개과천선
이번 프로젝트를 요약한 말이다.
첫번째 프로젝트는 리더보드 순위는 높았지만 협업 과정, 개발 과정에서 아쉬운 점이 많았다.
꼼꼼한 회고, 그리고 앞으로 어떻게 할 지에 대한 how-to를 생각하고 적용해 이번 프로젝트는 개발자답게 진행할 수 있었다.
결과적으로 리더보드 1위를 달성했다

협업을 어떻게 했는지에 대한 내용, 그 다음 개발을 어떻게 했는지 + 앞으로 어떻게 더 발전시킬 지에 대해 기록하려고 한다.
[WIL] 1. 개발자처럼 깃헙 사용하기
프로젝트 초반에 브랜치 전략, 깃헙 컨벤션, 코드 컨벤션을 명확하게 세팅해두었다.
-
브랜치 전략을 다음과 같이 세웠고,
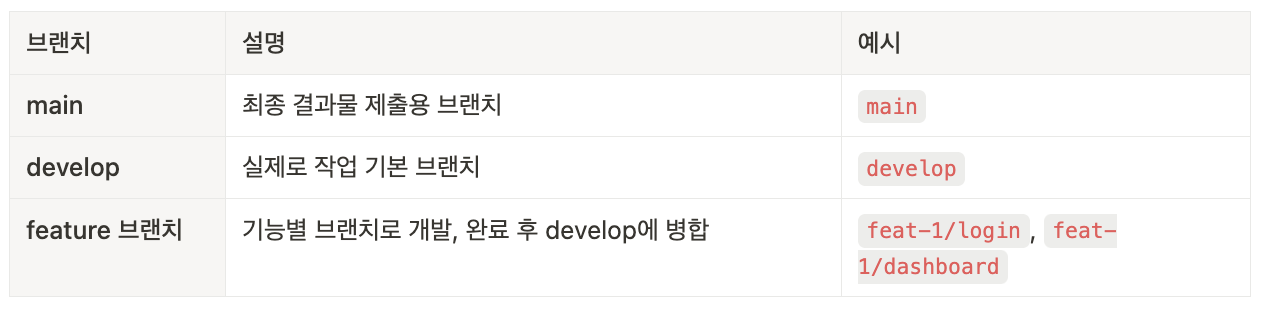
-
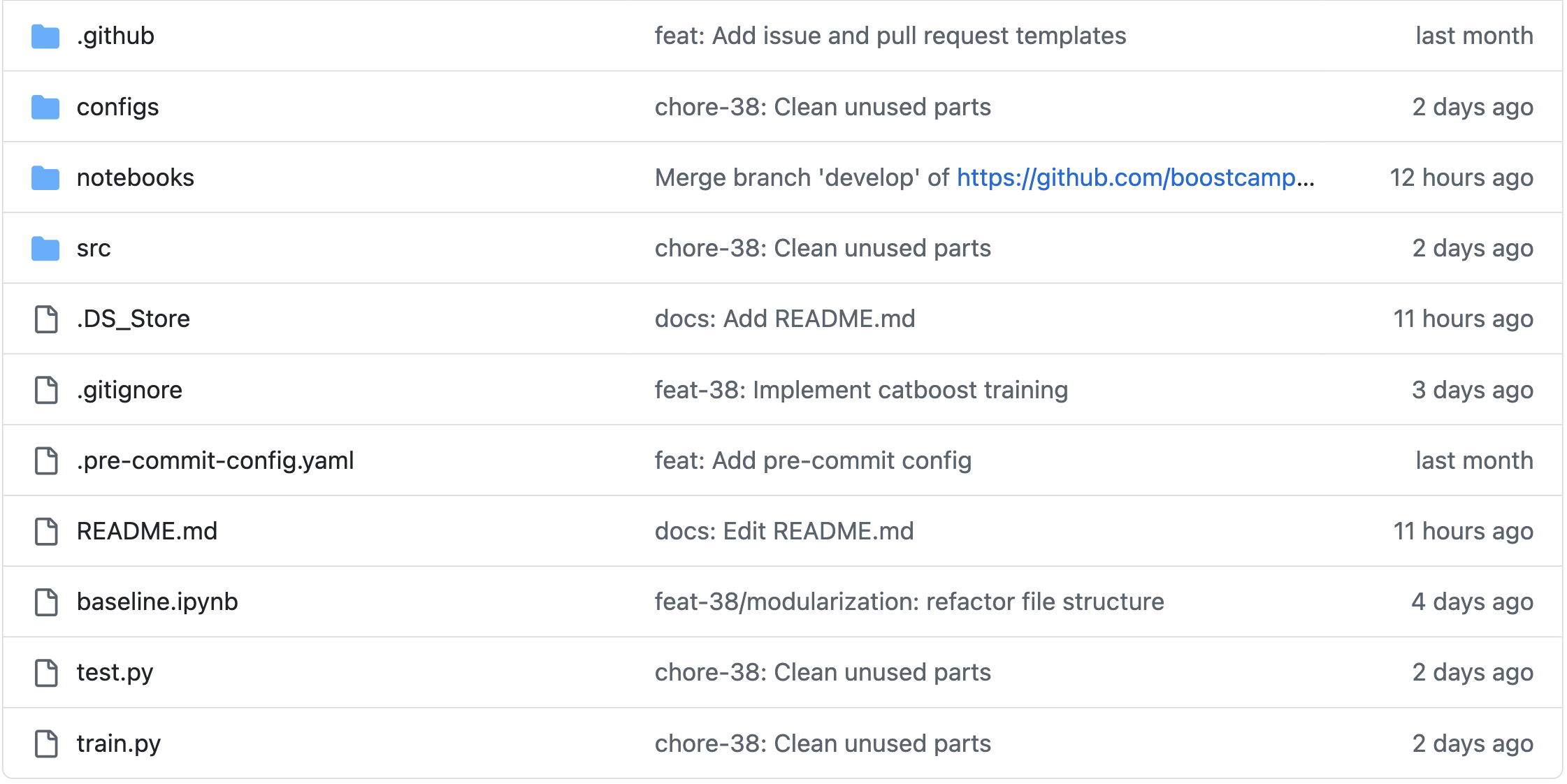
실제로 아래와 같이 활용한 걸 Git Graph를 통해 확인할 수 있다. 수많은 실험을 진행하다보니, 한 시점에 6개의 형형색색의 브랜치가 생기기도 했다.

-
커밋 메시지에 대한 convention을 아래와 같이 마련하였는데

-
대체로 잘 지켜진 것 같다. 특히 커밋메세지의 바디와 이슈 태그를 잘 활용해 다른 팀원의 진행상황을 트래킹하기 편리했다.
