먼저, 설명 가능한 추천이란 무엇일까?
- 추천 시스템이 특정 항목을 추천할 때, 추천 이유를 함께 제공하는 방식
- 예를 들자면 "이 작품은 당신이 자주 본 장르와 관련이 있어 추천합니다." 이런 식이다
추천 이유를 왜 제공해야할까?
이건 추천 서비스를 제공하는 사람(개발자)과 이용하는 사람(유저), 2개의 관점으로 나눠 살펴볼 수 있는데:
- 서비스 공급자 관점:
- "디버깅"을 위해 필요하다
- 즉, 추천 시스템이 왜 특정 결과를 제공했는지 이해해야 문제를 개선할 수 있는 것
- 사용자 관점:
- 추천 결과에 만족하지 않으면 서비스 사용을 그냥 중단해버릴 가능성이 높은데,
- 같은 추천을 제공해도 추천 이유를 함께 제공하면 신뢰와 만족도를 높일 수 있아 잔여할 확률이 높아진다고 한다
그렇다면 추천 이유는 어떻게 만들 수 있는가?(Post-Hoc)
추천 이유를 만드는 방법은 크게 2가지
알고리즘 자체가 설명 가능한 모델 사용⇒ 고차원 모델을 사용하는 이상 불가능이다- Post-Hoc: 추천 결과에 추천 이유 생성 (블랙 박스 모델에도 적용 가능) ⇒ ✔️
Post-Hoc, 어떻게 구현할까?
- 카카오에서는 추천 이유를 두 가지 범주로 나누었다. '관련성'과 '인기도'
- 그리고 관련성과 인기도 각각에서도 다음과 같이 세부 라벨을 나누었다
- 관련성(Relevant):
- Seen: 이전에 본 작품과 유사
- Co-occurrence: 다른 사용자가 함께 본 작품
- Preference: 선호도 기반
- Interest-meta: 자주 보는 카테고리 기반
- 인기도(Popularity):
- High-conversion: 전환율이 높은 작품
- Popular: 전체적으로 인기 있는 작품
- 관련성(Relevant):
그래서 이 라벨들을 어떻게 구분한다는 걸까?
다음 이미지를 참고하자(출처: 카카오 웹툰) 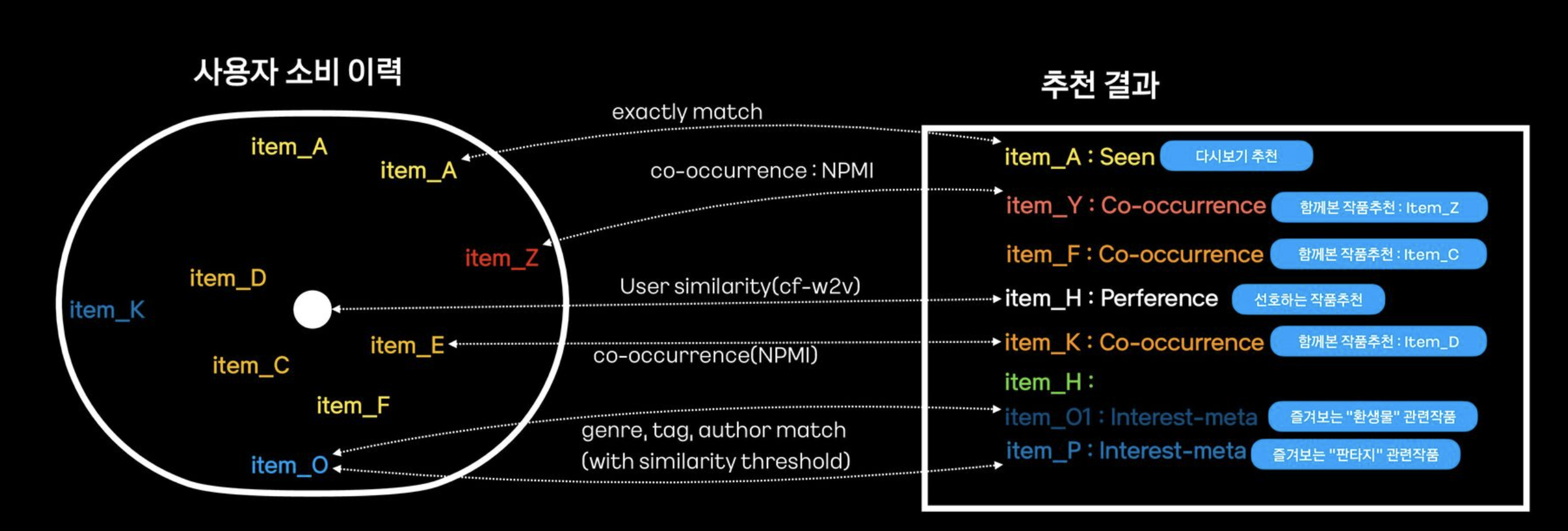
여기서 헷갈렸던 게 있는데,
1. 추천 모델을 여러개 만들고 어떤 모델을 통해 얘를 추천하게 되었는지 말해주는 건가?
