SMOTE
https://machinelearningmastery.com/smote-oversampling-for-imbalanced-classification/
단어정리
- SMOTE의 목적도 결국은 data의 증가다. 그래서 먼저 data의 augmentation에 대해서 정확하게 알아보자. (현재 그림이 업로드에 문제가 있습니다...)
- data를 추가하는 것이 아닌 기존에 있는 data를 가지고 증가시키는 것
Tabular data
→ 표 형태의 data
→ SMOTE는 Tabular data만 적용한다.
Undersampling vs Oversampling
→ 자료를 증가시키는 것과 간추리는 차이점
ROC- AUC metric
ROC- Receiver Operating Characteristics
AUC- Area Under Curve
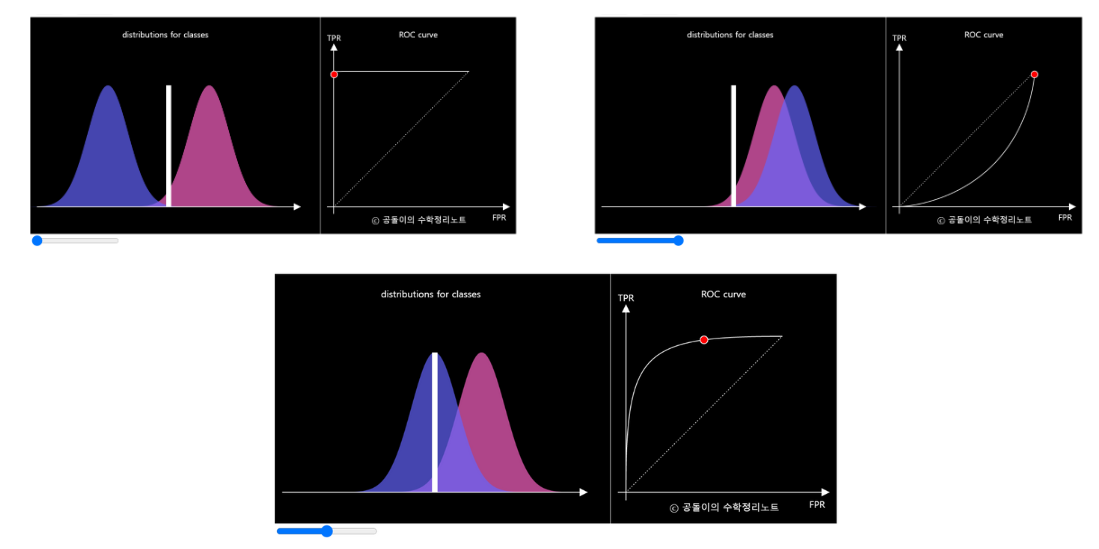
https://angeloyeo.github.io/2020/08/05/ROC.html
즉, ROC의 AUC가 높다는 것은 클래스를 구분하는 모델의 성능이 좋다는 뜻이다.
SMOTE (Synthetic Minority Oversampling Technique)
SMOTE는 피쳐 공간에서 가까운 예제를 선택하고 피쳐 공간의 예제 사이에 선을 그리고 그 선을 따라 한 지점에서 새 샘플을 그리는 방식으로 작동한다.
Minority examples에 대해서 적용을 하는 것이다. Minority examples 중에서 random하게 하나를 고르고 k거리의 examples 중 다른 하나를 선택해 선을 그리는 방법이다. 전혀 새로운 정보가 아닌 기존에 있는 minority examples와 비교적 가깝기에 활용하기 용이하다
단점은 majority class에 대한 고려없이 적용했을 때 overlap이 있는 애매한 examples이 나올 수 있다
먼저 data를 balancing 하는 과정을 거쳐야한다.
