-Naver-Client-Secret
Value에는 각자의 키를 넣어주면 된다.
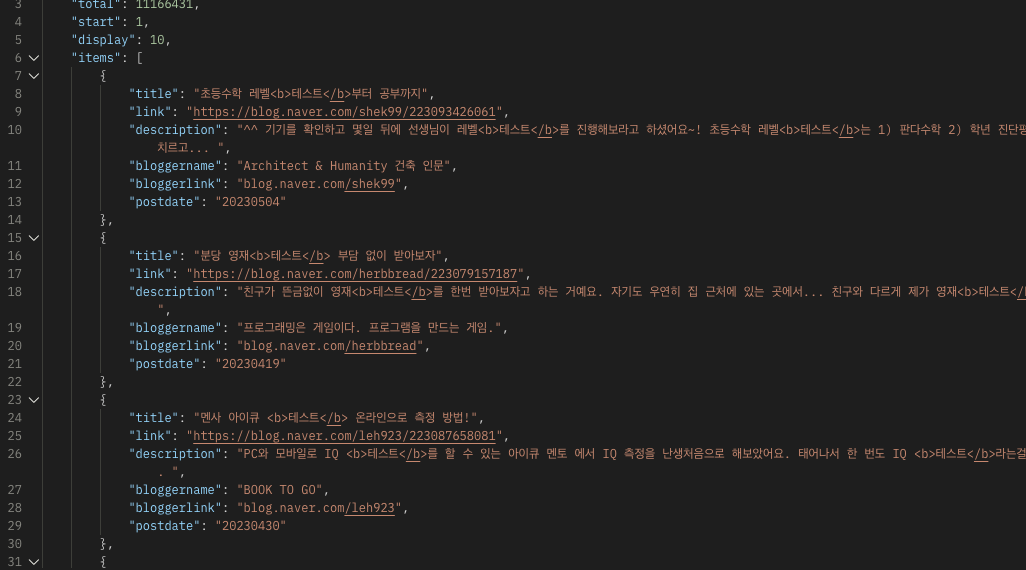
Send를 클릭해보면 아래와 같이 정상적으로 호출이 성공하여, 응답 결과가 노출되는 것을 확인할 수 있다.
여기까지 했으면 Naver API가 정상적으로 사용이 되는 것이다.
Flutter
이제 Flutter에서 본격적인 개발을 진해해 보자. 먼저 BLoC Pattern을 사용할 것이기에 아래 라이브러리를 추가하고, http는 API 통신에 사용되어야 해서 같이 추가해주자.
파일 구조는 데이터와 관련된 Repostiory, 비즈니스 로직을 담당할 Application, UI영역에 해당하는 Presentation, 마지막으로 데이터 모델을 생성할 Model 구조로 Layer를 나눠서 개발을 하겠다.
Dependencies
dependencies:
equatable: ^2.0.5
flutter_bloc: ^8.1.1
http: ^0.13.5API Test
Postman으로 요청한 API를 Flutter에서도 정상적으로 받아올 수 있는지 먼저 확인해 보도록 하겠다. 아래 각각의 Layer에 해당하는 파일을 생성해주고 아래 코드를 넣어서 우선 해당 페이지에 접속만 해보도록 하자.
코드에 대한 설명은 여기서는 진행하지 않겠다.
Repository
class SearchRepository {
static final SearchRepository instance = SearchRepository._internal();
factory SearchRepository() => instance;
SearchRepository._internal();
Future<void> getNaverBlogSearch() async {
try {
http.Response _response = await http.get(
Uri.parse("https://openapi.naver.com/v1/search/blog.json?query=테스트"),
headers: {
"X-Naver-Client-Id": {your_client_id},
"X-Naver-Client-Secret": {your_client_secret},
});
if (_response.statusCode == 200) {
logger.e(_response.body);
}
} catch (error) {
//
}
}
}Application
abstract class SearchFilterState extends Equatable {}
class SearchFilterInitState extends SearchFilterState {
List<Object?> get props => [];
}
