[1] RNN과 Gradient Flow 문제
RNN, 왜 필요할까?
기본적으로 RNN은 시계열 데이터를 처리하기 위한 모델이다. 기존의 다른 딥러닝 모델들은 독립적인 입력값에 대한 예측값을 반환한다. 따라서 Sequence 데이터의 처리를 위해 RNN이 고안되었다.
RNN은 어떻게 작동하는가?
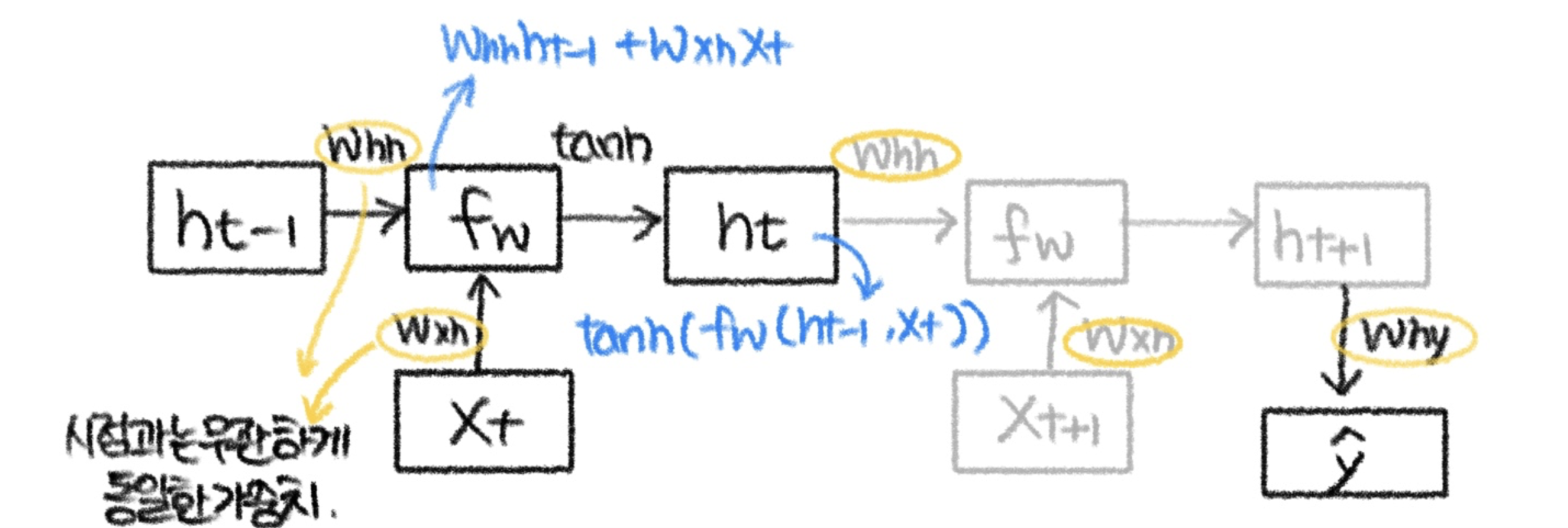
- 핵심은 이전시점의 output이 다시 현재시점의 input으로 사용된다는 건데,
- 순전파에서는,
인풋과 전 단계의 hidden state에 각각의 가중치를 곱한다.
그리고 그걸 더해서 activation function(tanh)에 넣는다.
그 값을 다음 단계의 hidden state로 내보낸다. - 역전파에서는,
현재의 hidden state를 전단계의 hidden state에 대해 미분한다.
Vanilla RNN은 왜 현업에서 잘 안쓰일까?
RNN은 고정되지 않은 길이의 Input Sequence 처리 가능하며, 특정 시점에서 여러 단계 이전의 정보를 사용할 수 있다는 장점이 있다. 추가로 input x_t에 관계 없이 항상 같은 weight parameter를 이용하기 때문에 문장 기억에 효과적이기도 하다.
하지만 우리가 주목할 것은 단점이다. RNN은 단점이 매우 확실하고 치명적인데,
첫째, 병렬화가 불가능하며 Computation이 비싸다. 마치 재귀함수처럼 자신의 output을 다시 input으로 받는 Recurrent 구조를 가지기 때문이다.
둘째, Vanishing gradient/exploding 문제가 존재한다.