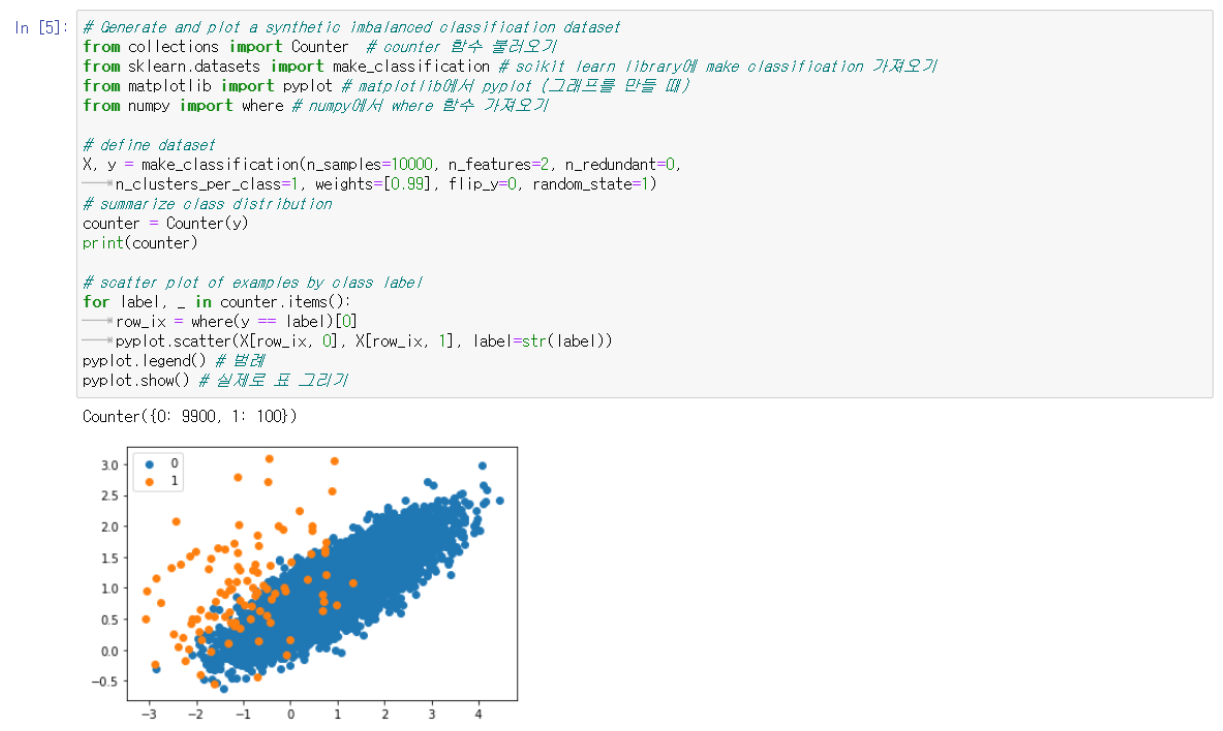
위의 코드를 통해서 minority한 부분 (100), majority한 부분 (9900)으로 나눠서 1:100의 binary classification의 dataset을 구성한다. 하지만 이런 dataset은 ML하기에 부적합하다.
여기서 우리는 minority class를 oversample 하여 두 class 모두 9900 개의 example을 만든다.
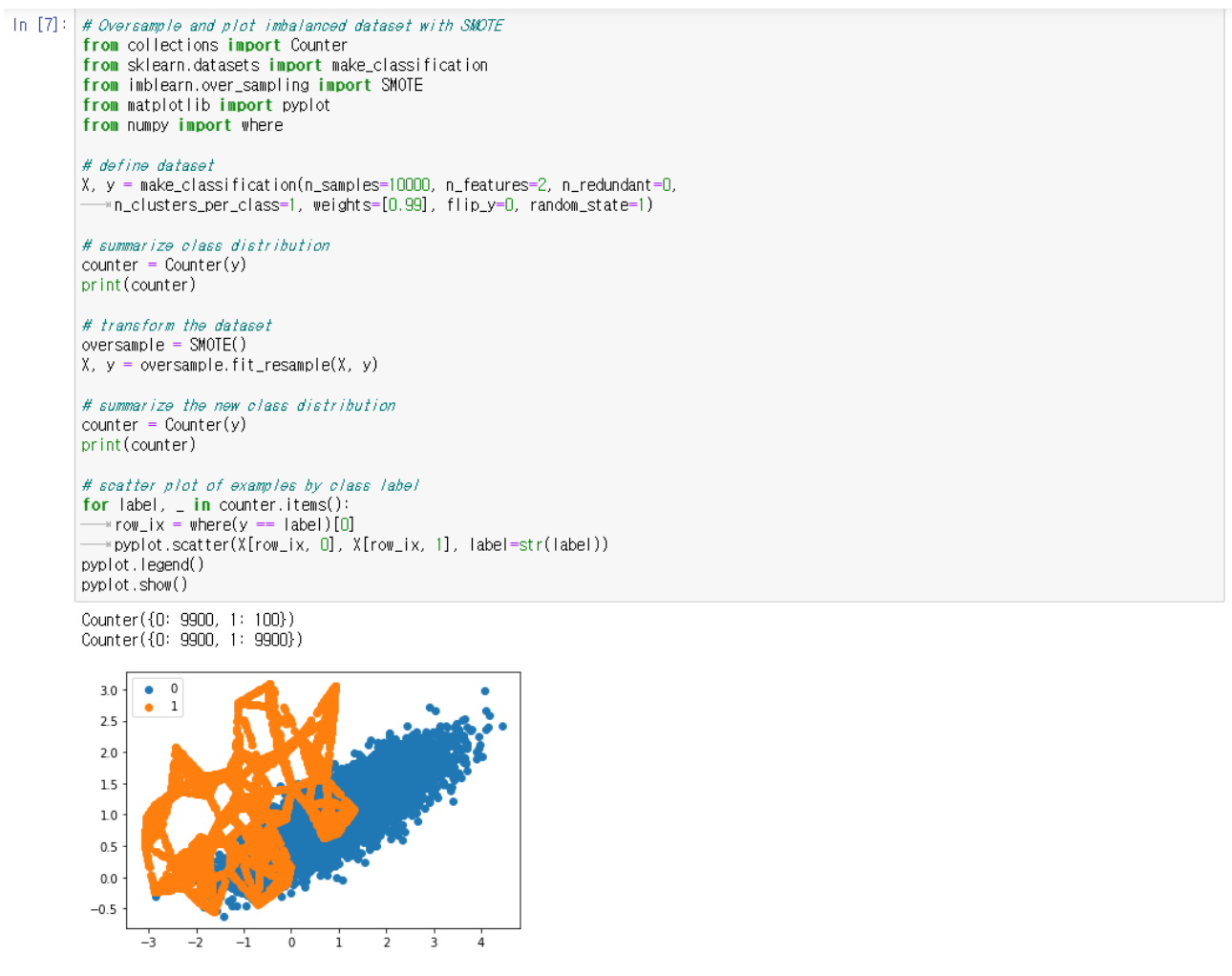
하지만 좀 더 효율적인 ML을 위해서 minority한 부분을 oversample해서 majority와의 비율을 맞춘다.