abstract class SearchFilterEvent extends Equatable {}
class SearchFilterSearchingEvent extends SearchFilterEvent {
List<Object?> get props => [];
}class SearchFilterBloc extends Bloc<SearchFilterEvent, SearchFilterState> {
SearchFilterBloc() : super(SearchFilterInitState()) {
on<SearchFilterSearchingEvent>(_searching);
add(SearchFilterSearchingEvent());
}
Future<void> _searching(
SearchFilterSearchingEvent event, Emitter<SearchFilterState> emit) async {
await SearchRepository.instance.getNaverBlogSearch();
}
}Presentation
class AppSearchFilterScreen extends StatelessWidget {
const AppSearchFilterScreen({super.key});
Widget build(BuildContext context) {
return BlocProvider<SearchFilterBloc>(
create: (_) => SearchFilterBloc(),
child: BlocBuilder<SearchFilterBloc, SearchFilterState>(
builder: (context, state) {
return Scaffold(
appBar: appBar(title: "Search Filtering..."),
);
},
),
);
}
}
Result
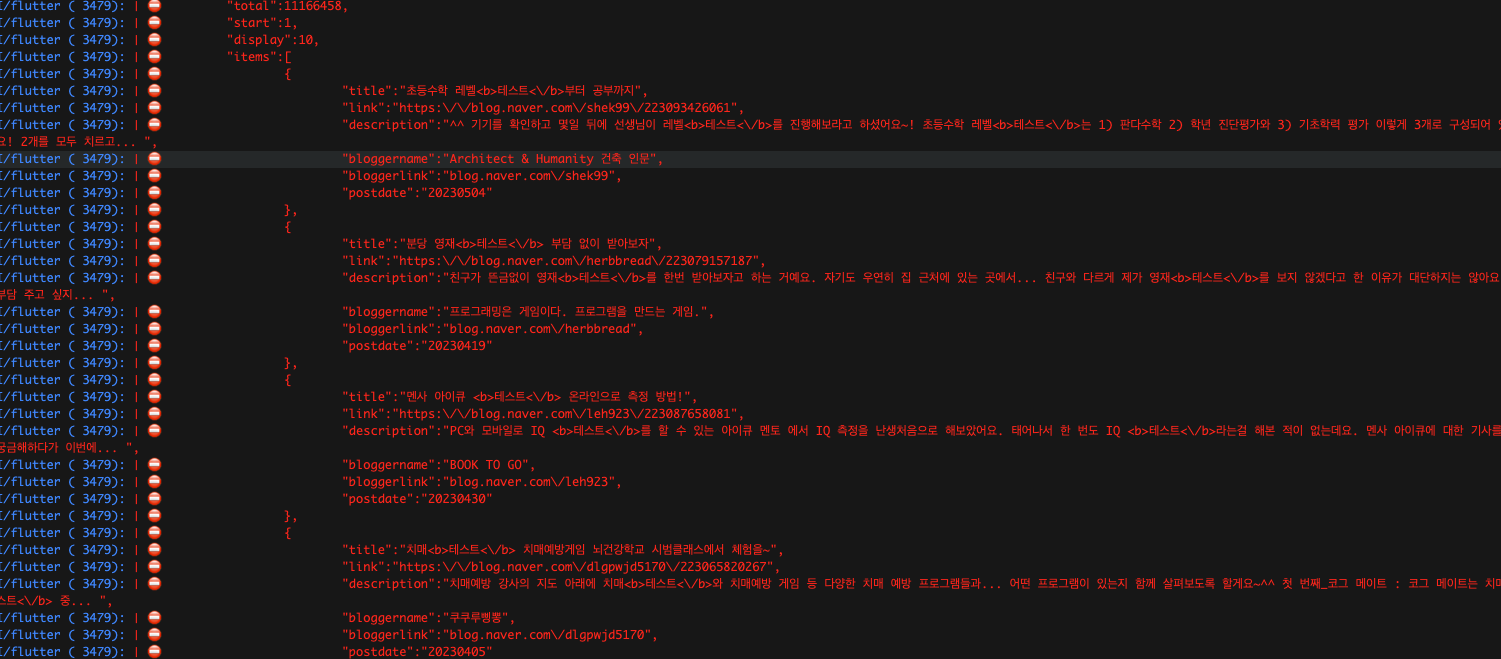
정상적으로 API가 호출되어 로그가 출력되는 것을 확인할 수 있다.
우리는 해당 반환 값의 title만 가져다 사용할 것인데, 문제가 하나 있다. 바로 태그가 들어가 있다는 것이다. 카카오 API는 태그 값을 제거해서 리턴해주는데, 네이버는 이런 부분을 전혀 고려하지 않는 듯하다.... 아쉽지만 직접 제거해서 사용해보자.
자 이제 부터 본격적인 개발을 진행할 것인데, Git 저장소를 아래 공유했으니 이해가 잘 되지 않는다면 참고하도록 하자.
Presentation
개발에 앞서 2가지 경우에 대해서 개발을 각각 진행할 것이기에, UI 코드를 수정해 주도록 하자. 원래 비슷한 유형의 UI 구조여서 Factory Pattern으로 진행하려고 하였는데, 그렇게 되면 복잡할 것 같아 보다 직관적으로 각각 UI 코드를 작성하도록 하겠다.