-
이슈, PR 템플릿도 초반에 아래와 같이 계획을 짜고

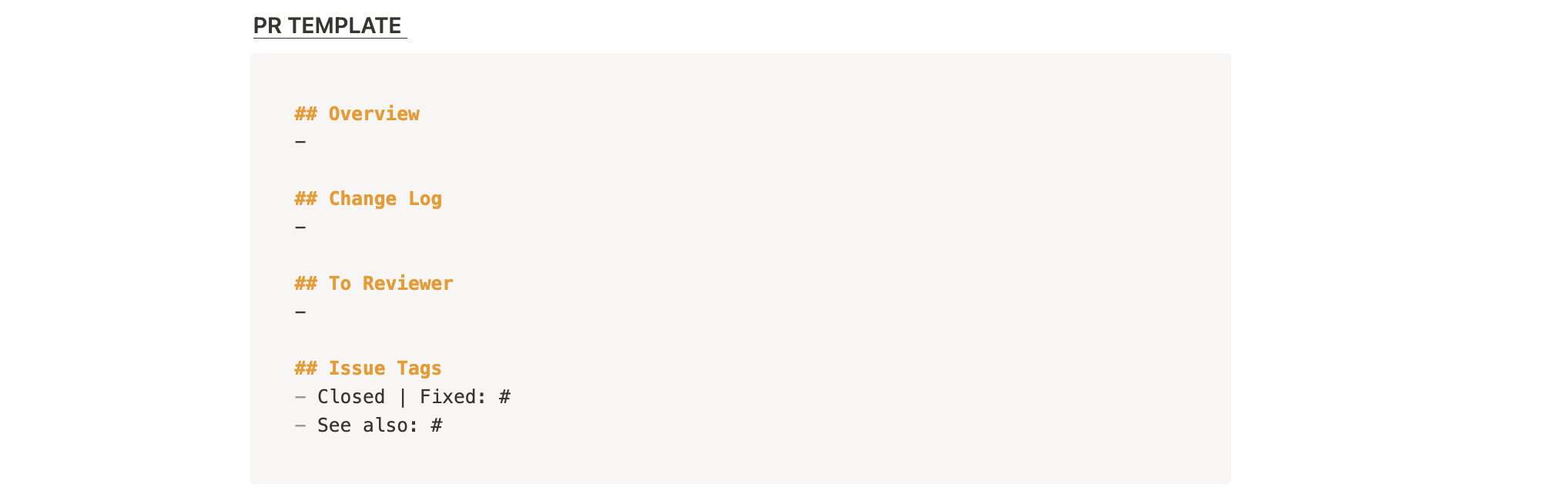
-
실제로 잘 써먹었다. 이슈 쓸 때마다 얼마나 적어야할 지 감이 잘 안왔었는데, 양식이 통일되니 편리했다.
또한 팀원별로 담당한 실험의 진척과 세부사항을 Git Issue 를 통해 확인하기 쉬웠다
ex. 새로운 피처에 대한 실험, 새로운 모델링 기법에 대한 실험 등
그럼에도 불구하고, 아쉬운점은 있다.
- Pre-commit 기능을 충분히 이해하고 활용하지 못했다.
주말동안 <개발자처럼 git 활용하기> 강의를 다시 보며, 다음 프로젝트에서 적극적으로 사용해야겠다.- Discussion의 경우, 노션과 그 사용목적이 조금 겹쳐 거의 활용하지 않았다.
다음 프로젝트때에는 회의록은 노션에, 그 외에 실험 기록은 Git Discussion에 기록하는 것이 좋겠다.
[WIL] 2. WandB
- Weight & Bias 팀 스페이스를 생성했다.
기존에 노션 테이블에 수기로 하나하나 작성했던 실험 세팅(epoch, hyperparamter 등)과 결과(mae, feature importance)등을 자동으로 기록할 수 있었다. - 특히 permutarion feature importance와 같의 하나의 실험 내에서 여러 변인이 존재할 때 하나의 플랏에 취합해 가독성을 높일 수 있었다.