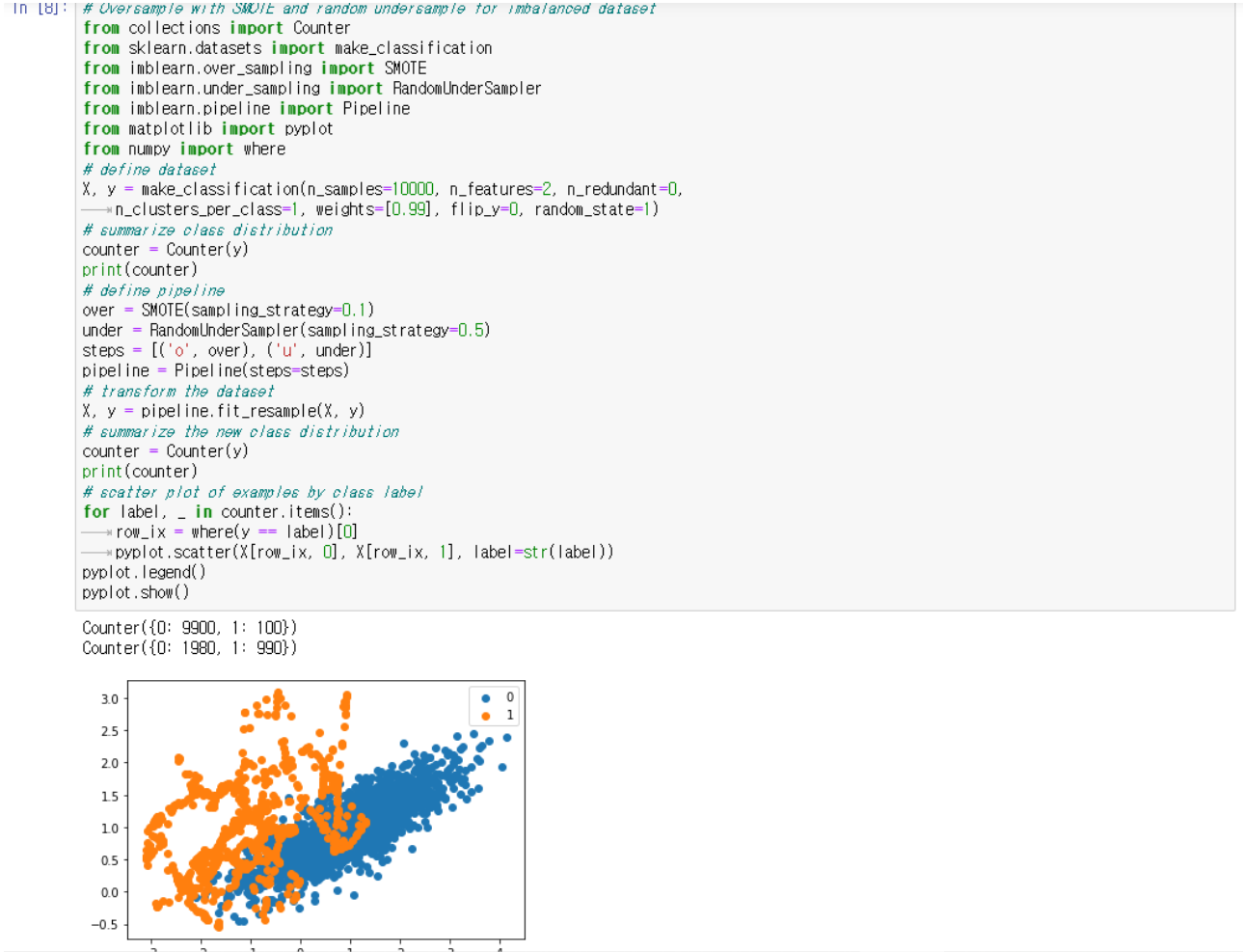
→ majority한 부분을 undersample하여 결과적으로 minority는 majority의 10프로에 해당하는 정도
→ majority는 minority에 비해서 50프로 많게 설정한다. 이 과정을 pipeline 과정이라고 일컫는다
SMOTE for classification
ML을 하기 전에 data preparation에서 SMOTE를 사용하는 과정이다.
모델 평가를 위해 k-fold cross-validation을 사용한다. 10-fold-validation을 3회 반복 (dataset에서 30개 모델 피팅, 평가를 3회진행)
ROC-AUC evaluation 과정을 거친다.
- Binary classification 한 자료 별다른 sampling 과정없이 decision tree를 거쳐서 classification을 한다.

-
SMOTE를 사용해 Oversample & Undersample 한 자료
Training dataset에 SMOTE oversample 과정을 거치고 random under sample 과정을 거친 뒤에 classification을 한다.
Oversampling의 올바른 적용은 훈련 dataset에만 방법을 적용한 다음 변환되지 않은 tests set에서 모델을 평가한다.
Binary classification 보다 소폭 향상된 ROC-AUC 결과를 보여준다.