class AppSearchFilterScreen extends StatelessWidget {
const AppSearchFilterScreen({super.key});
Widget build(BuildContext context) {
return Scaffold(
appBar: appBar(title: "Search Filtering..."),
body: Column(
mainAxisAlignment: MainAxisAlignment.center,
children: [
_button(
context: context,
title: "모든 문자 필터링",
widget: const SearchFilterStringScreen()),
_button(
context: context,
title: "일치 문자열 필터링",
widget: const SearchFilterStringScreen()),
],
),
);
}
GestureDetector _button({
required String title,
required Widget widget,
required BuildContext context,
}) {
return GestureDetector(
onTap: () {
HapticFeedback.mediumImpact();
Navigator.of(context).push(MaterialPageRoute(builder: (_) => widget));
},
child: Container(
decoration: BoxDecoration(
borderRadius: BorderRadius.circular(12),
color: Colors.green,
),
margin: const EdgeInsets.symmetric(horizontal: 20, vertical: 24),
width: MediaQueryData.fromWindow(window).size.width,
height: 60,
child: Center(
child: Text(
title,
style: const TextStyle(
fontWeight: FontWeight.bold, color: Colors.amber, fontSize: 24),
)),
),
);
}
}SearchFilterStringScreen
class SearchFilterStringScreen extends StatelessWidget {
const SearchFilterStringScreen({super.key});
Widget build(BuildContext context) {
return BlocProvider(
create: (_) => SearchFilterBloc(),
child: BlocBuilder<SearchFilterBloc, SearchFilterState>(
builder: (context, state) {
return Scaffold(
appBar: appBar(title: "모든 문자 필터링"),
);
},
),
);
}
}SearchFilterStringsScreen
class SearchFilterStringsScreen extends StatelessWidget {
const SearchFilterStringsScreen({super.key});
Widget build(BuildContext context) {
return BlocProvider(
create: (_) => SearchFilterBloc(),
child: BlocBuilder<SearchFilterBloc, SearchFilterState>(
builder: (context, state) {
return Scaffold(
appBar: appBar(title: "일치하는 문자열 필터링"),
);
},
),
);
}
}Timer Duration
이번에도 2개의 다른 기능에 공통으로 사용하게 될 기능에 대해서 먼저 개발을 하도록 하겠다.
해당 기능은 텍스트 입력의 마지막 입력으로 부터 1초를 기다린 후 API를 호출하는 것이다. 이러한 기능 없이 텍스트 입력에 의해서 호출을 하게 된다면 리소스 낭비가 엄청날 것인데, 물론 상관 없다면 개발하지 않아도 된다.
먼저 텍스트 필드를 생성해주고, 해당 텍스트 필드의 onChanged에서 BLoC의 이벤트를 생성해 줄 것이다. 텍스트 필드를 수신하는 방법에는 다양한 방법이 있는데, Stateful로 생성을 한 뒤 initState에서 컨트롤러의 addListener 기능으로 구현하여도 된다.
BLoC에서 텍스트 필드를 수신할 때에는 initState를 활용하라고 나와있는데, 제가 개발하면서 BlocBuilder를 디버깅 해본 결과 onChanged에서 수신해도 큰 문제는 없어 보였다.
body: Column(
children: [
Container(
width: MediaQueryData.fromWindow(window).size.width,
height: 50,
color: Colors.green,
child: Padding(
padding: const EdgeInsets.symmetric(horizontal: 12),
child: TextFormField(
onChanged: (value) {
// Event
},
style: const TextStyle(
fontWeight: FontWeight.bold, color: Colors.amber),
decoration: const InputDecoration(
focusedBorder: InputBorder.none,
),
),
),
),
],
),Application
이번에는 Bloc의 로직을 생성해주자. 여기서 마지막 입력 후 1초가 지났다라는 이벤트를 받기 위해 Timer 객체를 활용할 것인데, 해당 Timer는 dart:async에 포함된 기능으로 Stream으로 구성되어 있다.
텍스트의 입력이 시작되고, onChaned안에서 이벤트를 호출 시키면 Event 내부에서 Timer를 Bloc의 State로 변경해 줄것이다.
onChaned는 텍스트 입력시 마다 호출될 것이기 때문에 만일 생성되어 있는 Timer가 있다면 구독을 취소하고 새로운 구독으로 State를 변경해 주어야 한다. 이러한 작업이 되어있지 않다면 모든 Timer 객체가 1초 후 이벤트를 발생시키게 될 것이다.
State
State에 Timer 객체를 nullable 타입으로 선언해주고, Timer 상태를 가지는 새로운 상태인 Searching State를 새롭게 생성해주자.
abstract class SearchFilterState extends Equatable {
final Timer? timer;
const SearchFilterState({
this.timer,
});
}
class SearchFilterSearchingState extends SearchFilterState {
const SearchFilterSearchingState({super.timer});
List<Object?> get props => [timer];
}
Event
이벤트를 새롭게 생성해서 onChaned에서 작동시켜 주면 된다. 이벤트의 필수 값으로 query를 받아올 수 있도록 해주자.
class SearchFilterTimerEvent extends SearchFilterEvent {
final String query;
SearchFilterTimerEvent({required this.query});
List<Object?> get props => [query];
}실제 API를 호출하는 이벤트에도 query를 받아올 수 있도록 코드를 수정해주자.
class SearchFilterSearchingEvent extends SearchFilterEvent {
final String query;
SearchFilterSearchingEvent({required this.query});
List<Object?> get props => [query];
}Bloc
Bloc에 Event 로직을 생성해주면 된다. 여기서 중요한 부분은 생성되는 Timer의 Duration을 1초로 준 뒤, 1초 후 Timer 내부에서 SearchFilterSearchingEvent를 작동시켜 API를 호출하게 된다.
on<SearchFilterTimerEvent>(_timer);
...