2. 아니면 모델은 1개만 쓰고 생성된 추천 결과를 이전 상호작용 이력과 비교(메트릭 계산 등)한다는 건가?
⇒ 다른 내용을 더 읽고 이 포스팅에서 말하는 건 2번 방법임을 알게되었다.
즉, 추천 이유 생성은 추천 모델과 별개로 작동하는 것!
준비물로 2가지 데이터가 필요하다
1. 사용자의 상호작용 이력 데이터
2. 상품에 대한 메타 데이터
구체적으로는 다음의 방식으로 작동한다
위의 데이터셋을 사용해 우리가 잘 알고있는 추천시스템 모델을 하나 개발한다.
CF일수도 있고, DeepFM일 수도 있고, .. 이 부분은 개발자 나름대로 구현하겠지?
그런 다음 그 모델이 생성한 추천 결과를 사용자 소비 이력과 비교하여 왜 특정 항목이 추천되었는지를 분석하는 것.
이 때 다양한 메트릭을 사용한다. 이 부분에 대해서는 라벨별로 다음과 같이 정의할 수 있다
(참고로 High-conversion, Popular한 아이템은 사용자 이력 데이터가 아닌 아이템의 정보만을 사용하기에 따로 메트릭이랄게 없다)
| 추천 이유 | 기준 | 적용 방법 및 메트릭 | 예시 |
|---|---|---|---|
| Seen | 사용자가 이전에 소비한 항목 | - 소비 이력과 정확히 매칭(exactly match) | item_A를 본 적이 있으면 "다시보기" 추천 |
