20221102_tue
어제 웹크롤링 수업 정리
어제 웹크롤링 수업 정리
- 파이썬(colab 구글검색하여 로그인 후 사용/주피터도 사용 가능)
- 외부강사님이 주신 파일 주피터에 별도 '웹크롤링 수업'폴더명으로 주피터에 업로드함.(외부강사님하고는 colab사용함.)
자바문법 --> 이해하고 실습하고 응용하는 방식으로 연습하는 식으로 공부를 해왔는데,
웹개발 --> 정해진 순서대로 필요한 메소드를 호출한다..
파이썬
파이썬 기초 : 기본적으로 자바보다는 확실히 편하지만 자바스크립트를 배우는 정도라고 보면된다.이걸로 뭔가를 해낼 수 는 없다. 이메일을 보낸다던가 데이터를 보내던가 안된다.
파이썬에서는 기본내용으로 할 수 있는 게 많이 없으니까!
그러면?
파이썬 기초 + 라이브러리 추가 시, 인공지능작업,데이터작업,웹크롤링작업등 가능한 작업들이 많아지기 때문에 많은 사람들이 사용하는 것이다.
웹크롤링
네이버 날씨 사이트를 예시로 사용해보자.
우리는 이 사이트의 개발자모드를 통해 어떤태그를 잘 선택만 하면 원하는 데이터를 가져오기는 할만하다!!!
