Image classification위주의 내용이다.
데이터 전처리(Data Preprocessing)
Zero-centering & Normalization
- 모든 입력값이 양수인 데이터에서 sigoid activation function을 사용하는 경우: upstream gradient의 부호가 바뀌지 않고 downstream gradient에 그대로 반영된다는 문제가 있음
Why Zero-centering
(1)Weight의 작은 변화에 덜 민감해진다
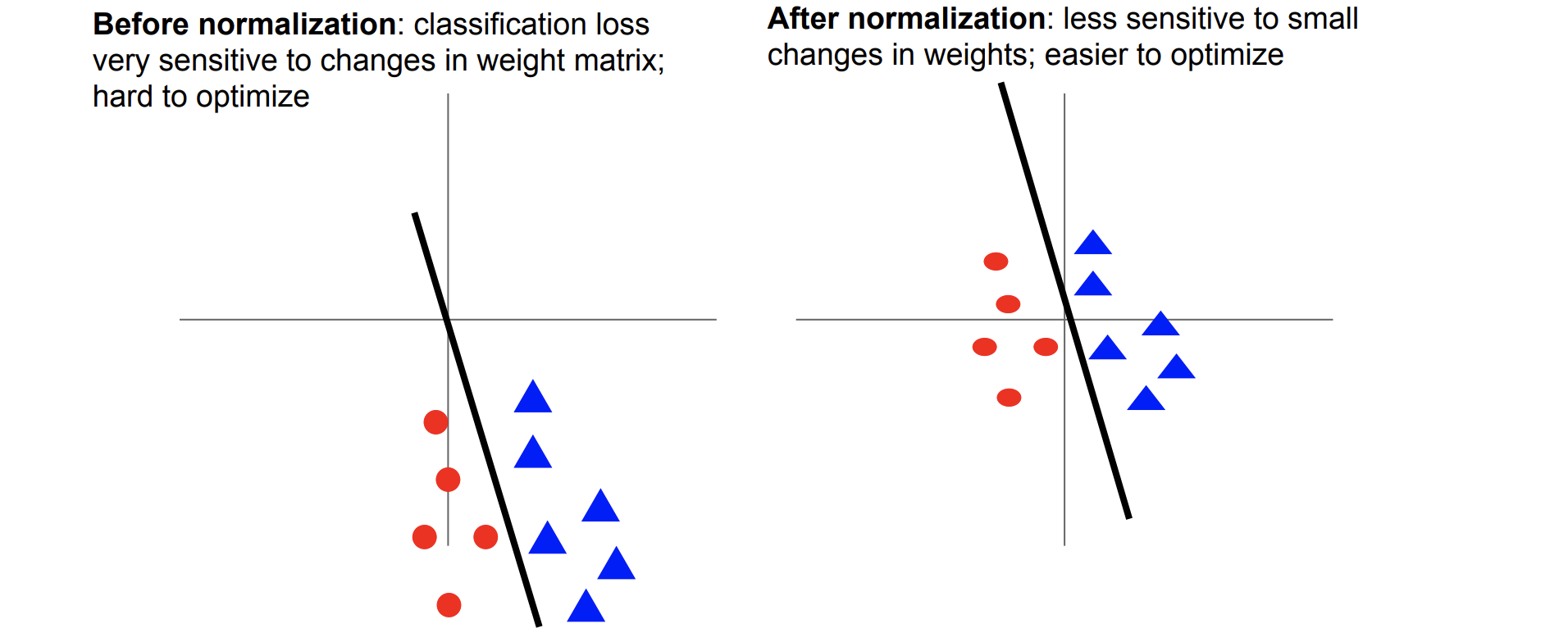 *출처: https://cs231n.stanford.edu/slides/2017/cs231n_2017_lecture7.pdf
*출처: https://cs231n.stanford.edu/slides/2017/cs231n_2017_lecture7.pdf
(2)효율적인 Optimization을 위해 필요하다
-
1.1에 제시한 상황의 경우 gradient descent가 굉장히 비효율적으로 업데이트 된다
- optimal path를 따라가지 않고 아래처럼 됨
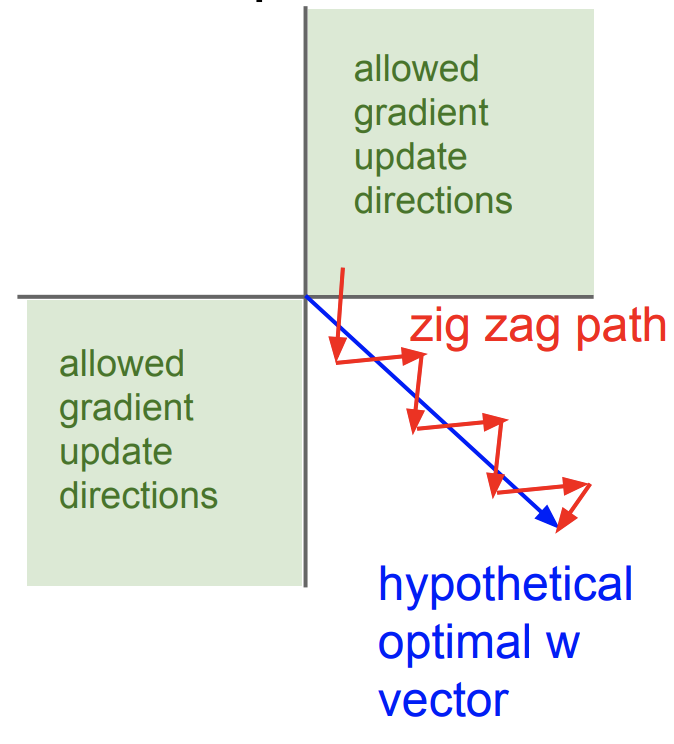 *출처:https://cs231n.stanford.edu/slides/2017/cs231n_2017_lecture6.pdf
*출처:https://cs231n.stanford.edu/slides/2017/cs231n_2017_lecture6.pdf
- optimal path를 따라가지 않고 아래처럼 됨
-
data distribution의 center는 0이 되도록 하는 것을 권장함(zero centering)
-
어떻게 해결해야하는가?