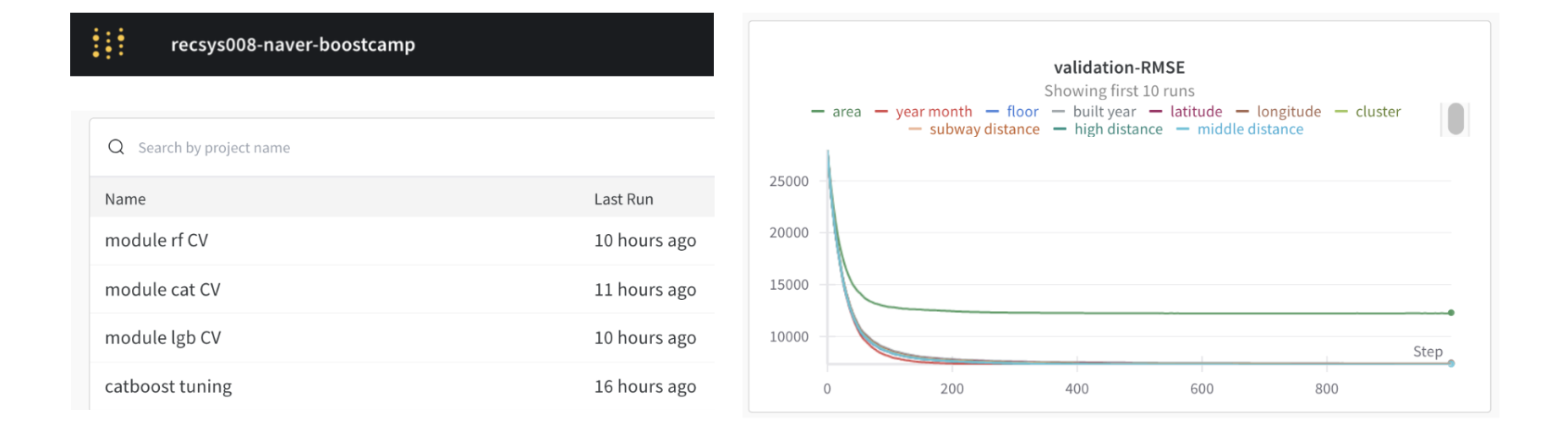
아쉬운점
Cross Validation 에서 어떻게 오류 없이 WandB를 활용할 수 있는지, 팀원이 해결해주긴 했지만 스스로는 이해하지 못했다.
다시 코드를 보며 '이해'할 수 있도록 하자.
[WIL] 3. 모듈화
- 플젝 중간즈음부터 전처리, 피처 엔지니어링 등을 함수로 모듈화하였다.
- 플젝 마무리 단계부터 본격적으로 디렉토리 구조도를 짜고, EDA를 제외한 나머지를 ipynb에서 py파일로 변환하였다.

- 실제로 아래와 같이 반영하였다
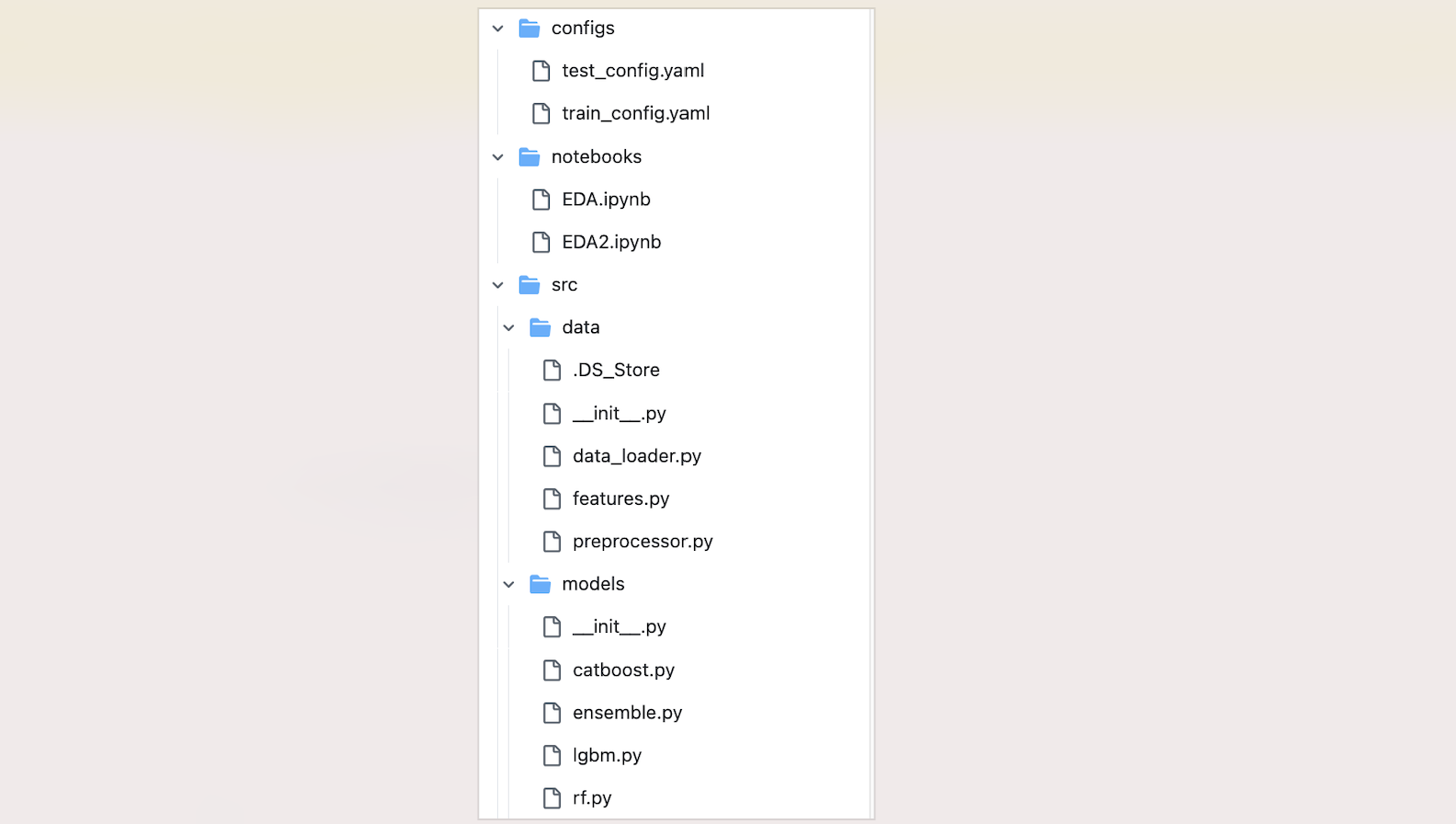