셋째, RNN의 Many-to-Many구조는 현실 데이터 모델링에 부적절하다
(예시) "I am Yusol"은 "나는 유솔이야"로 번역 가능하다. 이렇게 간단한 문장인데도 벌써 입력과 아웃풋 길이가 각각 2, 3으로 다르다.(인풋과 아웃풋은 1:1 대응관계를 이루기 힘들다)
* 해결책: Seq2Seq
Vanilla RNN의 기울기 문제
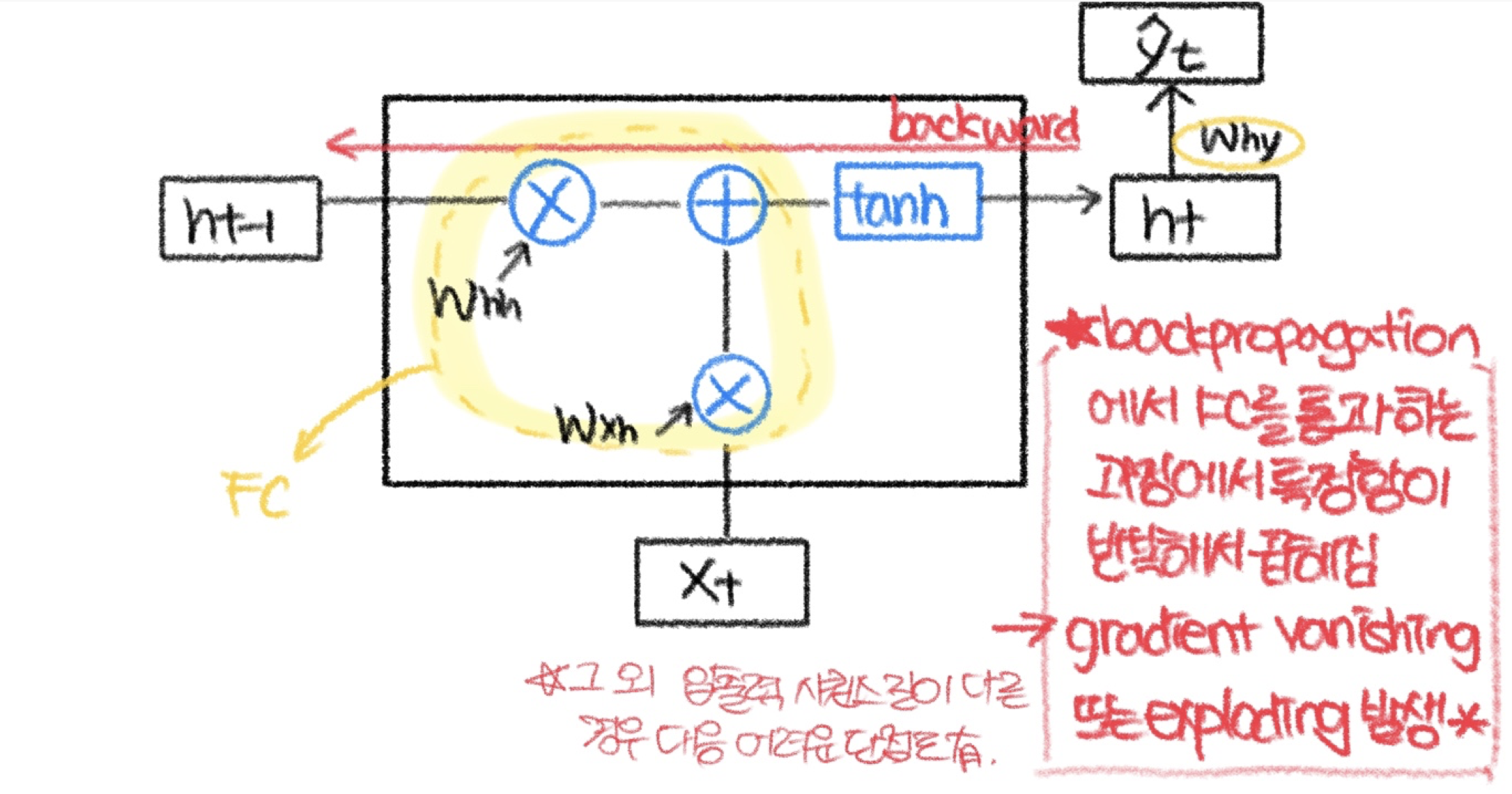
h_t(t시점의 hidden state)에서 h_t-1로 역전파를 수행할 때에 아래 수식에서 볼 수 있는 W_hh가 곱해진다. 근데 역전파를 계속 수행함에 따라 이 W_hh가 입력 sequence의 길이만큼 곱해지게 된다. 이렇게 동일한 행렬이 반복적으로 multiplication되는 경우 다음 두가지 문제가 생긴다.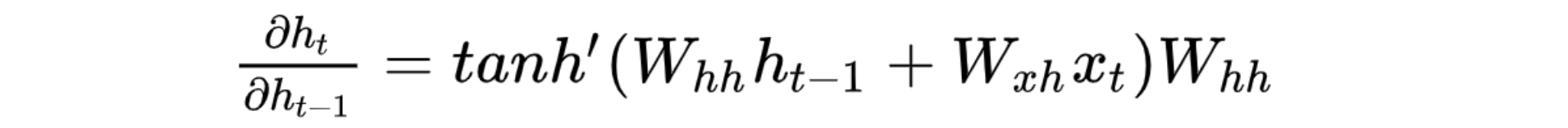
