스포츠AI 개론
Types of ML
Association Analysis (연관성)
Supervised Learning (지도학습) : 색깔이 칠해져있다
- Classification - Decision boundary를 통해서 구분, 새로운 data의 boundary를 아는 것이 목표
- Regression / Prediction
Unsupervised Learning (비지도 학습) : 누군가가 알려주지 않고 실행함
- Clustering
Reinforcement Learning (강화 학습)
KNN (K-Nearest Neighbors Algorithm)
지도학습시 거쳐가는 첫 알고리즘, 거리가 가까운 K개의 label 중 제일 많이 나오는 label을 선택
K가 작으면 noisy하고, K가 크면 smooth하지만 bias가 있고 비싸다.
지도학습시에 '감독하는 사람이 없어진다면 어떻게 하나?'를 생각해보고 접근하자.
장점
- 단순하고 feature와 거리에 대한 접근성이 좋다
- 표현이 잘된 데이터들은 적용이 잘된다
단점
- 고차원에서 힘들다
SVM (Support Vector Machine)
Decision boundary를 구하는 방법
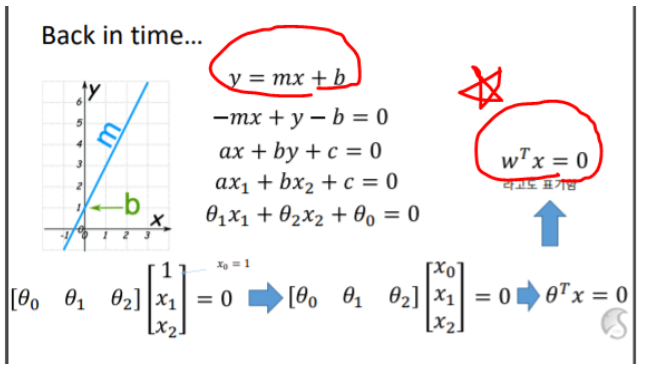
저 공식이 직선은 물론 plane, hyperplane 에서 나타낼 수 있다. Feature 역시 다양하게 나타낼 수 있다. Boundary를 잘 구분하기 위해서는 w를 잘 구하면 된다.
최적의 Decision boundary는 margin (떨어짐) 의 최대화
Margin = The distance between the decision boundary and the support vector
Support Vector = Decision Boundary에 의해 나눠진 각 영역에서의 example, 이걸로 margin이 결정된다.
장점
- 효율적인 메모리 - support vector만 있으면 된다.
- 영역이 확실히 구분될 수록 효과적
- sample의 수 보다 데이터 차원이 높아도 효과적이다. (차원의 저주로부터 자유로움)
Q. 그러면 Data는 평면에 표현되는데 굳이 선형적 학습이 적합하다고 해서 평면이 아닌 선형적으로 학습 시킬 필요가 있나? 비용 때문에?
Kernel trick의 경우?는 반대인가
- 고차원에서 더 효과적 (KNN과 다름)
단점
- 큰 데이터에 적합하지 않음 (Support vector를 골라내는 과정이 어려울 수 있다)
- Noise가 큰 데이터는 효과적으로 처리하지 못함
Q. Bias와 variance는 서로 반대의 개념인건 이해가 되는데 왜 variance를 줄이는데 noise가 필요한가?
A. Overfitting을 막기 위해?- 공간에 대한 해석은 제공하지만 확률적인 설명은 부족하다
KNN vs SVM
KNN vs SVM :
- SVM take cares of outliers better than KNN.
- If training data is much larger than no. of features(m>>n), KNN is better than SVM. SVM outperforms KNN when there are large features and lesser training data.
Q.Data, feature, sample의 차이점
C-SVM
margin안에 관측치가 존재할 수 있도록 제약을 완화하는 방안 (soft margin)
c 값이 크면 허용 x (hard margin)
대신 허용하되 penalty 값이 있다
Kernel trick
원공간(input space)의 데이터를 선형분류가 가능한 고차원 공간으로 매핑한 뒤 두 범주를 분류하는 소평면을 찾는다.
Radial Basis Function
reference 꼭 참고하기!!
Decision Tree
확실하게 분류되었을 때 Entropy가 낮다 (한쪽으로 쏠려있다는 느낌)
데이터가 섞여있으면 purity (information gain)가 낮아지고, 섞이지 않으면 purity가 높아짐 대신 equally mixed일 때 엔트로피가 제일 높다
cf) Gini Index
→ DT는 순도 증가와 불확실성을 줄이기 위한 방향으로 학습을 진행한다
좋은 attribute를 선정하는 것이 중요하다 = information을 get했다는 의미
SVM과 달리 feature 단위로 구분한다
XOR 문제
Perceptron
여러개의 입력을 받아서 하나의 출력을 낸다.
N개의 결합층이 있으면 N개의 perceptron이 있다.
각각의 입력신호와 그 고유한 가중치를 곱한 값은 모두 더한 것이 '내적'이라고 하고 그 값이 threshold가 넘는지를 구분한다.
활성화 함수 (activation function)
- Step 함수
- Sigmoid 함수: firing rate = output, 0~1 사이의 값, saturated
- Relu 함수
- tanh 함수: zero-centered
입력변수가 1개면 직선(linear), 2개면 평면, 더 많아지면 고차원적인 평면을 자르는 것으로 생각할 수 있다.
Q. Regression vs Classification
Multi-layer perceptron
Input, Internal Representation Units, Output