Future<void> _timer(
SearchFilterTimerEvent event, Emitter<SearchFilterState> emit) async {
if (state.timer != null) {
state.timer?.cancel();
}
Timer? _timer;
_timer = Timer(const Duration(milliseconds: 1000), () {
state.timer?.cancel();
add(SearchFilterSearchingEvent(query: event.query));
});
emit(SearchFilterSearchingState(timer: _timer));
}
Future<void> _searching(
SearchFilterSearchingEvent event, Emitter<SearchFilterState> emit) async {
List<String> _result = await SearchRepository.instance.getNaverBlogSearch(query: event.query);
}중요한 부분이 있는데, 만일 Timer의 1초 간격 전에 페이지를 닫고 뒤로 가게되면 어떻게 될까? 에러가 발생한다. Timer의 Stream이 취소되지 않은 상태에서 Bloc이 dispose되면 Flutter에서는 에러를 발생시키기 때문에 dispose 전에 Stream을 취소해주는 코드를 꼭 넣어주어야 한다.
Future<void> close() {
state.timer?.cancel();
return super.close();
}Repostiory
API를 호출해서 데이터를 받아오는 Repository Layer 부분을 수정해주자. 우리가 필요한 값은 title이기 때문에, json 데이터의 타이틀만 배열로 리턴해주도록 하고, query는 필수 값으로 받아올 수 있도록 수정 해주자.
Future<List<String>> getNaverBlogSearch({
required String query,
}) async {
try {
http.Response _response = await http.get(
Uri.parse(
"https://openapi.naver.com/v1/search/blog.json?query=$query"),
headers: {
"X-Naver-Client-Id": _id,
"X-Naver-Client-Secret": _secret,
});
if (_response.statusCode == 200) {
Map<String, dynamic> _fromMap = json.decode(_response.body);
List<dynamic> _data = List.from(_fromMap["items"]).toList();
List<String> _return = _data.map((e) {
String _title = e["title"];
_title = _title.replaceAll("</b>", "");
_title = _title.replaceAll("<b>", "");
return _title;
}).toList();
return _return;
} else {
return [];
}
} catch (error) {
return [];
}
}이제 onChaned에 이벤트를 실행시켜 테스트를 해보자. 마지막 텍스트 입력 후 1초 후에 딱 한 번만 API를 호출하는 것을 확인할 수 있다.
onChanged: (value) => context.read<SearchFilterBloc>()
.add(SearchFilterTimerEvent(query: value)),일치하는 모든 문자 필터링 기능
우선 일치하는 모든 문자는 전부 필터링을 해주는 기능을 해보도록 하자. 해당 기능은 생각보다 어렵지는 않다.
API로 부터 받아온 텍스트를 나눠서 배열로 변경해 줄 것인데, "네이버"라는 문자를 split 기능을 사용해서 ["네", "이", "버"] 이런 형식으로 변경해서 일치하는 문자만 텍스트의 스타일을 변경해 줄 것이다.
Application
위에서 설명한 형태로 하려면 API에서 리턴 받은 List의 각각의 문자열을 다시 배열 형태로 변경해 주는 작업을 해주면 된다.
state
State에 현재 입력한 텍스트의 값을 가지고 있는 query 변수와 strings 변수를 등록해 주자.
abstract class SearchFilterState extends Equatable {
final Timer? timer;
final String query;
final List<List<String>>? strings;
const SearchFilterState({
this.timer,
this.query = "",
this.strings,
});
}class SearchFilterSearchingState extends SearchFilterState {
const SearchFilterSearchingState({super.timer, super.strings, super.query});
List<Object?> get props => [timer, query];
}
class SearchFilterSearchedState extends SearchFilterState {
const SearchFilterSearchedState({super.strings, super.query});
List<Object?> get props => [query];
}
bloc
검색어를 호출하는 기능인 Bloc에서 API 반환 값을 배열 형태로 변경해서 상태를 변경해 주도록 하자.
Future<void> _searching(
SearchFilterSearchingEvent event, Emitter<SearchFilterState> emit) async {
List<String> _result =
await SearchRepository.instance.getNaverBlogSearch(query: event.query);
List<List<String>> _strings =
_allMatching(strings: _result, query: event.query);
emit(SearchFilterSearchedState(strings: _strings, query: event.query));
}단순히 리턴 받은 타이틀 배열을 반복문을 통해서 각각의 문자열을 배열로 변환해주고 있다.
List<List<String>> _allMatching({
required List<String> strings,
required String query,
}) {
List<List<String>> _result = [];
if (strings.isNotEmpty) {
for (int i = 0; i < strings.length; i++) {
_result.add(strings[i].split(""));
}
}
return _result;
}Presentation
검색창 아래에 검색어를 나열하게 되는데, 문자열이 Text 객체를 사용해서 하게 되면, 각각의 스타일을 지정할 수 없게된다.
