
요즘 데이터 사이언티스트에 대한 수요가 높다는 이야기를 종종 듣는다. 실제 보건 통계를 전공하면서 데이터와 통계에 대해 익숙해졌다.
오늘부터는 데이터 사이언스에 관한 내용을 정리하면서 이론적으로 필요한 내용들을 정리하고자 한다.
들어가는 질문 - 데이터란?
21세기 지금 이 글을 적고있는 2026년 2월 대한민국에 사람들은 '데이터'라는 언어에 이미 많이 익숙하다. 실제 우리가 휴대폰 요금제를 구할 때도 '데이터'라는 용어를 사용한다.
데이터는 라틴어인 Dare(주다)의 과거 분사형으로 '주어진 것'이라는 의미로 사용되었었는데, 현재는 추론과 추정의 근거를 이루는 사실 이라는 표현으로 많이 사용한다. 이는 데이터라는 것은 단순한 객체로서의 가치뿐 아니라 상호관계 속에서 가치를 가지기 때문이다.
데이터 & 정보
데이터의 유형
'데이터'의 특성을 나타내는 것 중에 가장 먼저 쓰는 용어는 '정성적', '정량적' 특성이라는 표현이다.
정성적은 물질의 성분이나 성질, 쉽게 말해 수치화 되어 있지 않은 특성을 말한다.

정량적은 양을 나타내거나 수치, 도형, 기호 등으로 나타내는 특성을 말한다.

이것을 확장해서 데이터를 비교하게 되면 아래와 같다.
-
정성적 데이터(Qualitative Data) : 저장이나 검색 등에 많은 비용이 소모되는 언어, 문자 등의 형태의 데이터
ex) 질환 사진, 블로그 글 등 -
정량적 데이터(Quantitative Data) : 정형화된 데이터들이며 실제 수치, 도형 기호 등으로 형태가 있으며 저장 검색 등 이 쉬움
ex) 나이, 키, 몸무게 등
데이터의 역할 : 지식경영의 핵심 이슈
아주 갑자기 데이터를 설명하다가 '지식경영'이라는 말이 나왔다. 나도 모르게 당황스러운 흐름이다.. 유명한 데이터 관련 시험에서 이런 흐름으로 내용이 이루어져있는데,
왜일까?
사실 데이터 그 자체는 어떠한 의미를 가지지 않는다. 우리는 그 데이터를 통해서 올바른 의사결정을 내리고 미래를 예측하고자 하는 것이 목적이다.
암묵지(Tacit Knowledge) & 형식지(Explicit)
- 암묵지 : 학습과 경험을 통해 개인에게 체화되어 있지만 겉으로 드러나지 않는 지식 -> 사회적으로 중요하지만 공유되기 어려움
ex) 글씨 이쁘게 쓰는 법, 과자봉지 빨리뜯는 법 등 - 형식지 : 문서나 메뉴얼 같이 형상화되어있는 지식
-> 전달과 공유가 용이함
ex) 책, 유튜브영상 등
cf)
암묵지 & 형식지의 4단계 지식 전환 모드
: SECI 모델(Socialization-Externalization-Combination-Internalization Model)
-
1단계 : 공통화
암묵지의 지식 노하우를 다른 사람에게 알려주는 것 -
2단계 : 표출화
암묵적 지식 노하우를 책, 교본 등 형식지로 만드는 것 -
3단계 : 연결화
책이나 교본(형식지)에 자신이 알고 있는 새로운 지식(형식지)를 추가하는 것 -
4단계 : 내면화
만들어진 책이나 교본(형식지)를 보고 다른 직원들이 노하우(암묵적 지식)를 습득하는 것
데이터와 정보의 관계(DIKW 피라미드)
여러 시험에서 잘 다뤄지는 내용으로 실제 데이터에서부터 지혜를 얻는 과정을 계층구조로 표현한 것이다.