: 모든 데이터포인트에서 데이터의 평균값을 빼주면 된다.
NN, Normalize는 필수
또한 NN이라는 모델 자체가 데이터의 정규성을 기본 전제로 하기에 normalize도 해주어야한다. computer vision 데이터도 예외가 아님
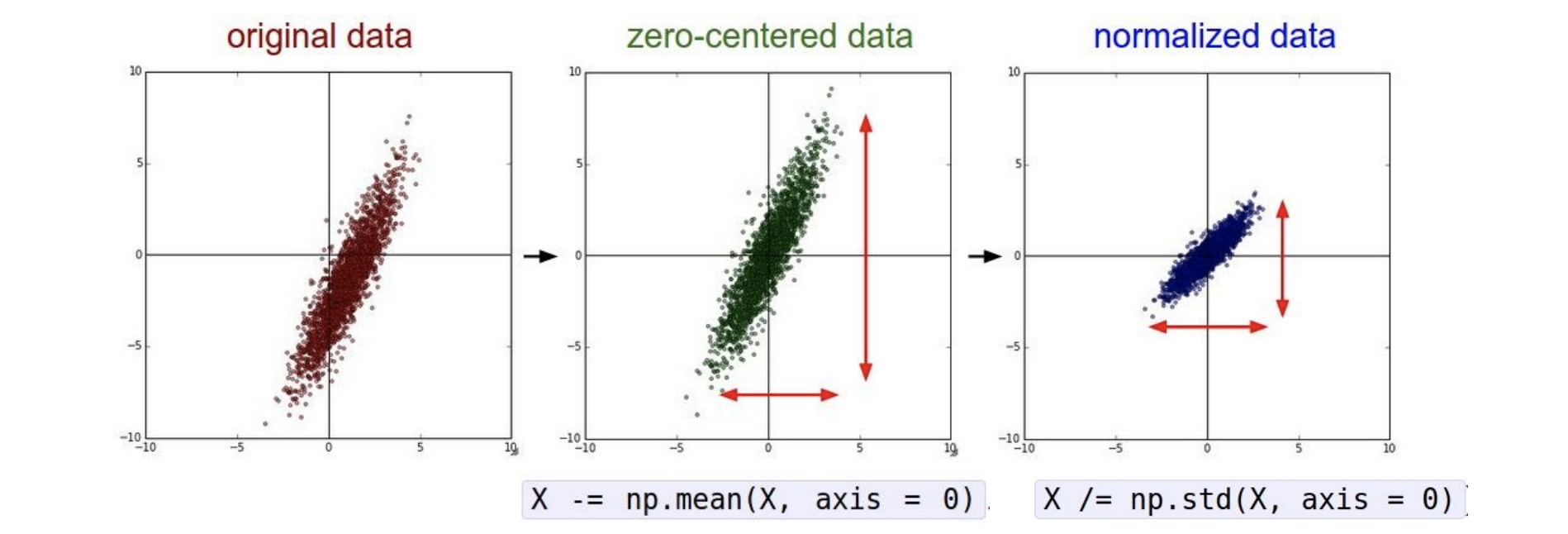 *출처: https://cs231n.stanford.edu/slides/2017/cs231n_2017_lecture6.pdf
*출처: https://cs231n.stanford.edu/slides/2017/cs231n_2017_lecture6.pdf
PCA & Whitening
- data compression 메서드 중 하나
- PCA: 데이터 분포에서 가장 분산이 넓은 축을 중심으로 rotate
- Whitening 그걸 variance로 나누어줌
데이터 증강(Data Augmentation)
- 실제 데이터셋은 적다. 레이블링 해야하기 때문이다.