1. Exploding Gradient 문제
가장 큰 특이값 > 1 인 경우 누적하여 곱해짐에 따라 Gradient는 Explode한다. 즉, 큰 가중치는 극단값으로 발산한다.
2. Vanishing Gradient 문제
가장 큰 특이값 < 1 인 경우 누적하여 곱해짐에 따라 Gradient는 소멸된다. 즉, 작은 가중치는 0으로 수렴한다.
정리)
RNN의 Backpropagation에서 FC(fully connected layer)를 통과하면서 같은 weight parameter가 입력 sequence만큼 곱해지기에 gradient vanishing/exploding 문제가 발생한다.
그게 왜 문제일까??
: 시퀀스 내 장거리 의존성(long-term dependency)를 모델링하는데 실패 → 여러 단계 이전의 정보에 접근하기 매우 힘들다.
해결책은 없나?

Solution 1. Gradient Clipping
큰 Gradient는 최대값(threshold)으로 클리핑되며, 각 Dimension은 기울기 방향을 유지하기 위해 비례적으로 축소된다. Exploding만 해결할 수 있는 줄 알았는데 Vanishing Gradient도 해결 가능하다고 한다.
Solution 2. LSTM, GRU
[2] LSTM
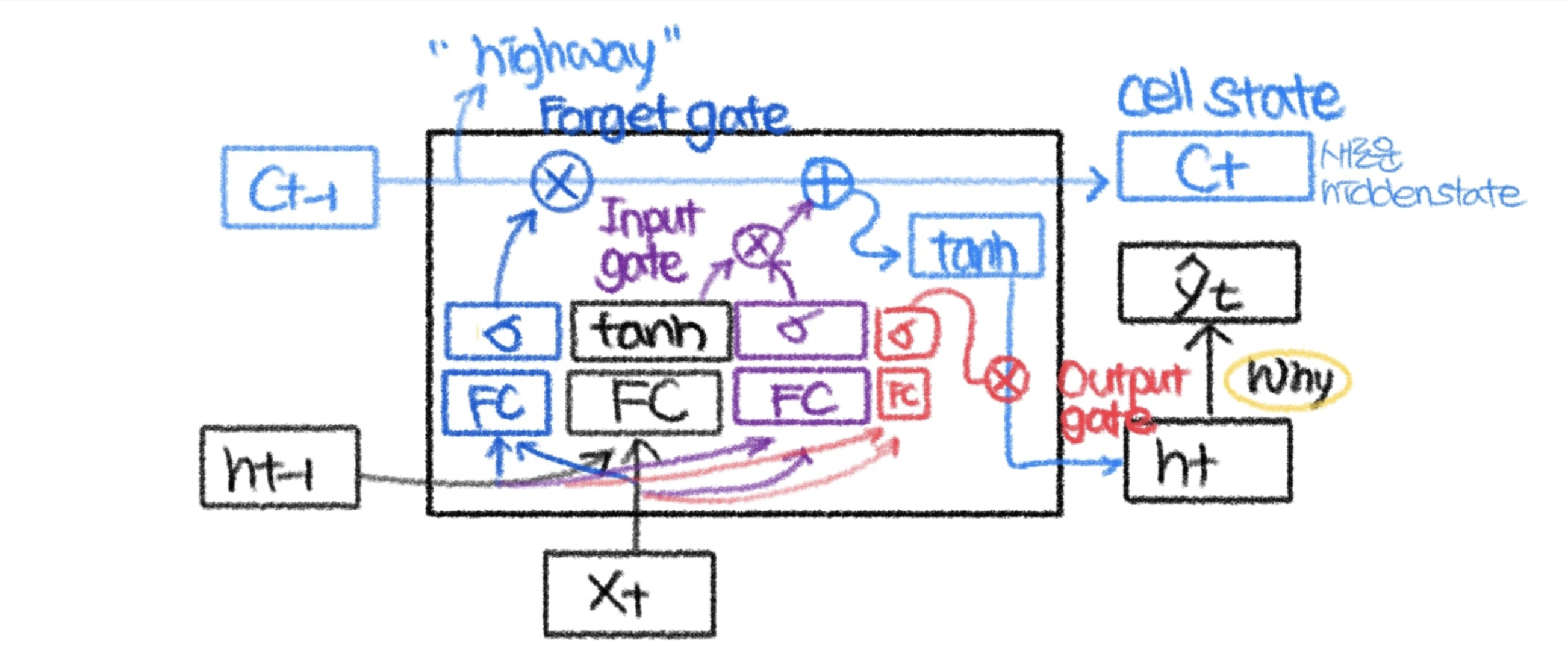 Hidden State
Hidden State
이전 타임 스텝의 정보를 현재 타임 스텝의 입력과 함께 보유하는 내부 메모리
Cell State
FC를 우회하는 highway
Input Gate
현재 입력된 새로운 정보를 얼마나 사용할거야? 를 결정하며 0-1값을 가진다
Forget Gate