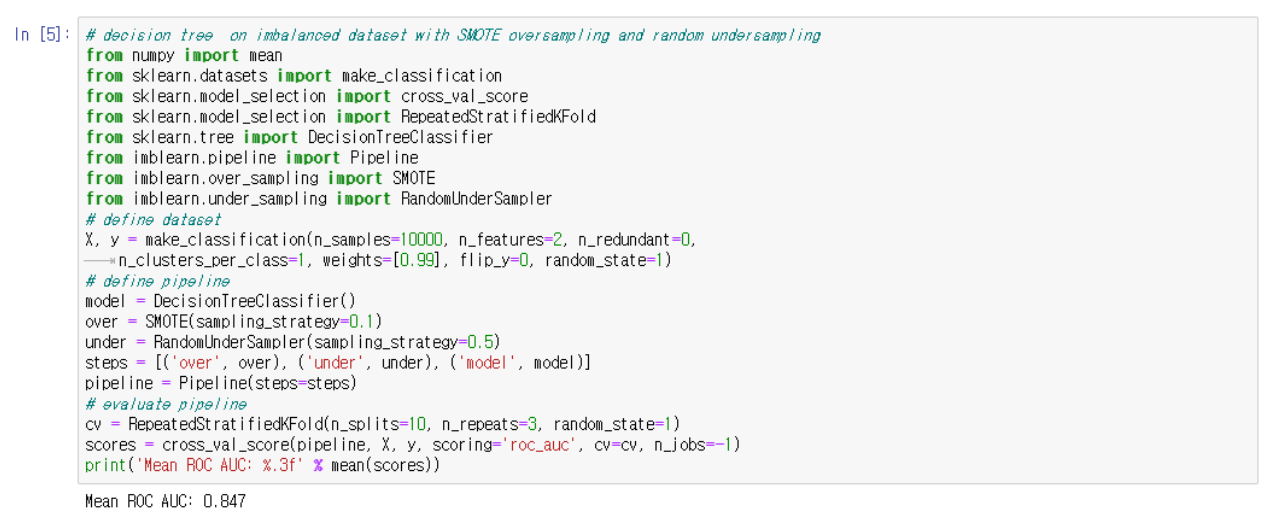
-
Oversample 과정에서 KNN을 사용한 후 Undersample을 한 자료
Oversample 할 때 k-fold cross validation 에 k의 범위를 바꿔가면서 진행한다. 결과적으로 k의 숫자가 달라져도 binary classification 자료보다 ROC-AUC의 수치가 높게 나온다.
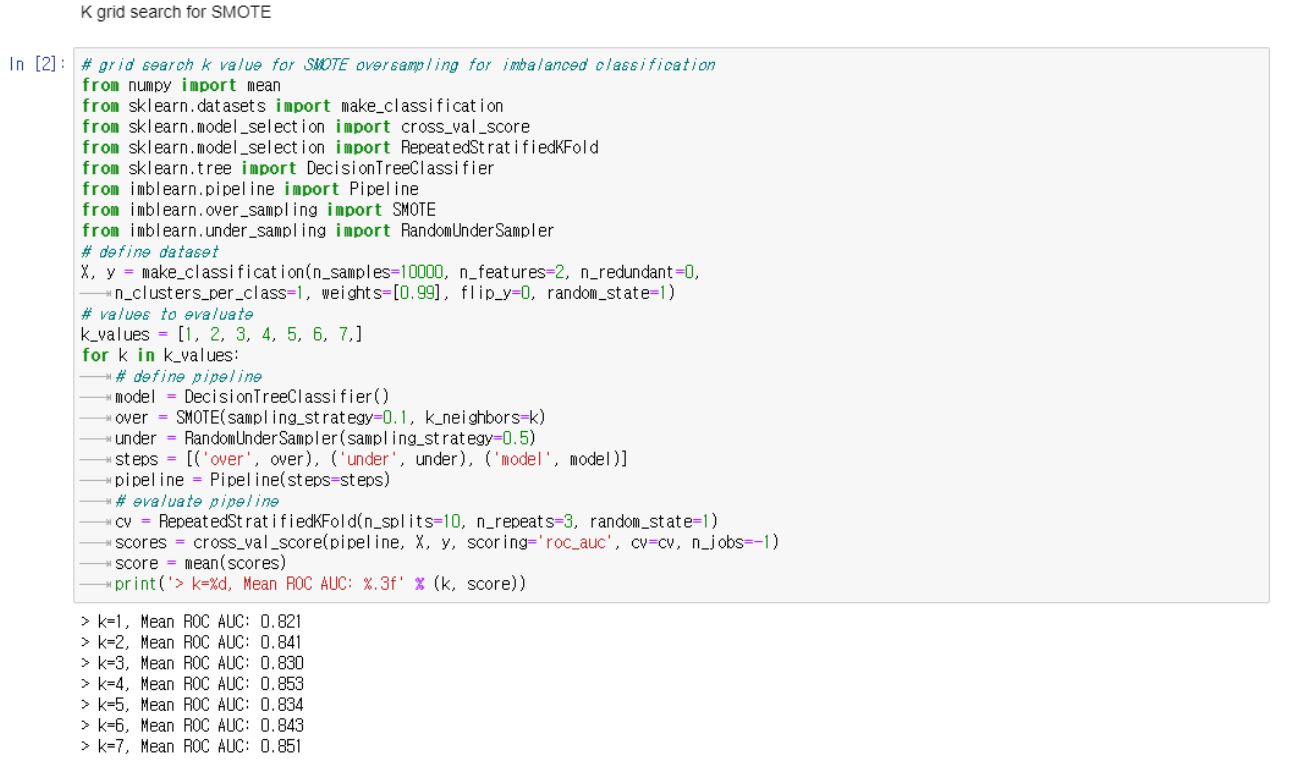
여기서 임의로 k의 값을 증가시켜도 ROC-AUC의 값은 높게 나온다.