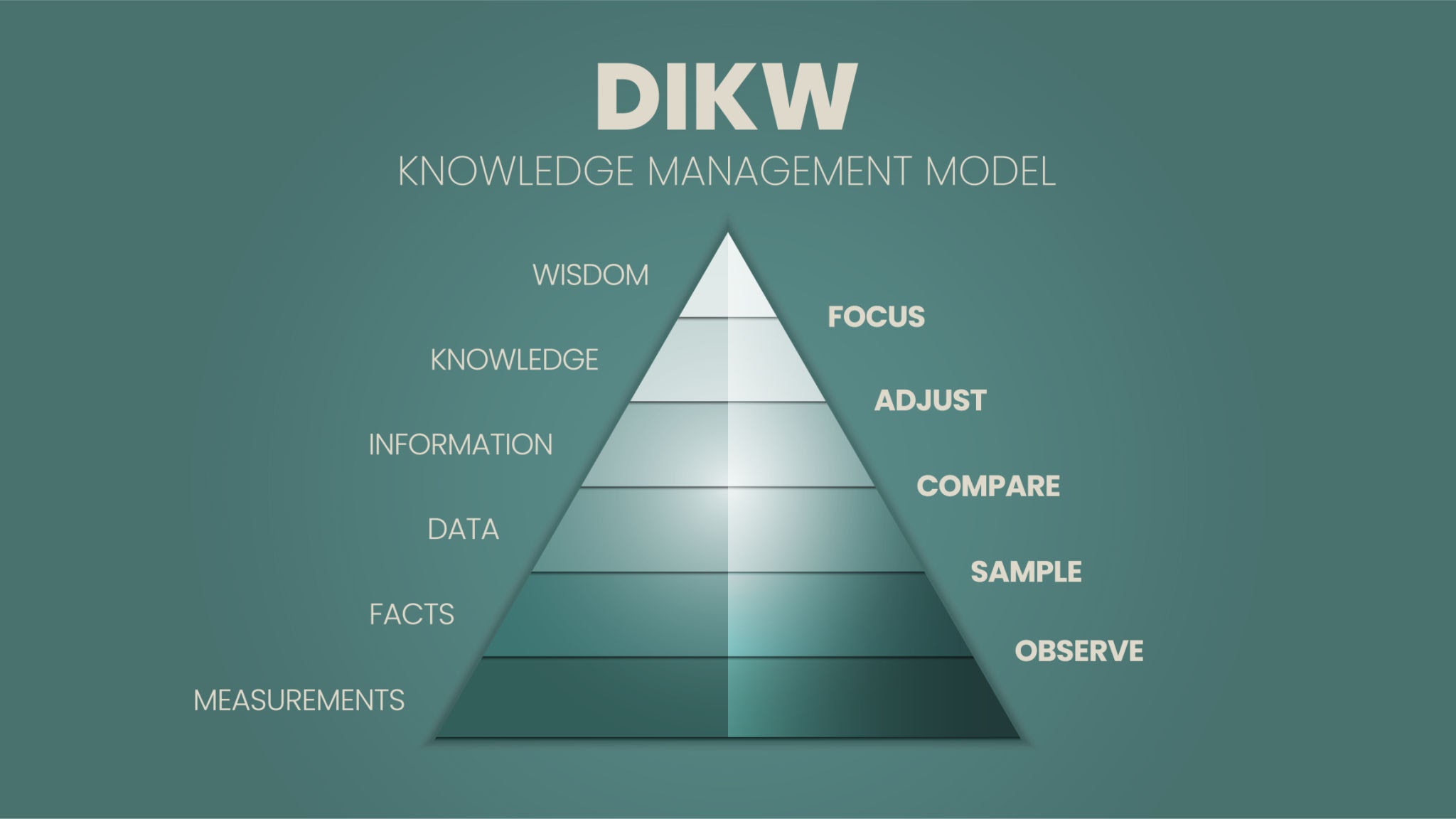
순서대로 생각해보면 아래와 같다.
-
데이터(Data) : 존재형식이나 다 데이터와의 상관관계등이 없는 가공하기 전의 수치나 기호
-
정보(Information) : 데이터의 가공, 처리와 데이터간 연관관계 속에서 의미가 도출된 것
-
지식(Knowledge) : 데이터의 연결된 패턴을 이해하여 이를 토대로 예측한 결과물
-
지혜(Wisdom) : 근본 원리에 대한 깊은 이해를 바탕으로 도출되는 아이디어(추론)
실제 우리가 햄버거 집을 가보자고 하자. 내가 지금있는 역삼역 근처에는 햄버거집이 KFC와 노브랜드 버거가 있다.(아래의 예시는 가정이다.)
KFC 치킨버거 : 6000원
노브랜드 치킨버거 : 6500원 이라고 했을때
데이터 : KFC 6000원, 노브랜드 6500원
정보 : KFC가 500원 더 싸다
지식 : 가난한 나는 더 싼 KFC에서 햄버거를 먹어야 겠당!
지혜 : 다른 것도 KFC가 더 싸겠군!
이 과정이라고 생각하면 된다.
오늘 내용 중에서 중요한 것은
다름이 아니라
'데이터'는 결국 '추론'을 하기위해 수집된는 것이다!