이전의 Cell State 정보를 얼마나 잊을거야? 를 결정하며 0-1값을 가진다
Output Gate
다음 층으로 전달할 Hidden State를 만든다
→ 셀 상태를 업데이트할 때나 출력 게이트를 통해 최종 출력을 계산할 때 tanh 함수가 적용
[3] GRU
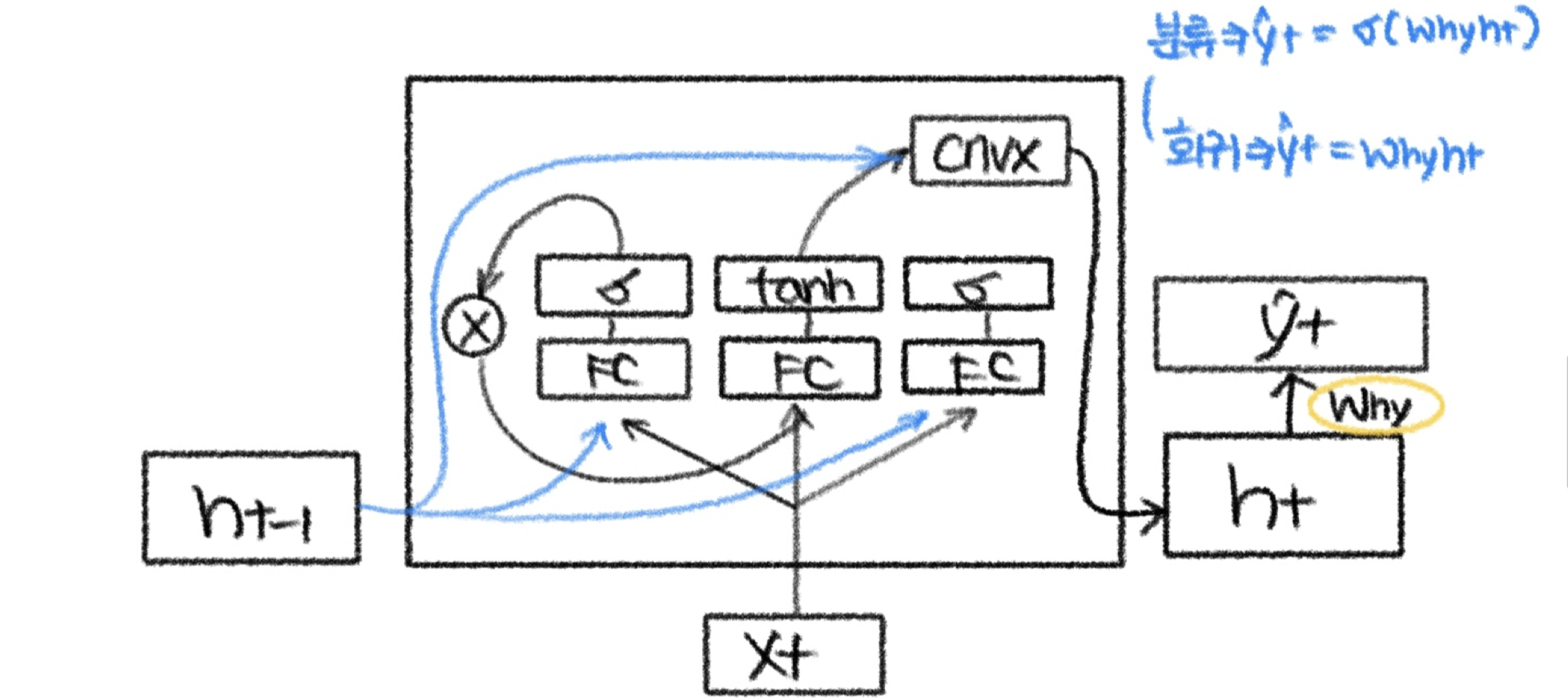 일단, 선은 잊고 component 들만 보자. LSTM과의 차이는 Cell State가 없다는 것이다. 그만큼 parameter가 적고 연산량이 적다.
일단, 선은 잊고 component 들만 보자. LSTM과의 차이는 Cell State가 없다는 것이다. 그만큼 parameter가 적고 연산량이 적다.
[4] Seq2Seq
각 입력토큰마다 출력 토큰을 생성하는 거, 가능한가? 불가능할 때도, 가능은 하지만 효과적이지 않을 때도 있다. So, Many-to-Many가 아닌