아쉬운점
- 미리 디렉토리 구조를 짜고, 미리 py파일로 개발했더라면 프로젝트 마지막에 이렇게 머리를 싸매지는 않았을 것 같다. 이미 ipynb로 짜놓은 파일에 대해 다시 파일 구조도를 짜고, 함수로 바꾸고 하는 과정이 꽤나 골치 아팠다.
- 디렉토리 구조도를 설계하는 것에도 나름의 노하우가 있다. 우리의 레포, 파잍치 템플릿 레포, 다른 팀들의 레포를 보며 분석해보자. 구조 + 각 파일에서 꼭 지정해주어야 하는 것은 무엇이 있는 지 등
- 아직 완전히 이해하지 못한 것들
: argparse, _ init _, config file, class → 꼭 공부하고 넘어갑시다!
[WIL] 4. 클러스터링으로 Data leakage 없이 새로운 변수를 만드는 방법
- 다음과 같은 이유로 클러스터링 변수를 만들었는데,
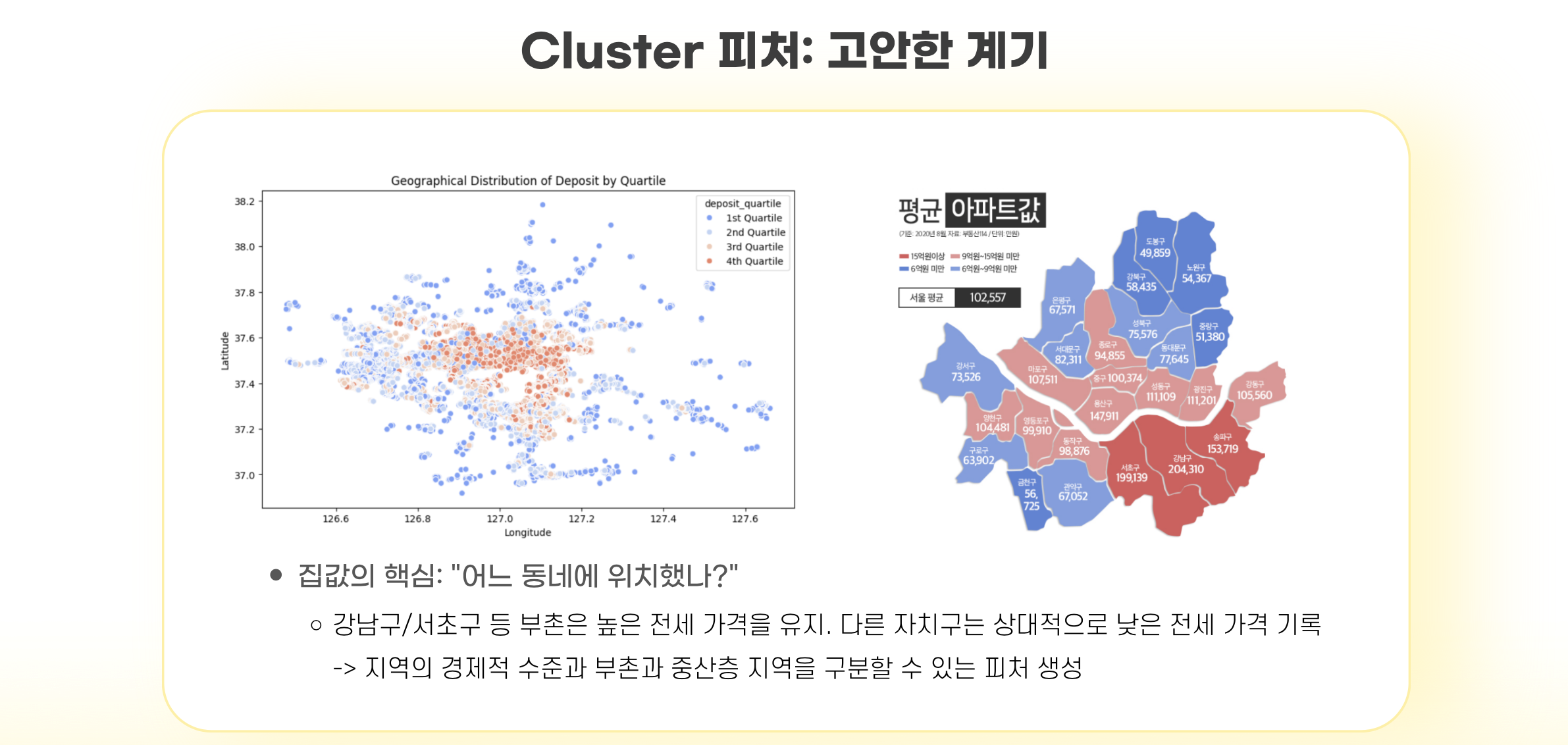
- train과 test에 일관된 클러스터링을 적용하려면 데이터를 합쳐서 한 번에 클러스터링해야한다.
BUT, 이 경우 Data Leakage 문제가 생길 수 있다. train데이터의 정보가 클러스터링에 반영되기 때문 - 따라서 다음가 같은 전략을 사용했다. 모델의 복잡도를 고려해 방법 2를 채택하였다.