RichText 객체를 사용해서 UI를 보여주게 되면 각각의 문자열의 스타일을 다르게 할 수있어서 원하는 기능을 개발할 수 있게 된다.
Expanded(
child: ListView.builder(
itemCount: state.strings!.length,
itemBuilder: (context, index) {
return Padding( padding: const EdgeInsets.only(top: 20, bottom: 4, left: 12, right: 12),
child: Row(
crossAxisAlignment: CrossAxisAlignment.start,
children: [
Text(
"${index + 1}",
style: const TextStyle(
fontWeight: FontWeight.bold,
fontSize: 13),
),
const SizedBox(width: 12),
Flexible(
child: RichText(
text: TextSpan(children: [
...List.generate(
state.strings![index].length,
(i) => TextSpan(
text: state.strings![index][i],
style: TextStyle(
color: _isSame(
query: state.query
.split(""),
result: state
.strings![index][i])
? Colors.amber
: const Color.fromRGBO(
215, 215, 215, 1),
fontSize: 12,
)))
])),
),
],
),
);
}),
)문자열의 일치하는 조건에 대/소 문자를 확인하는 조건도 추가되어야 한다.
bool _isSame({
required List<String> query,
required String result,
}) {
return query.contains(result) ||
query.contains(result.toUpperCase()) ||
query.contains(result.toLowerCase());
}Result
이제 검색어를 입력해서 일치하는 문자열의 스타일이 변경 되는지 확인을 해보자.
아래 결과를 보면 정상적으로 일치하는 모든 문자의 텍스트 스타일이 변경되는 것을 확인할 수 있다.

Git
Presentation
Applicatioin
https://github.com/boglbbogl/flutter_velog_sample/tree/main/lib/app/search/filter/application
일치하는 문자열 필터링 기능
지금까지 일치하는 모든 문자를 필터링 하는 기능에 대해서 살펴 보았는데, 이번엔 더 확실하게 문자열이 일치하는 경우에만 필터링을 하는 기능을 만들어 보도록 하자.
해당 기능도 동일하게 RichText를 사용할 예정이어서 UI는 거의 동일하다고 보시면 되는데, 로직은 완전히 새롭게 작성하여야 한다.
이전까지는 단순히 문자를 배열 형태로 변경해서 1:1 비교를 하여 텍스트의 스타일을 변경했는데, 이번에 작업하는 개발은 동일한 방식으로 하면 안된다.
개발의 순서를 살펴보면 API는 동일하게 사용할 것이기에, 추가적인 코드는 공유하지 않고, 로직 부분을 중점적으로 살펴보도록 하겠다.
이번에는 문자열을 배열의 스트링 타입으로 변환하는게 아닌, Map형태로 변환해서 key 값은 String으로 하고, value를 int 타입으로 변환해서 사용할 것이다.
이렇게 변환하는 이유는 일치하는 텍스트에만 가중치를 줘서 가중치가 있는 문자열을 구분하기 위함이다. 만일 "카"를 입력해서 "카카오"라는 검색 결과가 있다고 가정했을 때, 맨 앞에 있는 String을 {"카" : 1} 형태로 변환해 주고, 그 다음에 오는 String에는 {"카" : 0}로 변환을 해야지만 텍스트 필터링을 정확하게 할 수 있게 된다.
또 하나 구분해야 하는 점이 바로 영문 대/소 문자와 영문+한글 또는 영문+특수문자가 입력되는 상황이다.
예시로 설명하자면 "bloc"이라고 검색을 했는데, 결과 값에 "BLoC" 이런식으로 되어 있다면, 대/소 문자 구분 없이 필터링을 해주어야 하는데, 일치하는 문자열을 배열로 변경해주는 과정에서 작성된 query의 대+소 문자가 같이 있다면 upperCase/lowerCase를 사용해서 파싱하기에 너무 많은 코드가 반복되서 작성되게 될 것이다.
차근차근 개발해 보면서 추가적인 설명을 이어서 하도록 하겠다.
Application
BLoC은 위에서 사용한 것을 같이 사용할 예정이기에, 추가로 만들지 않고 상태만 변경해서 사용하도록 하겠다.
State
filterings 라는 변수를 하나 추가해주자.
abstract class SearchFilterState extends Equatable {
final Timer? timer;
final String query;
final List<List<String>>? strings;
final List<List<Map<String, int>>>? filterings;
const SearchFilterState({
this.timer,
this.query = "",
this.strings,
this.filterings,
});
}검색 중, 검색이 완료되서 API를 호출한 상태에서도 filterings 변수를 등록해주면 된다.
class SearchFilterSearchingState extends SearchFilterState {
const SearchFilterSearchingState(
{super.timer, super.strings, super.query, super.filterings});
List<Object?> get props => [timer, query];
}
class SearchFilterSearchedState extends SearchFilterState {
const SearchFilterSearchedState(
{super.strings, super.query, super.filterings});
List<Object?> get props => [query];
}
Bloc
Bloc 내부의 검색 중인 이벤트를 분기하여서 사용하도록 하겠다.