| Co-occurrence | 다른 사용자들과 함께 소비된 항목 | - NPMI (Normalized Pointwise Mutual Information): 두 항목의 동시 소비 확률 측정 - CF-W2V (Collaborative Filtering - Word2Vec): 유사 소비 패턴 사용자 기반 추천 | item_A와 함께 소비된 item_Y 추천 |
| Preference | 사용자가 선호할 가능성이 높은 항목 | - 사용자의 선호 장르, 태그, 작가 기반 추천 - 유사도 계산(Cosine Similarity, Word2Vec) | "로맨스" 장르를 자주 보면 새로운 로맨스 작품 추천 |
| Interest-meta | 사용자가 자주 소비하는 메타 정보(장르, 태그, 작가 등)와 관련된 항목 | - 콘텐츠 메타 데이터와 사용자의 소비 패턴 비교 - 유사도 임계값 이상 항목 추천 | "환생물" 태그를 선호하면 관련 항목 추천 |
| High-conversion | 다른 사용자들에게 전환율(CTR)이 높은 항목 | - 전환율 ( \text{CTR} = \frac{\text{Clicks}}{\text{Impressions}} ) 활용 - 특정 항목의 전환율이 평균보다 높으면 추천 | 클릭률이 높은 작품을 추천 |
| Popular | 전체적으로 많이 소비된 항목 | - 상위 ( N )개의 인기 항목 정렬 후 추천 | 인기 순위 1~10위 항목 추천 |
암튼 그러면 결과로 다음과 같은 reason, keyword 정보를 생성할 수 있고, 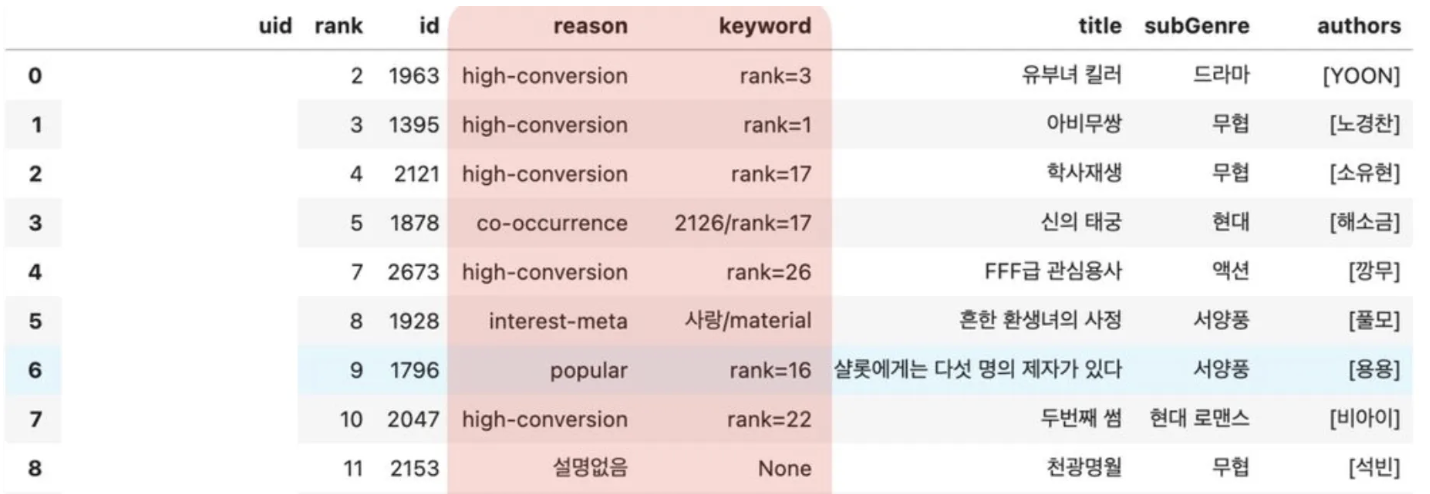
