한 기업의 코딩테스트 문제 중 논문의 한 부분을 구현하는 것이 있어 정리겸 포스팅한다.
나는 그 중 2.1 Integral Image 만 구현하면 되서 전체적으로 안읽고 대강 흐름대로 읽은 후 이 부분만 주의깊게 읽었다.
전체적인 시스템은
기존의 detect 연구들보다 뛰어나다는 이야기를 한다.
주요 3가지 기여한 점은
1) Integral image
2) Adboost
3) Cascaded Classifier
이렇게이다.
2.1 Integral Image
앞선 2. Features 를 읽어보면 본 논문의 Face detection 절차는 features의 값에 기반하여 image를 분류한다. pixel값으로 직접 이용하기 보다는 feature를 이용하는 것
본 논문에서는 simple feature는 Papageorgiou et al. (1998)가 사용한 Haar basiss fuction을 사용하여 integral image를 연상한다.
- two-rectangle feature의 값은 두 개의 직사각형 영역 사이의 픽셀들의 합에 대한 차이를 구함
- 영역은 동일한 크기 및 모양을 가지고 있고, 수평 또는 수직적으로 인접한다.
- three-rectangle feature는 대각 사각형의 차이를 계산한다. 대각 사각형의 흰색 영역에 대한 합과 대각 사각형의 검은색 영역에 대한 합의 차이를 의미
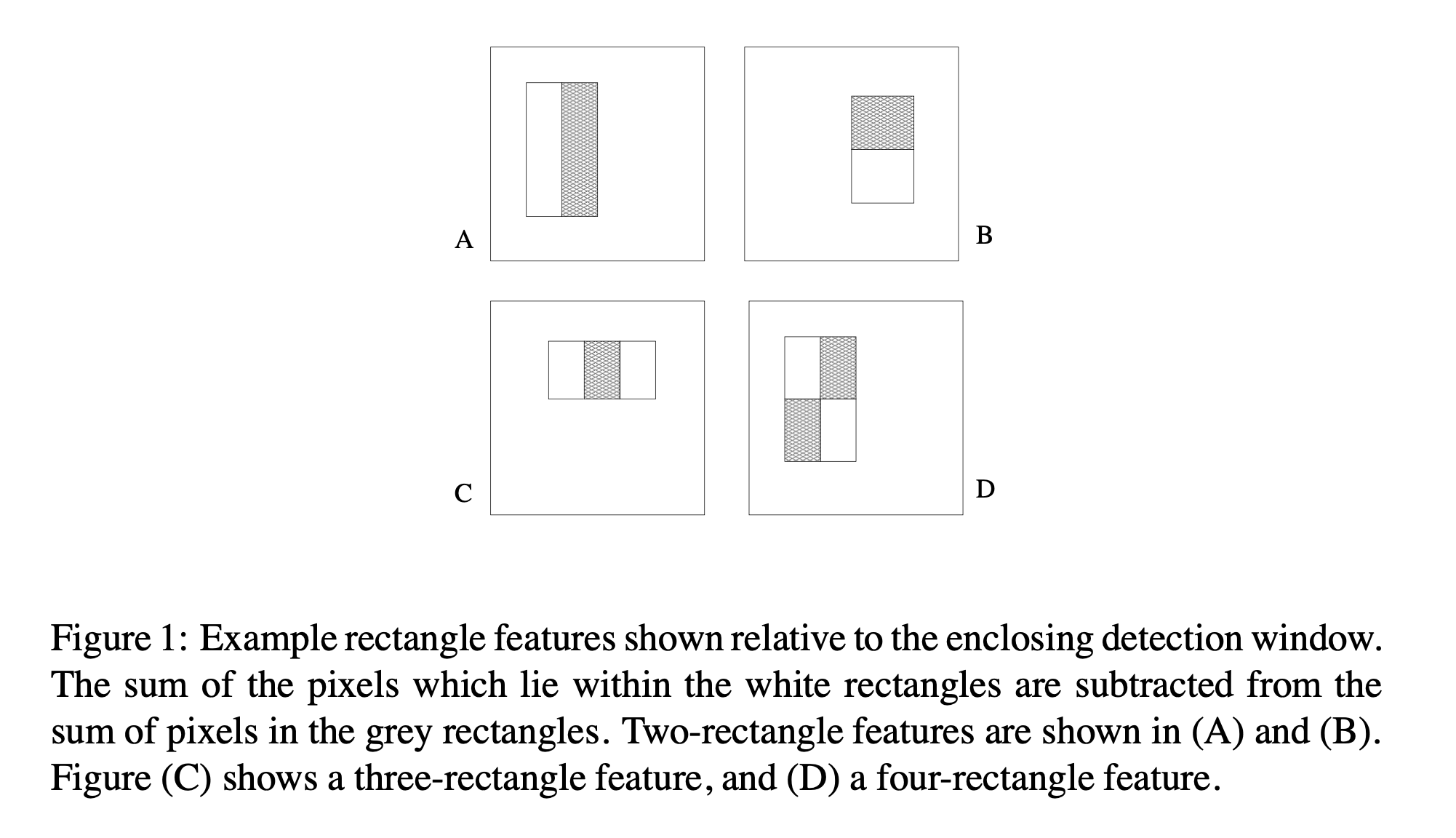
계산 과정은 다음과 같다.
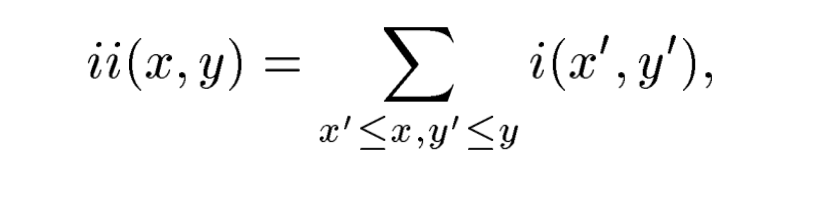
ii(x,y): integral image, i(x, y): original image
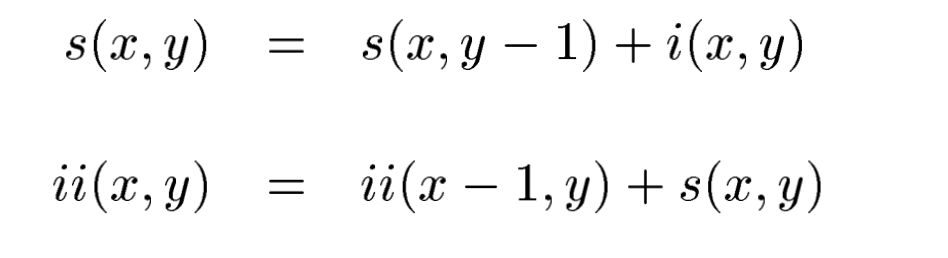
s(x,y): row에 대한 누적 합, s(x, -1), ii(-1, y) = 0.