Future<void> _searching(
SearchFilterSearchingEvent event, Emitter<SearchFilterState> emit) async {
List<String> _result =
await SearchRepository.instance.getNaverBlogSearch(query: event.query);
if (isFilter) {
List<List<Map<String, int>>> _strings =
_filtering(strings: _result, query: event.query);
emit(SearchFilterSearchedState(query: event.query, filterings: _strings));
} else {
List<List<String>> _strings =
_allMatching(strings: _result, query: event.query);
emit(SearchFilterSearchedState(strings: _strings, query: event.query));
}
}이제 _filtring() 함수의 기능만 작성해 주면되는데, 변수 구조를 한 번 살펴보도록 하자.
만약에 "카"라고 검색을 했을 때, 결과 값으로 "카카오", "판교카카오", "캠핑카" 이렇게 3개의 결과 값이 나왔다고 하면 아래와 같은 형태로 데이터를 변환해 줄 것이다.
[
[
{"카" : 1}, {"카오" : 0},
],
[
{"판교" : 0}, {"카" : 1}, {"카오" : 0},
],
[
{"캠핑" : 0}, {"카" : 1},
],
]이렇게 변환한 후에 가중치가 1인 문자열만 필터링을 걸어주면 된다. 우선 방식은 어렵지 않다고 생각한다.
위의 방식대로 로직만 생성해 주면 끝이다.
로직을 만들어보자.
모든 문자를 필터링 하던 방식과 동일하게, 입력한 텍스트와 결과 값을 필수로 받아와서 결과 값이 있는 경우에만 실행해 줄 수 있도록 하자.
Map 형태로 리턴 해야 되기에 _result 변수를 생성해서 파싱한 Map을 add한 후에 리턴해주는 로직으로 개발을 하도록 하겠다.
List<List<Map<String, int>>> _filtering({
required String query,
required List<String> strings,
}) {
List<List<Map<String, int>>> _result = [];
if (strings.isNotEmpty) {
// for 문
}
return _result;
}for 문을 사용해서 결과 값을 하나씩 차례대로 파싱을 해보도록 하자. for문 안에 조건문으로 일치하는 문자가 있는지를 먼저 확인하여야 되는데, 여기서 toLowerCase()로 소문자 형태에서 파싱을 할 것이다.
"B"를 입력 했을 때에 결과 값이 "b"라면 일치하는 문자가 아니기에 결과 문자열과 입력 문자 모두를 소문자 형태에서 비교를 하는 것이다. "Ab" 이렇게 입력 했을 때, 결과 값이 "aB" 이런 경우도 고려해야 해서 소문자 또는 대문자로 변환한 상태에서 비교를 해야한다.
조건에 일치한다면, 일치하는 문자가 어디에 위치해 있는지를 기준으로 문자열을 나눠줄 것인데, 이 때도 동일하게 모든 문자를 소문자 형태로 변환한 상태에서 위치를 찾게 된다.
indexOf를 사용하면 텍스트와 일치하는 문자의 시작 인덱스를 알 수 있어서 시작 문자열을 기준으로 앞 / 뒤를 나눠서 사용해야 하는데, 앞 문자열은 _splitIndex 까지 나눠주면 되고, 문제는 뒷 문자열을 나누는 방법인데, 입력되는 문자가 3글자라면 indexOf의 반환되는 인덱스에 입력 글자 길이를 더한 값까지를 시작점으로 하고, 결과 값의 문자 길이를 종료 인덱스로 해주어야 한다.
for (int i = 0; i < strings.length; i++) {
if (strings[i].toLowerCase().contains(query.toLowerCase())) {
int _splitIndex =
strings[i].toLowerCase().indexOf(query.toLowerCase());
String _first = strings[i].substring(0, _splitIndex);
String _last = strings[i]
.substring(_splitIndex + query.length, strings[i].length);
}
}이번에도 예시를 통해 확실히 이해를 해보도록 하자.
"네이버"라고 검색해서 결과 값으로 "새로운 모습의 네이버 PC 메인을 만나보세요."라는 결과가 나왔을 때, 앞 문자열은 "새로운 모습의 "이고, 뒷 문자열은 " PC 메인을 만나보세요."가 된다.
만약에 "네이버 블로그"라는 결과 였다면, 앞문자열은 "" 빈 값이 될 것이고, 뒷 문자열은 " 블로그"가 될 것이다.
이제 여기까지 했으면, 문자열에 가중치를 더 해주는 작업을 하면된다.
_splitIndex의 인덱싱을 기준으로 조건을 사용해서 가중치를 주는 작업을 해보도록 하겠다.
문자열을 나눠서 배열에 담아야 하기에 _toMap이라는 변수를 생성해 주었다.