- 데이터의 의미에 영향을 주지 않고 각각의 데이터를 수정할 필요가 있다.
- 그렇게 늘린 데이터로 training 을 진행한다.
- 약간 노가다스럽지만 Robust한 모델을 만드는 데에 굉장히 효과적이며 현업에서 매우 자주 쓰이는 방법들이다.
- 어려운 내용은 없어서 설명은 생략하였다.
Horizontal Flips
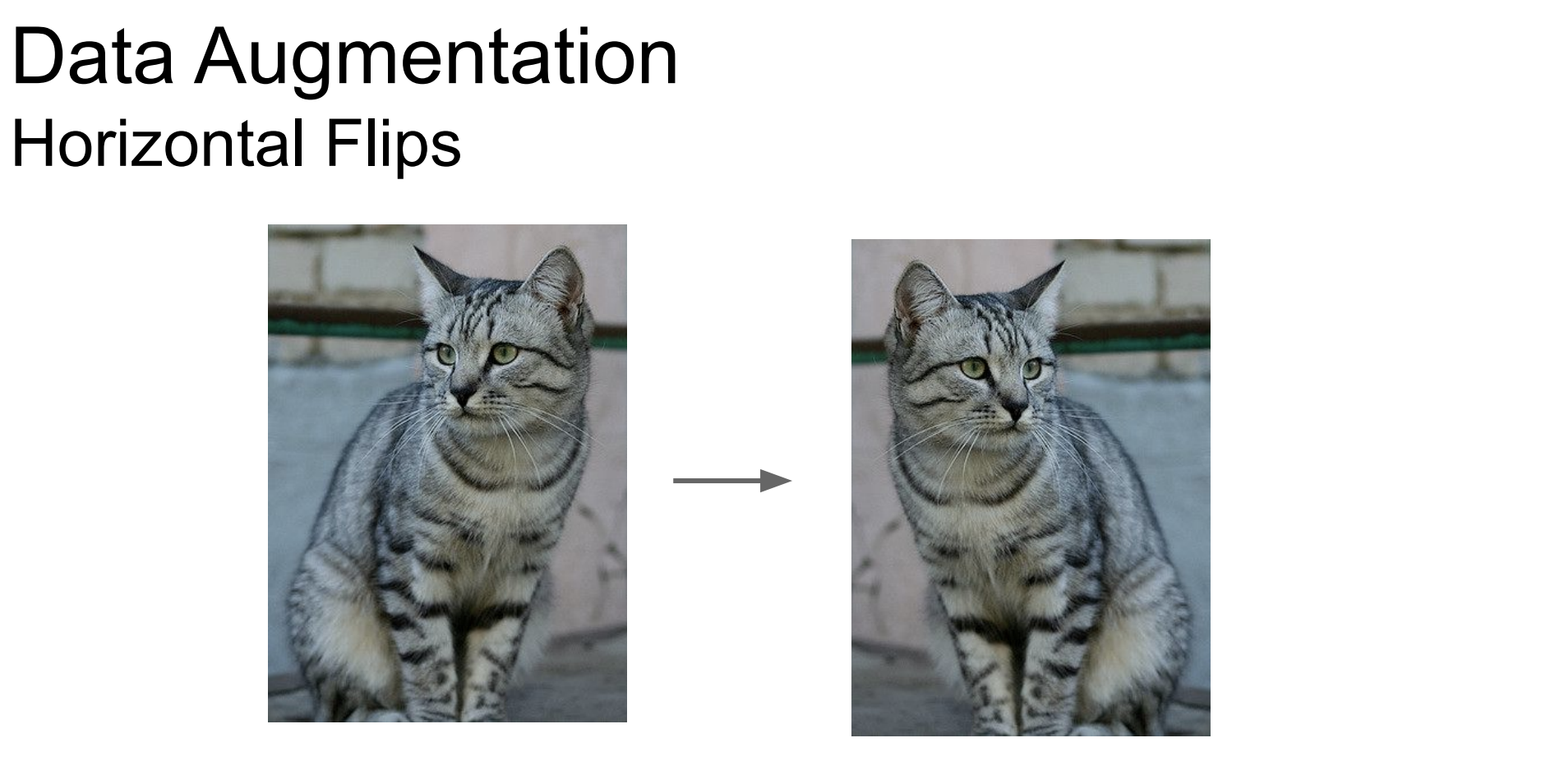
*출처:https://cs231n.stanford.edu/slides/2020/lecture_8.pdf
Random Crops

*출처:https://cs231n.stanford.edu/slides/2020/lecture_8.pdf
Translation in Variance
Color Jitter

- 그 외 Scaling, Random Crops, Scaling도 있다. 원리는 간단하지만 생각보다 효과가 좋으니, CV 쪽 건드릴 때 써먹어보면 좋을듯!!