integral image는 원래 image에 대해서 One pass만으로 계산 가능
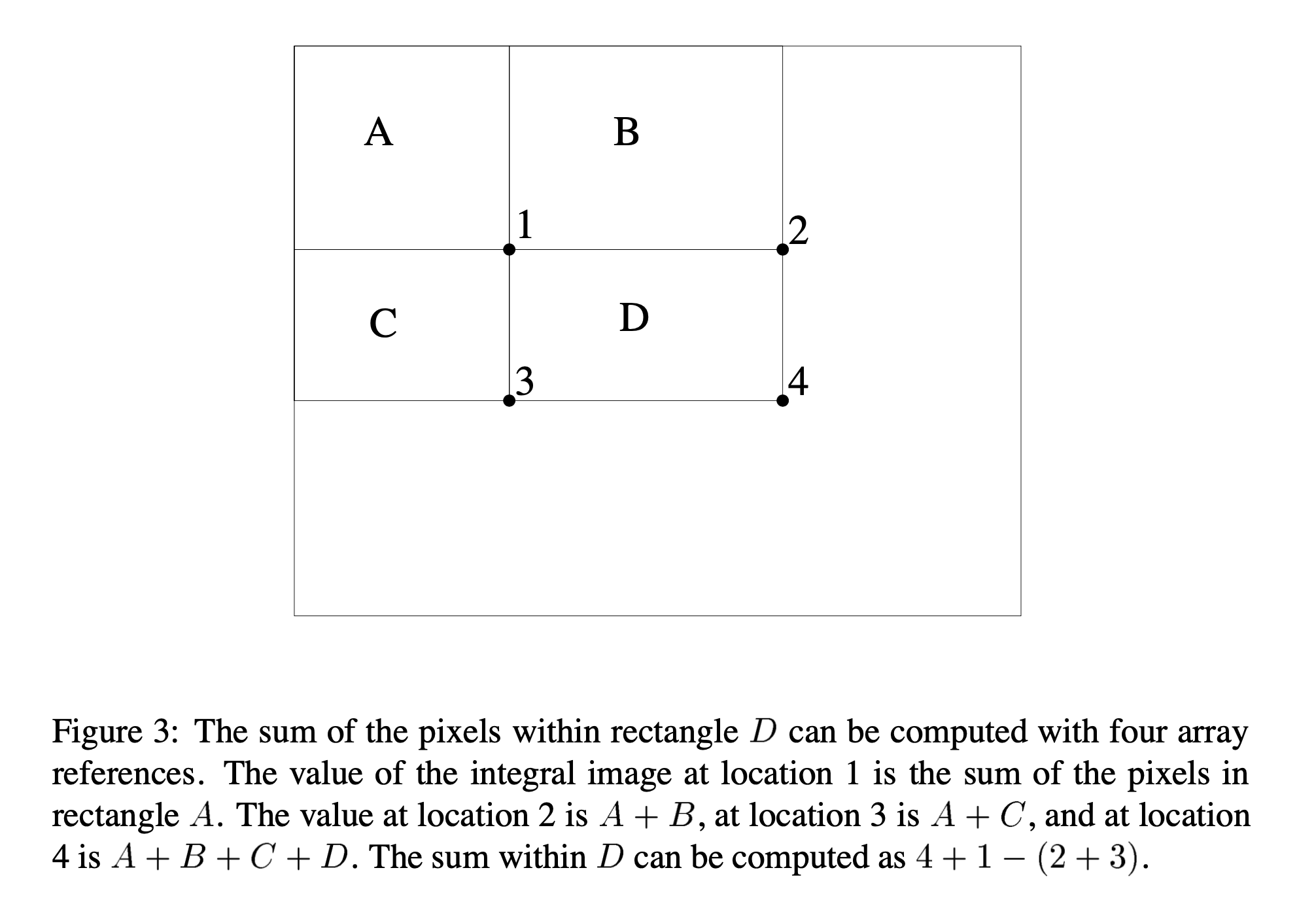
따라서 figure 3과 같이 1은 사각형 1의 Pixel들의 합, 2 는 A+B의 합, 3은 A+C의 합 4는 A+B+C+D의 합이다 따라서 D의 합은 4+1-2-3이 된다.

이 그림은 The Viola-Jones Algorithm 정리한 yutube영상 이다.
위 그림과 같이 harr basis function을 사용한 직사각형에 original pixel값이 있는 image에 놓아 검정 영역과 흰영역의 합을 구한다.
본 이미지는 흰색 영역의 합을 구해 놓았는데 여기 합은 총 8번의 계산이 걸린다.
그러나, integral image의 경우 총 4번의 연산으로 끝난다.