List<Map<String, int>> _toMap = [];
if (_splitIndex == 0 && strings[i].length - 1 == _splitIndex) {
// case 1 결과 값 == 입력 값
} else if (_splitIndex == 0 && strings[i].length - 1 != _splitIndex) {
// case 2 결과 값의 앞 문자와 입력 값이 동일 하지만, 뒷 문자열이 더 있는 경우
} else if (_splitIndex != 0 && strings[i].length - 1 == _splitIndex) {
// case 3 결과 값의 앞 문자와 일치하지 않지만, 뒷 문자열이 더 이상 없는 경우
} else {
// case 4 결과 값의 앞 문자열과 뒷 문자열이 모두 있는 경우
}각 분기 상태에 따라서 가중치를 더한 값을 _toMap 변수에 담아주는 작업을 진행해 보자.
여기서 한 가지 문제가 문자열을 앞 뒤로 자르게 되면서 일치하는 텍스트의 값을 모른다는 것이다. 이상하게 생각할 수 있는데, 만약에 한글이라면 일치하는 텍스트의 값을 모를 수 없다. 텍스트 필터에 입력된 값이 결국 일치하는 값이기 때문인데, 문제는 영문에 있다.
입력을 "bloc"라고 했는데, 결과에서 일치하는 "bloc"의 형태가 "BLoC"라고 되어있다면, 일치하는 값을 알 수가 없는 것이다. 그러기 때문에 결과 값에서 일치하는 텍스트를 다시 받아오는 로직을 만들어 주어야 한다.
case 1
결과 값과 입력 값이 정확히 일치하는 경우이기에, 결과 값 문자에 가중치를 1을 주어 저장해주면 된다.
_toMap.addAll([{strings[i]: 1}]);case 2
앞 문자열이 일치하는 경우기때문에, 앞에는 일치하는 문자에 1을 주고, 뒤에는 우리가 나눈 뒷 문자열에 0을 주어서 저장해 주면되는데, 일치하는 문자를 모르기 때문에, replaceFirst를 사용해서 뒷 문자를 빈 값으로 치환하게 되면 결국 일치하는 문자열을 얻을 수 있다.
_toMap.addAll([
{strings[i].replaceFirst(_last, ""): 1},
{_last: 0}
]);case 3
case 2와 반대의 경우이기에 동일하게 이해하면 된다.
_toMap.addAll([
{_first: 0},
{strings[i].replaceFirst(_first, ""): 1}
]);case 4
이번엔 일치하는 문자 앞 뒤로도 문자열이 있는 경우이기에, 위에서 하던 방식과 동일하게 앞 뒤 문자를 빈 값으로 치환해서 1의 가중치를 주면 된다.
String _query = strings[i].replaceFirst(_first, "");
_query = _query.replaceFirst(_last, "");
_toMap.addAll([
{_first: 0},
{_query: 1},
{_last: 0}
]);지금까지 살펴본 로직의 전체 코드이다. 이런 방법 외에도 다른 방법으로 시도하면서 자신만의 로직을 만들어 보는데, 참고하면 좋을 것 같다.
List<List<Map<String, int>>> _filtering({
required String query,
required List<String> strings,
}) {
List<List<Map<String, int>>> _result = [];
if (strings.isNotEmpty) {
for (int i = 0; i < strings.length; i++) {
List<Map<String, int>> _toMap = [];
if (strings[i].toLowerCase().contains(query.toLowerCase())) {
int _splitIndex =
strings[i].toLowerCase().indexOf(query.toLowerCase());
String _first = strings[i].substring(0, _splitIndex);
String _last = strings[i]
.substring(_splitIndex + query.length, strings[i].length);
if (_splitIndex == 0 && strings[i].length - 1 == _splitIndex) {
_toMap.addAll([
{strings[i]: 1}
]);
} else if (_splitIndex == 0 && strings[i].length - 1 != _splitIndex) {
_toMap.addAll([
{strings[i].replaceFirst(_last, ""): 1},
{_last: 0}
]);
} else if (_splitIndex != 0 && strings[i].length - 1 == _splitIndex) {
_toMap.addAll([
{_first: 0},
{strings[i].replaceFirst(_first, ""): 1}
]);
} else {
String _query = strings[i].replaceFirst(_first, "");
_query = _query.replaceFirst(_last, "");
_toMap.addAll([
{_first: 0},
{_query: 1},
{_last: 0}
]);
}
} else {
_toMap.add({strings[i]: 0});
}
_result.add(_toMap);
}
}
return _result;
}Presentation
UI는 동일하기에 위에서 작성한 로직이 어떻게 보여지는지 원리를 시각적으로 살펴보자. 아래와 같은 원리로 가중치를 주어 텍스트의 필터링을 진행하게 된다.