추천과 함께 이유를 다음과 같이 띄울 수 있다
AB 테스트 결과
- 추천 이유를 표시한 실험군이:
- 작품 열람수: +20% 증가
- 열람 전환율: +19% 증가
결과 분석 EDA
이 주제를 수행할 경 대시보드를 만들어 우리가 만든 추천 시스템을 트래킹하고, 해석하기 좋아보인다
Tableau같은 BI 툴을 사용하는 것도 고려하기
예를 들면 이런 거:
-
추천 이유와 사용자 활동성
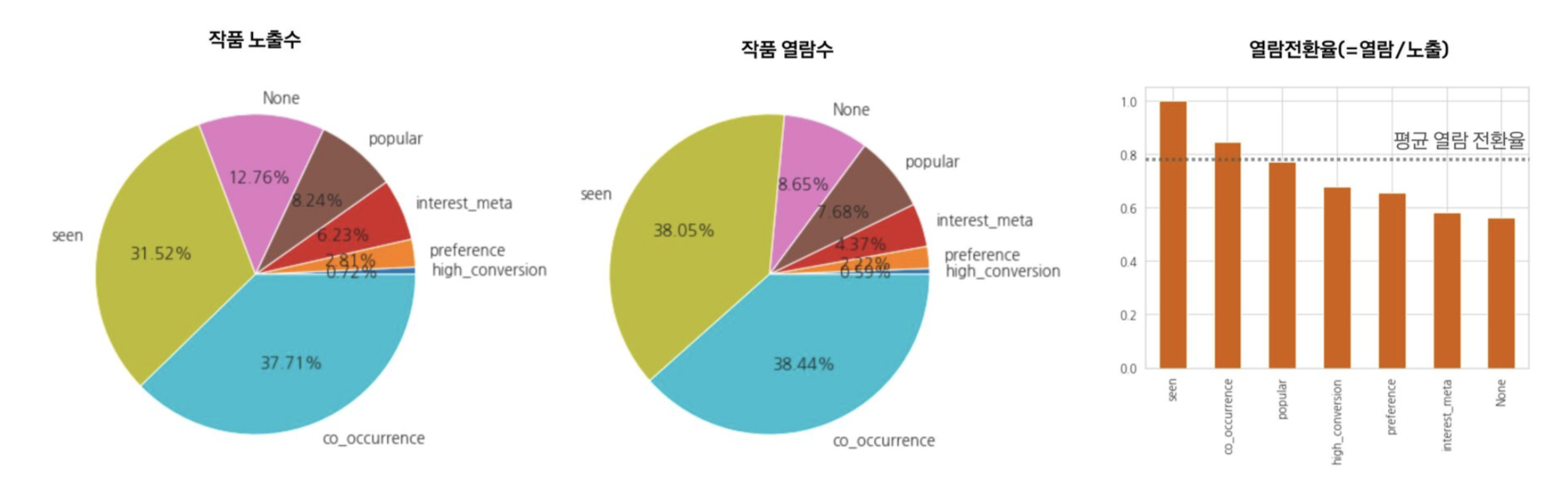
- 활동성이 높은 사용자: 개인화된 추천(seen, co-occurrence)에 더 반응
- 콜드 사용자: 인기 작품(popular)이나 다시보기(seen) 추천에 반응
- 추천 작품의 관련성(Relevant)은 열람 전환율에 중요한 영향을 미침
-
아니면 이런 거:
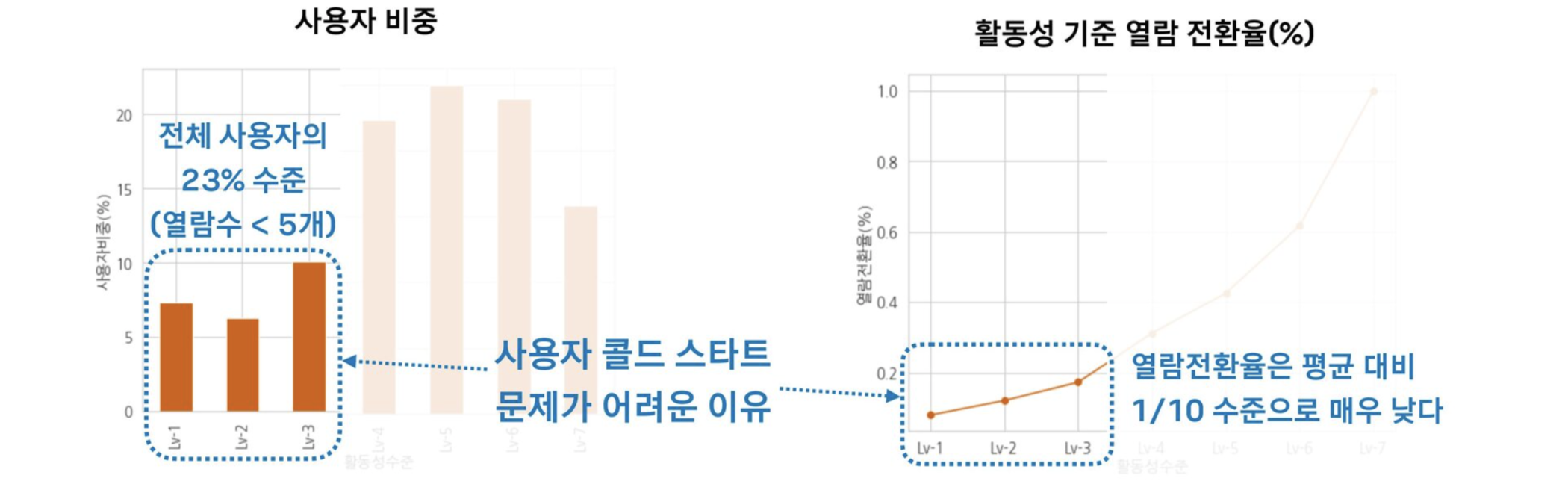
- 사용자의 작품 열람수를 기준으로 Lv1(낮음) ~ Lv7(높음) 7단계로 사용자 활동성을 구분
-사용자 활동성이 높아질수록 추천구좌의 열람 전환율이 지수적으로 높아진다. -
아니면 이런 것도:
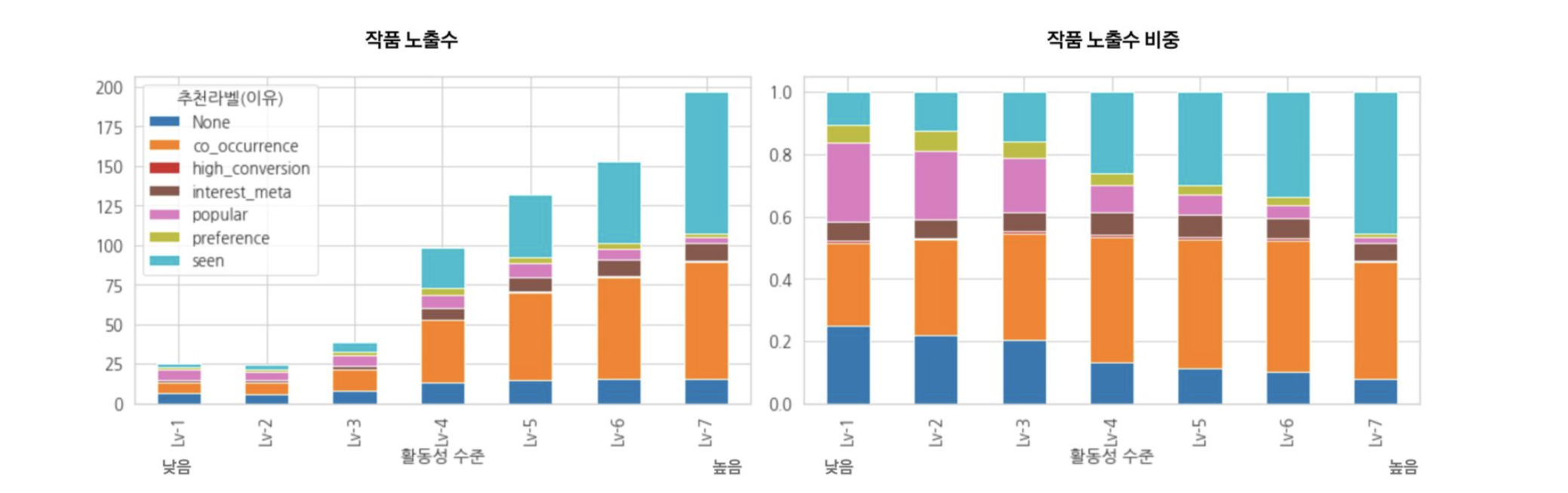
- 콜드 사용자일수록 비 개인화 추천 작품(■popular)이 많이 추천되고, ■None(추천이유모름)의 비율이 높다.