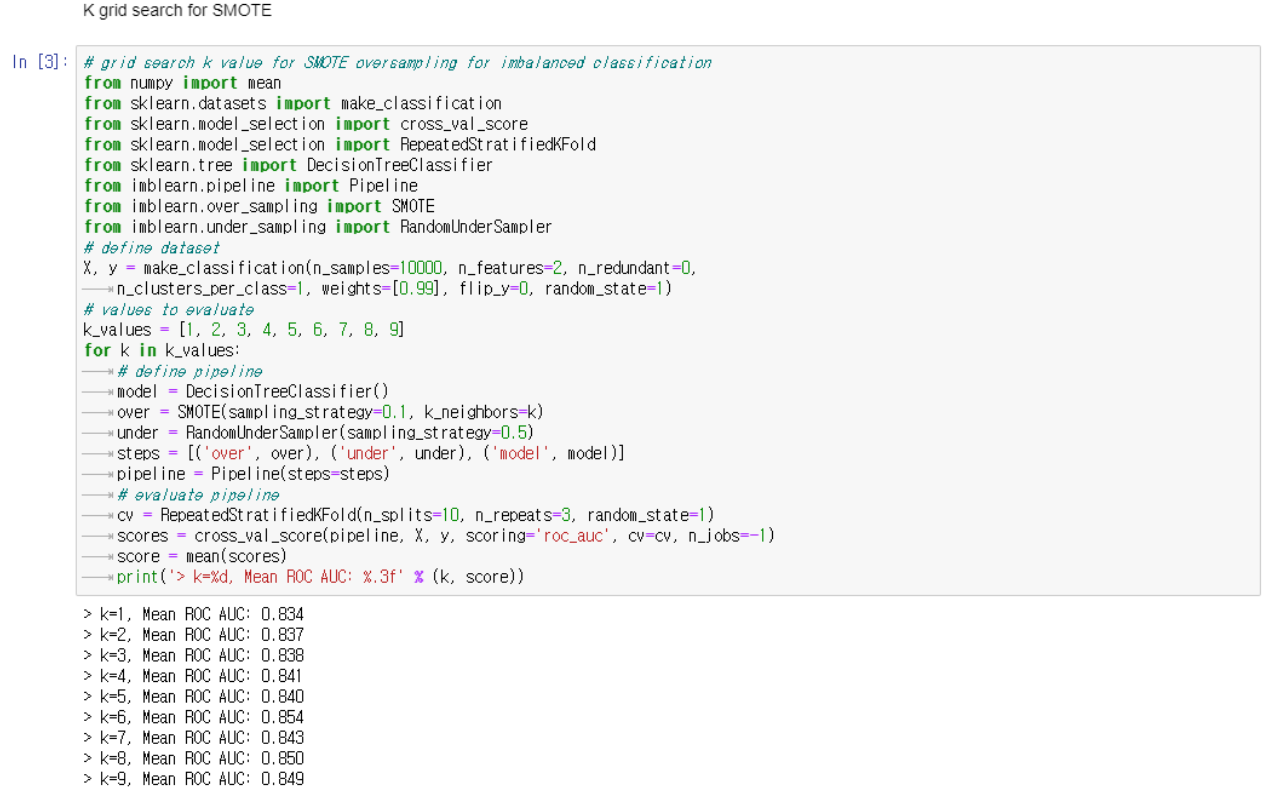
즉 oversample과 undersample 그리고 선택되는 examples의 갯수가 dataset을 선택하고 수정하는데 중요하다.
SMOTE With Selective Synthetic Sample Generation
SMOTE를 사용하여 oversample된 examples를 선택적으로 정할 수 있다.
-
Borderline SMOTE
두 class의 경계에 있는 examples들이 misclassification의 위험성이 있고 애매하다.