 | 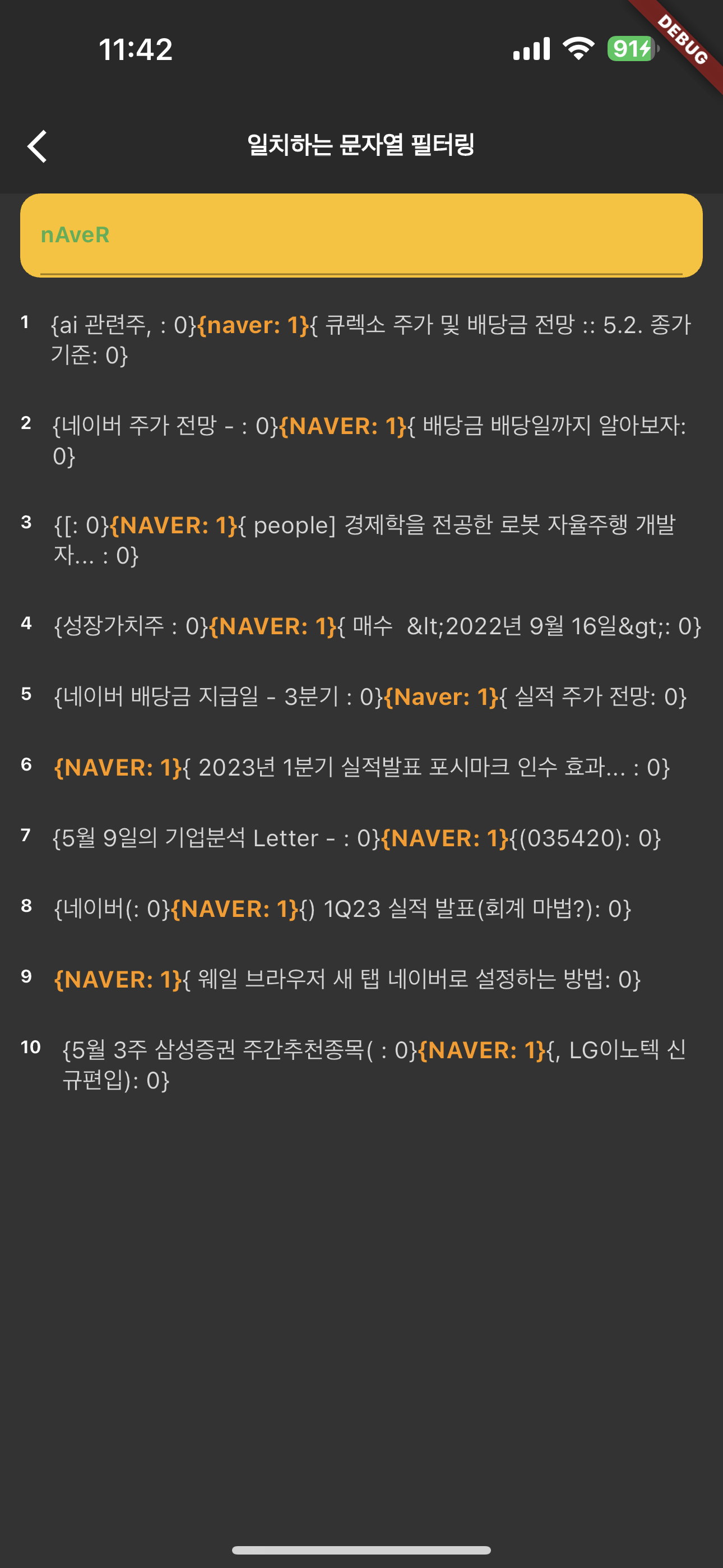 |
타입이 Map 형태이기 때문에, key를 꺼내서 텍스트로 노출해 주면 된다.
text: state.filterings![index][i].entries.first.key.toString(),Result

Git
Presentation
Applicatioin
https://github.com/boglbbogl/flutter_velog_sample/tree/main/lib/app/search/filter/application
마무리
이렇게 해서 네이버 API 간단한 사용 방법 부터 텍스트를 필터링하는 방법까지 살펴보았다.
저도 처음에 텍스트를 필터링하는 기능을 개발해야 하는 상황이 있었는데, 영문 대/소문자를 구분하지 않아서 고생을 좀 했었다. 이런 기능을 갖춘 라이브러리가 종종 있는데, 생각보다는 별로여서 그냥 만들어 사용하게 되었다.
가중치를 주지 말고 Boolean 값을 사용해도 되는데, 가중치라는 개념을 사용해서 integer 타입으로 사용한 이유는 추후 확장성을 고려하였기 때문이다.
지금은 1의 가중치만 사용하지만 추후 어떤 텍스트 필터링 기능이 필요하게 될지 몰라 정수형 타입을 사용하여 개발하게 되었다.
전체 개발 코드를 설명한 것은 아니기에, Git 저장소에서 코드를 가져다 직접 실행해보면서 개발해 보시고 자신만의 더 좋은 코드를 작성해 보시기를 추천합니다.
혹시라도 궁금한 점이 있으시면 댓글 남겨주세요 !