-활성 사용자일수록 개인화 추천 작품(■seen, ■co-occurrence)의 노출 비중이 높아진다.
더 적용해볼만한 것
사용자 유형에 따른 추천 라벨 분석
- 콜드 스타트 유저와 이력이 충분한 유저는 각기 다른 라벨 선호 패턴을 보일 가능성이 크다
- 예를 들어, 콜드 스타트 유저는 개인화된 추천보다는 열람수가 많은 인기 작품을 더 선호할 수 있다 - 이걸 개인화 하기 위해서는 다음을 고려할 수 있겠다:
- 사용자 유형에 따른 선호 추천 라벨 분석: 단순하지만 구현이 쉬움
- MAB를 활용한 실시간 최적화: 고도화된 알고리즘이지만 구현이 어려움
MAB를 활용한 실시간 최적화
- 카카오는 토픽 모델링과 MAB를 융합해 토픽별로 상품을 나누고 배치를 최적화하는 방식을 사용했다
- https://tech.kakao.com/posts/486 - 이를 변형하면 사용자 유형별 추천 라벨 배치를 최적화할 수 있다
- 스포티파이 역시 유사한 방식으로 추천 시스템을 운영 중이다
MAB 구현 시 고려 사항
다만, MAB를 구현하려면 몇 가지 조건이 필요하다
1. 첫째, 실제 유저가 웹사이트에서 상호작용하며 데이터를 누적시키는 환경이 필요하다.
2. 둘째, 실시간 처리를 할 수 있어야 한다 → 이 부분은 추가 리서치를 해봐야한다
카카오웹툰의 설명 가능한 추천 시스템(Explainable Recommender System) 개발과정을 참고하여 작성함.