"Many-to-One(Encoder)", "One-to-Many(Decoder)"를 사용하는 Seq2Seq 모델이 고안되었다.
상세내용을 다이어그램으로 그려봤당!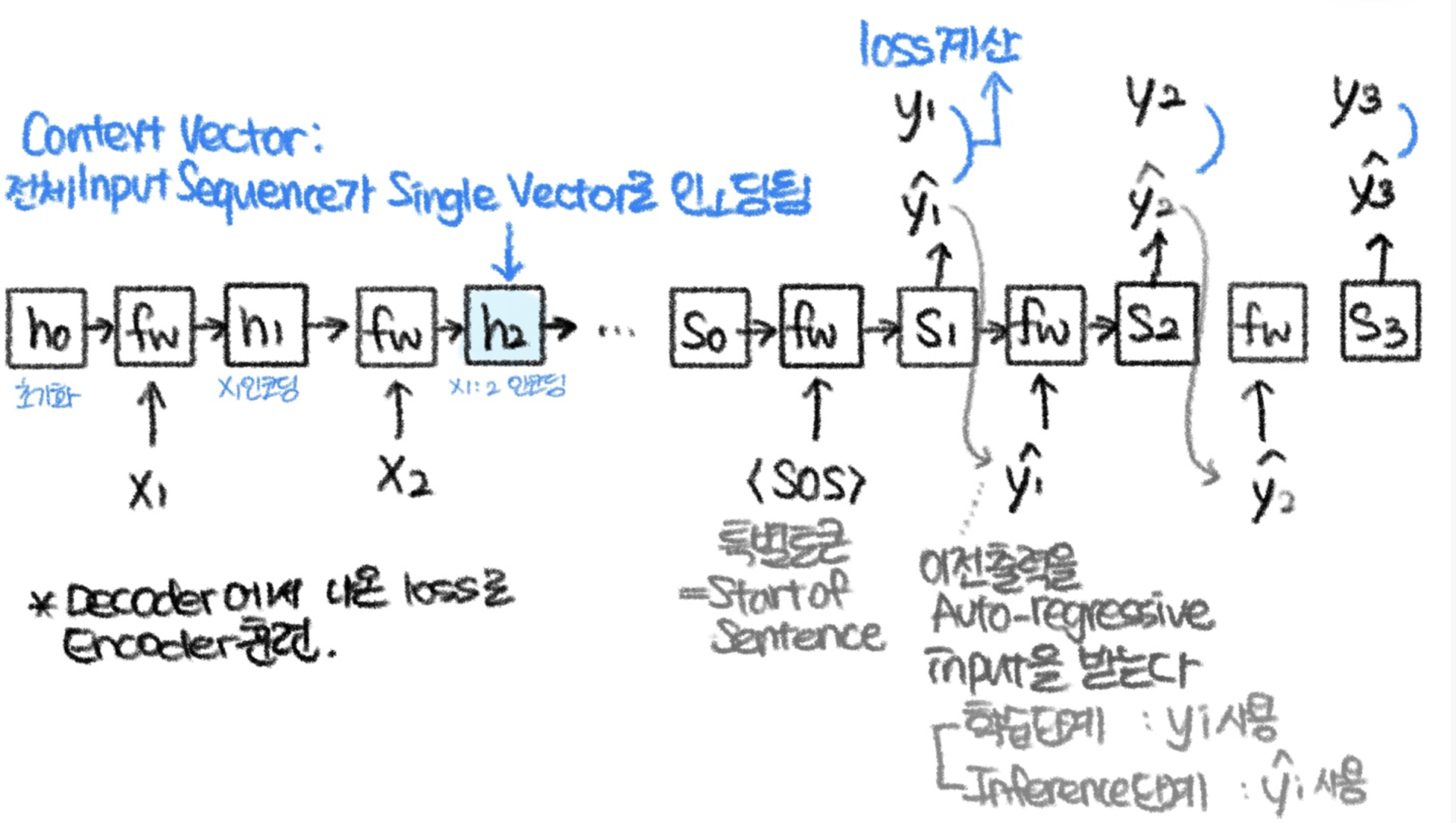
📌오해했던 것: Context Vector와 y_t를 사용해서 y_t+1을 예측?
NO!!
context vector가 업데이트된 decoder의 hidden state s_t와 h_t를 사용해 y_t+1를 예측한다. 즉, context vector는 디코더 첫 부분에만 쓰이고 끝
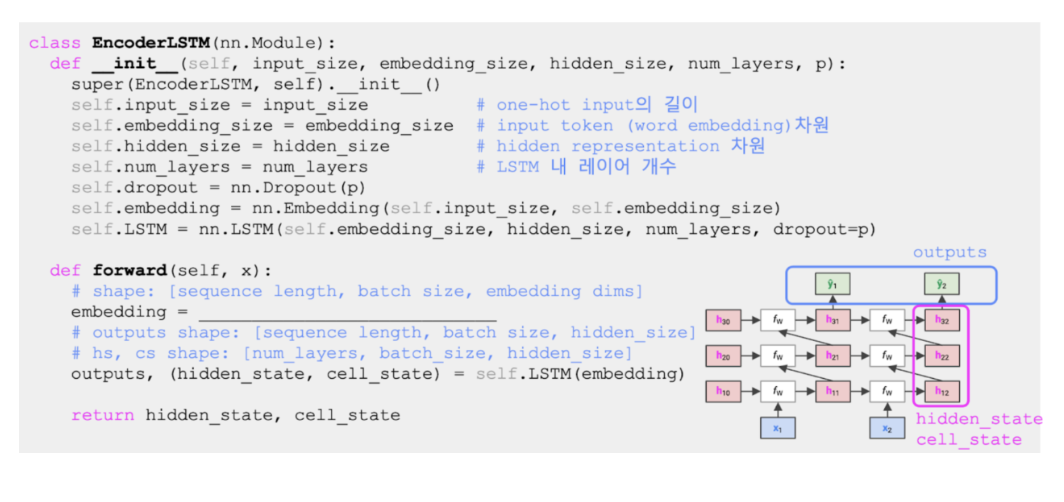
💻 모델코드
Encoder
Decoder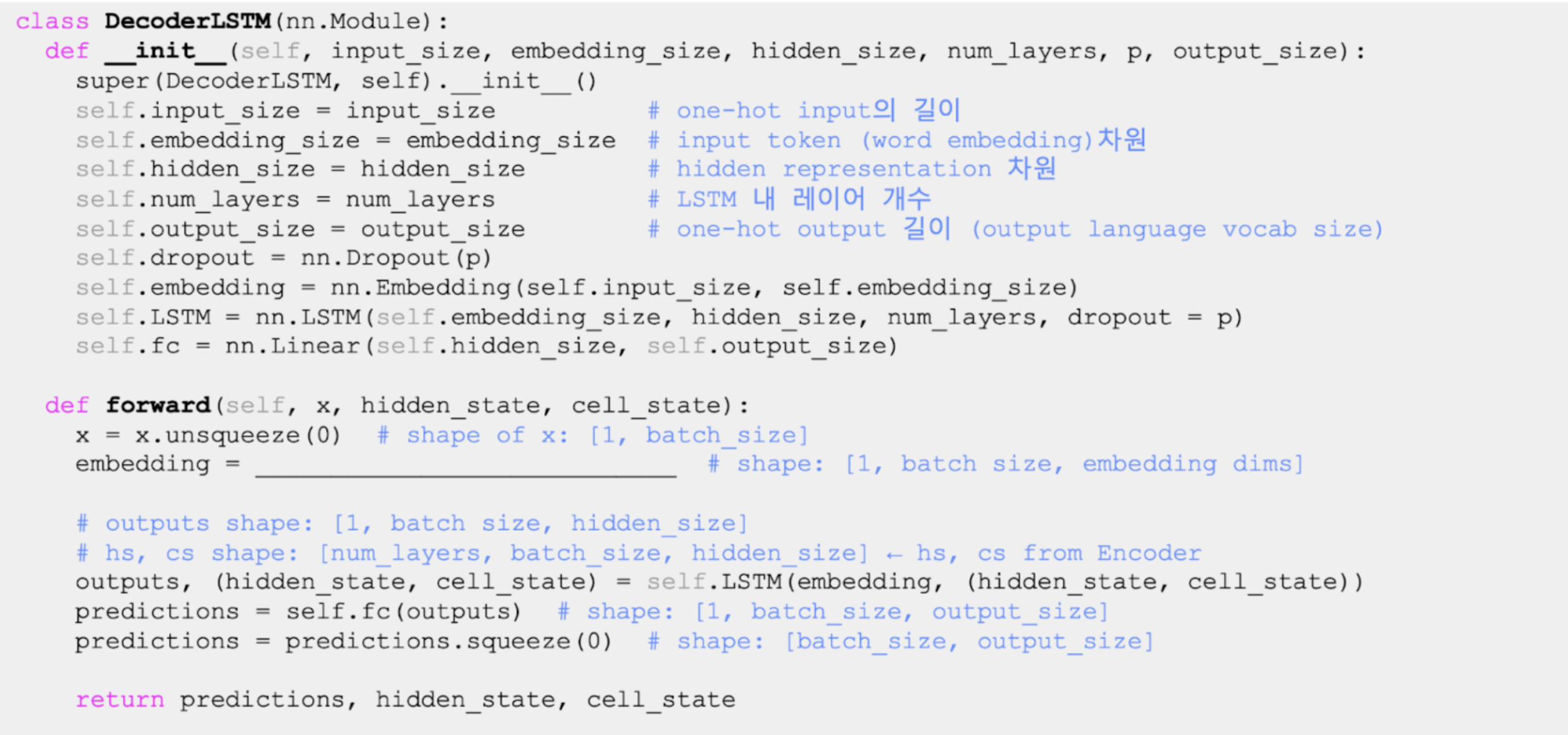
빈칸: self.dropout(self.embedding(x))
- Dropout: 과적합 방지용 정규화 기법이다. 특정 뉴런에 의존하지 않도록 일부 뉴런을 무작위로 비활성화(0으로 설정)한다. 시퀀스를 임베딩 공간으로 전환하는 Encoder와 Decoder 모두에 Dropout을 적용하면 다음가 같은 장점이 있다.
- 일관성: 임베딩 벡터에 동일한 정규화 기법 적용한다.
- 일반화 성능: 임베딩 벡터에 노이즈를 추가
Interface
 (A) source.shape[1], (B) target.shape[0]
(A) source.shape[1], (B) target.shape[0]
(B): 변수의 이름에서 언급된 target의 길이 = 출력 문장의 길이
(A): num_sentences = 한 배치(batch) 안에 있는 문장의 개수 = 배치 크기(batch size)를 나타냄