그래서 Minority class와 majority class의 경계인 부분을 따라서 oversample 하는 것이 목표. 그러나 단순히 minority class를 무차별적으로 oversample 하는 것이 아니다.
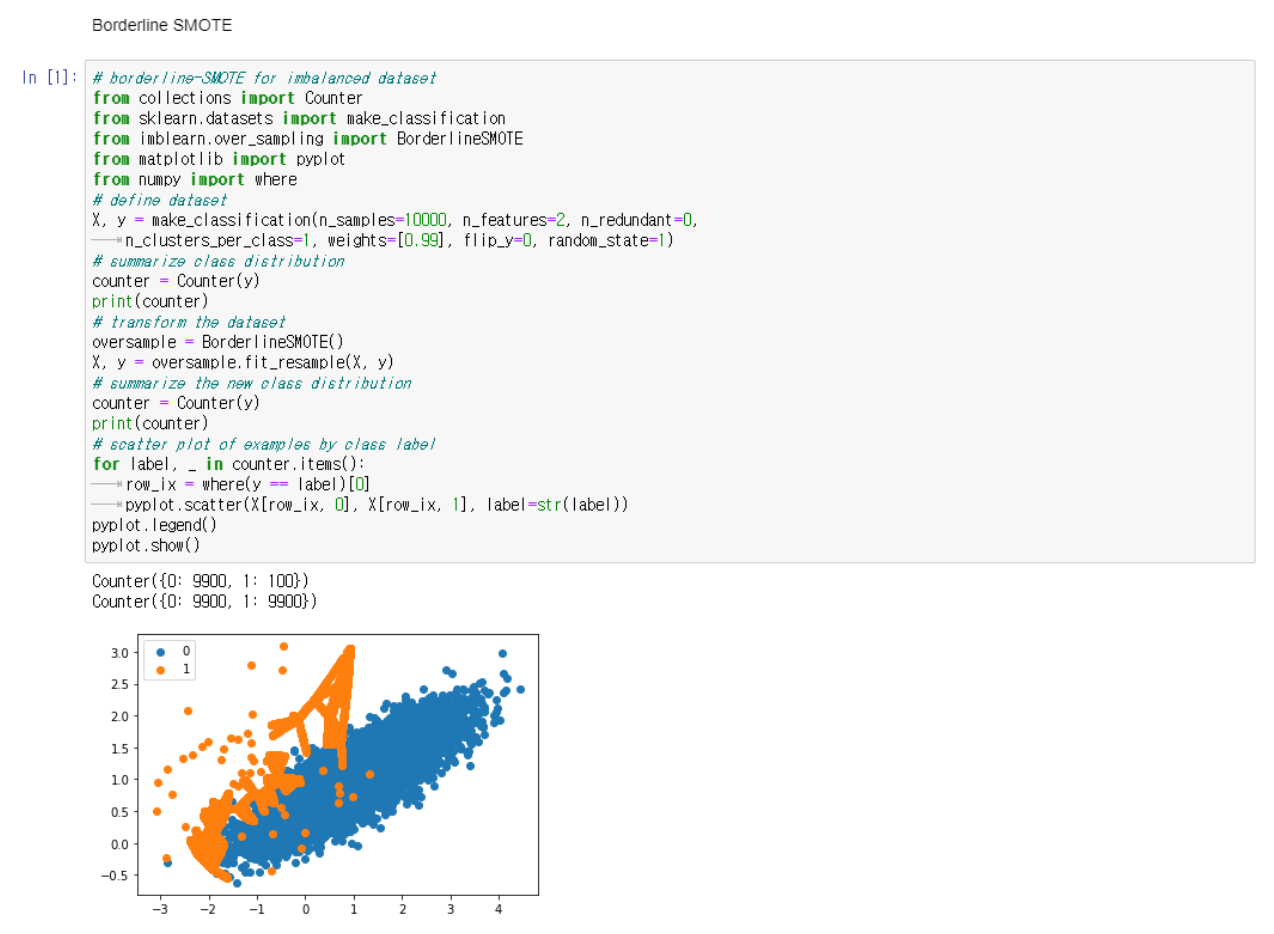
-
Borderline SMOTE SVM
앞선 방법과는 다르게 SVM의 방법을 거친다. SVM은 support vector를 통해서 decision boundary를 설정하는 알고리즘이다. 이 과정을 거친 뒤에 경계에 있는 support vector를 기점으로 minority class들을 oversample 한다.