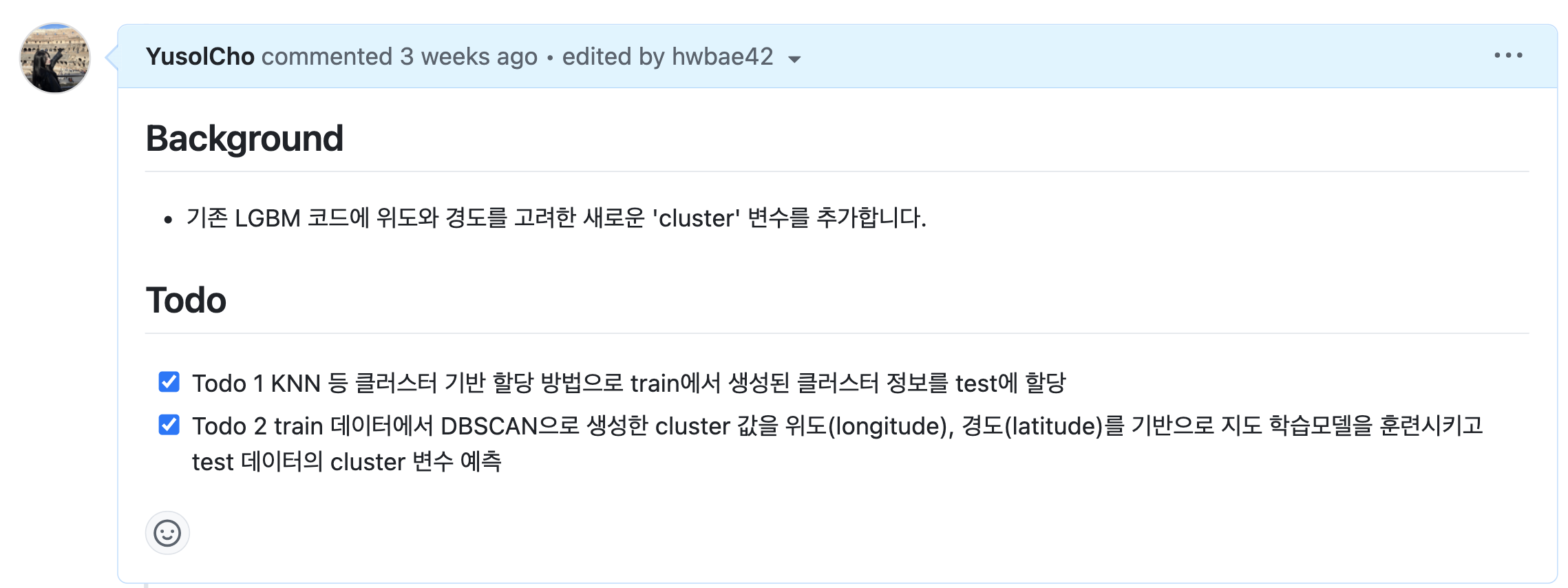
방법 1. train 데이터에서 생성한 cluster값을 위도, 경도를 기반으로 지도 학습모델을 훈련시키고 test 데이터의 cluster 변수 예측하기
방법 2. train 데이터에서 생성한 cluster들의 centroid를 사용해 KNN 기반으로 test 데이터의 cluster 값 구하기
train의 클러스터들의 centroid에 대해 KNN을 적용해 test의 클러스터 생성
- 코드 첨부하기
- 코드 주석 달기
- 짧은 해석 달기
[WIL] 5. DBSCAN으로 디노이징하는 방법

- DBSCAN으로 디노이징을 어떻게 하는지에 대한 개괄적 설명
- 코드 첨부 + 주석달기
- 코드에 대한 짧음 해석
아쉬운점
클러스터 변수를 이용한 전후 성능평가. 결과 해석. 못 씀. 왜 못쓰게 되었는지에 대한 이유 설명
[WIL] 6. TabNet
탭넷에 대해 새로 알게 된 점 간략하게 소개
아쉬운점
옵튜나로 파라미터 조정하고 싶었는데, 모델 돌릴 때마다 오래 걸려서 시간이 부족.
항상 그냥 모델 돌리기 전에 옵튜나 돌리고 모델을 돌리는 게 효율적일듯 함
그리고 에포크 돌릴 때 wandb 기록이 에포크마다 실시간으로 안되는 문제가 있었음
아직 wandb 에 대한 이해가 부족한 것 같음. 이유를 찾아보며 더 잘 이해해보자
그 외에도,
옵튜나 활용 방법, Soft Voting 앙상블, Stacking 앙상블과 메타모델, K-fold CV, K-fold CV 기반 Soft Voting 앙상블, LGBM, Catboost 등 트리기반 모델의 하이퍼파라미터 등 많은 것들을 배울 수 있었다.