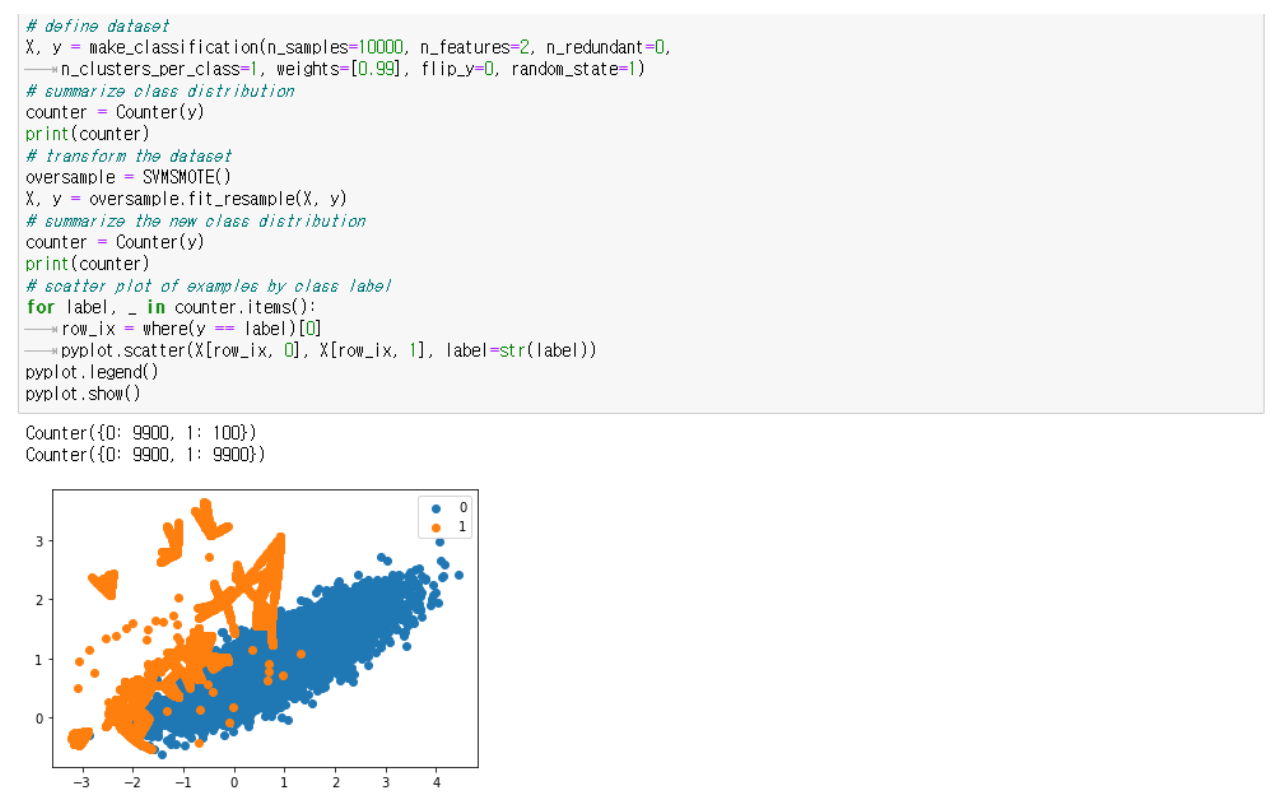
또한 minority class 중에서 적은 분포를 보인 example 들은 class boundary를 향해서 oversample 과정을 거친다 → 왜 그럴까?
- Adaptive Synthetic Sampling (ADASYN) → 이 방법의 핵심 기준은 class에 있는 example들의 밀도의 차이다. 밀도가 적은 부분에 더 focus를 두고 oversample 하는 과정이다. → 가장 lowest한 부분에 oversampling이 많이 일어난다. → 하지만 majority와의 overlap이 많이 일어남으로 overlap이 된 부분에 초점이 맞춰질 때 효율이 떨어진다. 해당 방법은 oversampling 과정 전에 outlier를 거를 수 있고 간편한 추론에 사용될 수 있다.