- 웹크롤링 기초
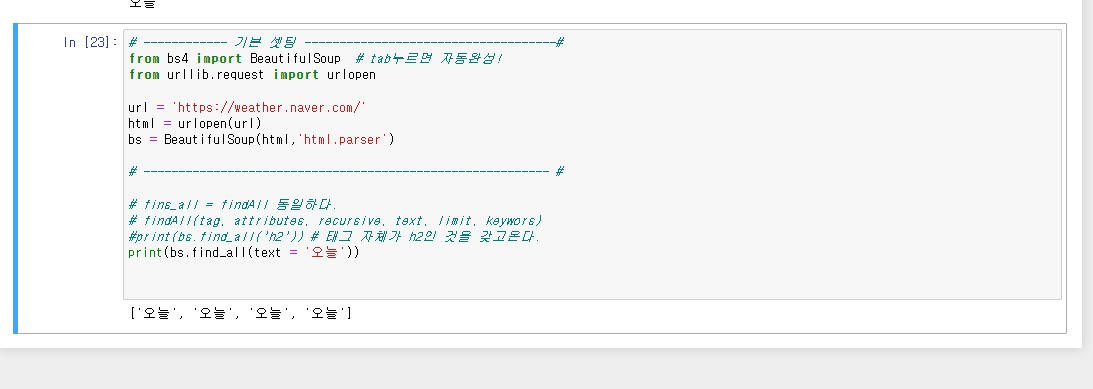
# 크롤링하기위한 가장 기본적 라이브러리왕 임포트
from bs4 import BeautifulSoup # tab누르면 자동완성!
from urllib.request import urlopen
# 크롤링 할 웹페이지 주소 :어떤 변수를 가져올거냐
url = 'https://weather.naver.com/'
# 내가지금 선택한 사이트의 데이터를 끌고오겠다.
# 웹 사이트의 html 정보를 파이선으로 읽어드림.
html = urlopen(url)
# html.read() -> 읽어드린 html정보를 문자열 정보로 제공해준다.
print(html.read())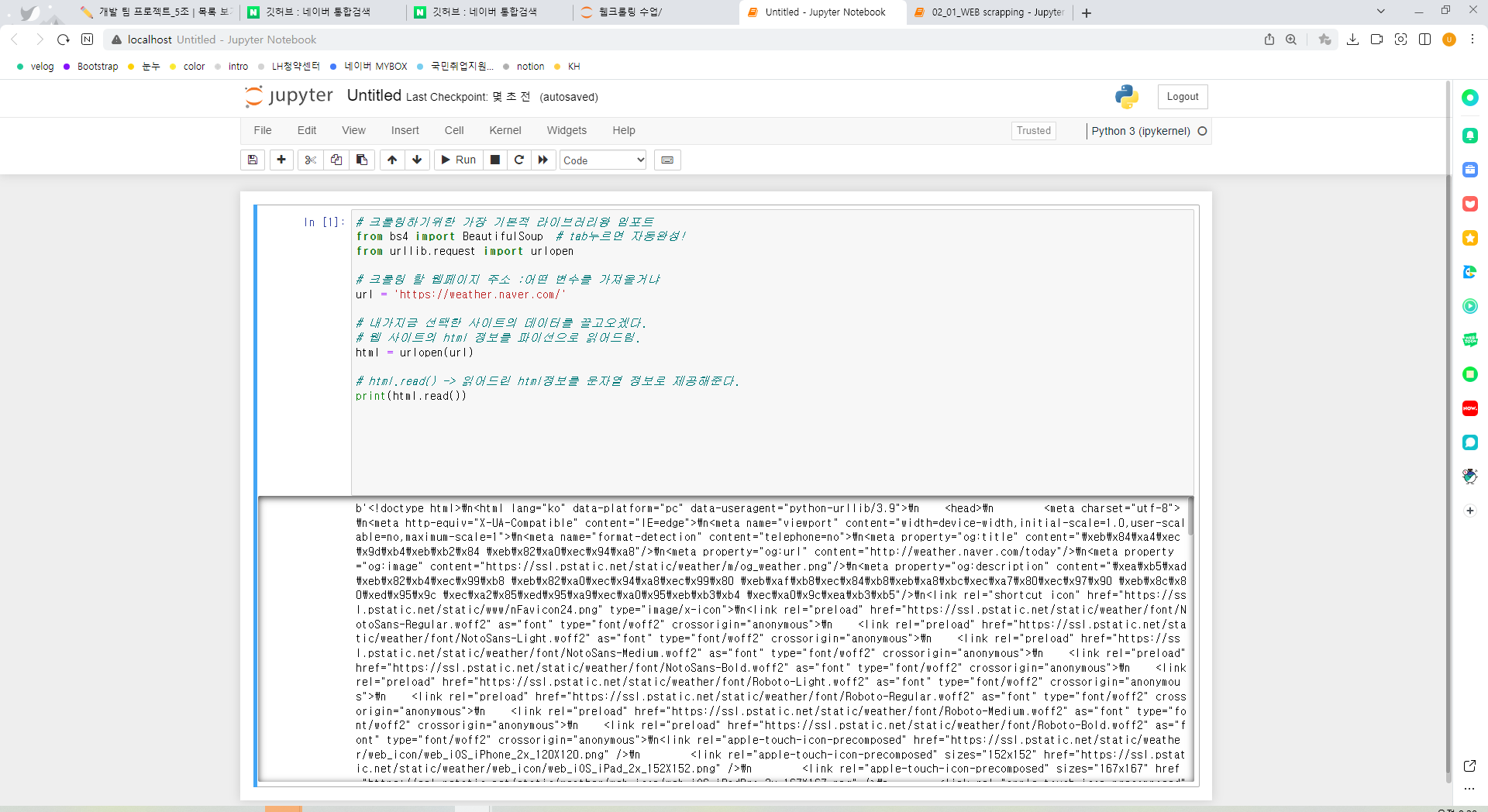
-
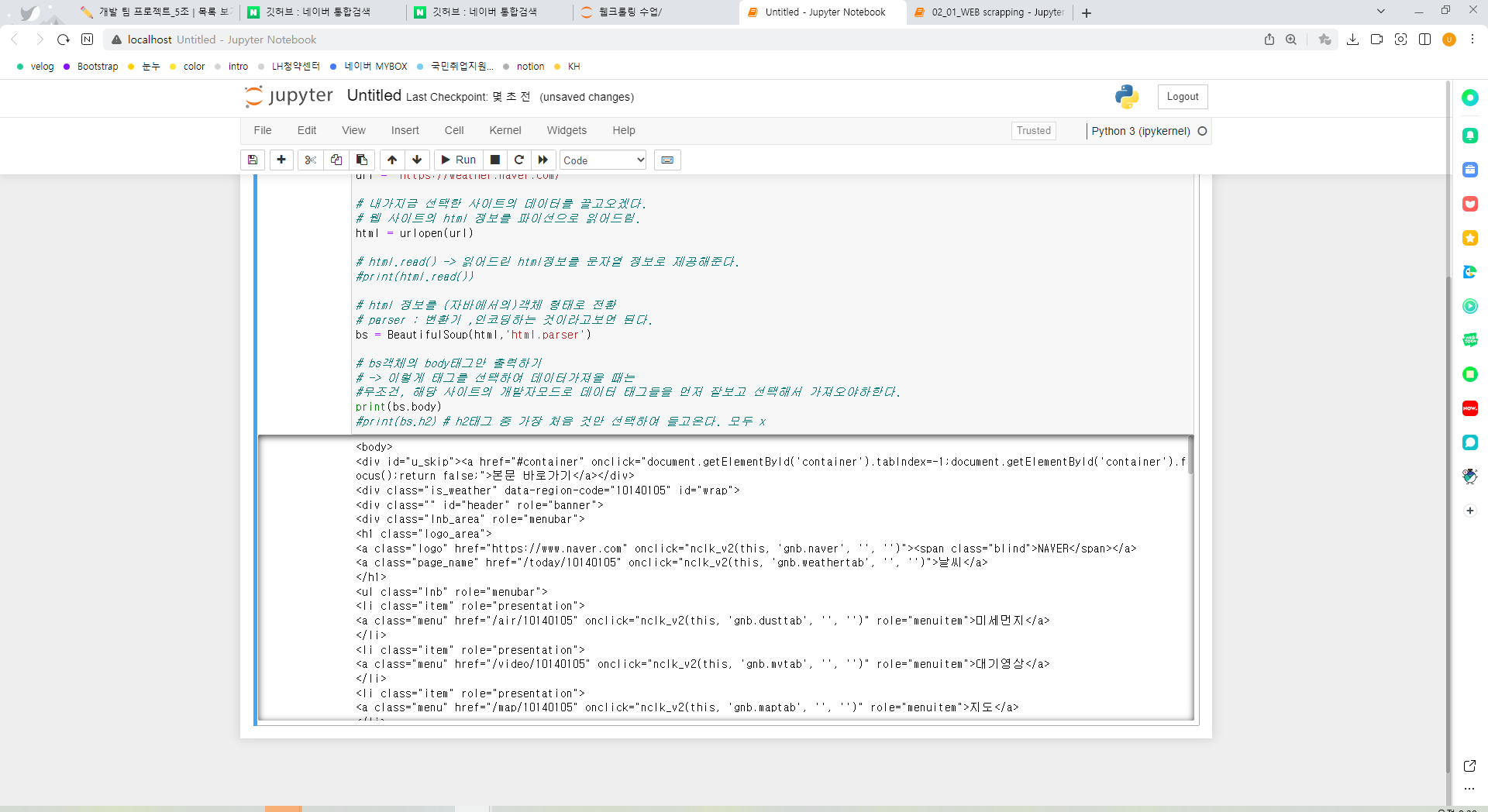
해당사이트의 body 태그 가장 첫번째만 선택하기
-
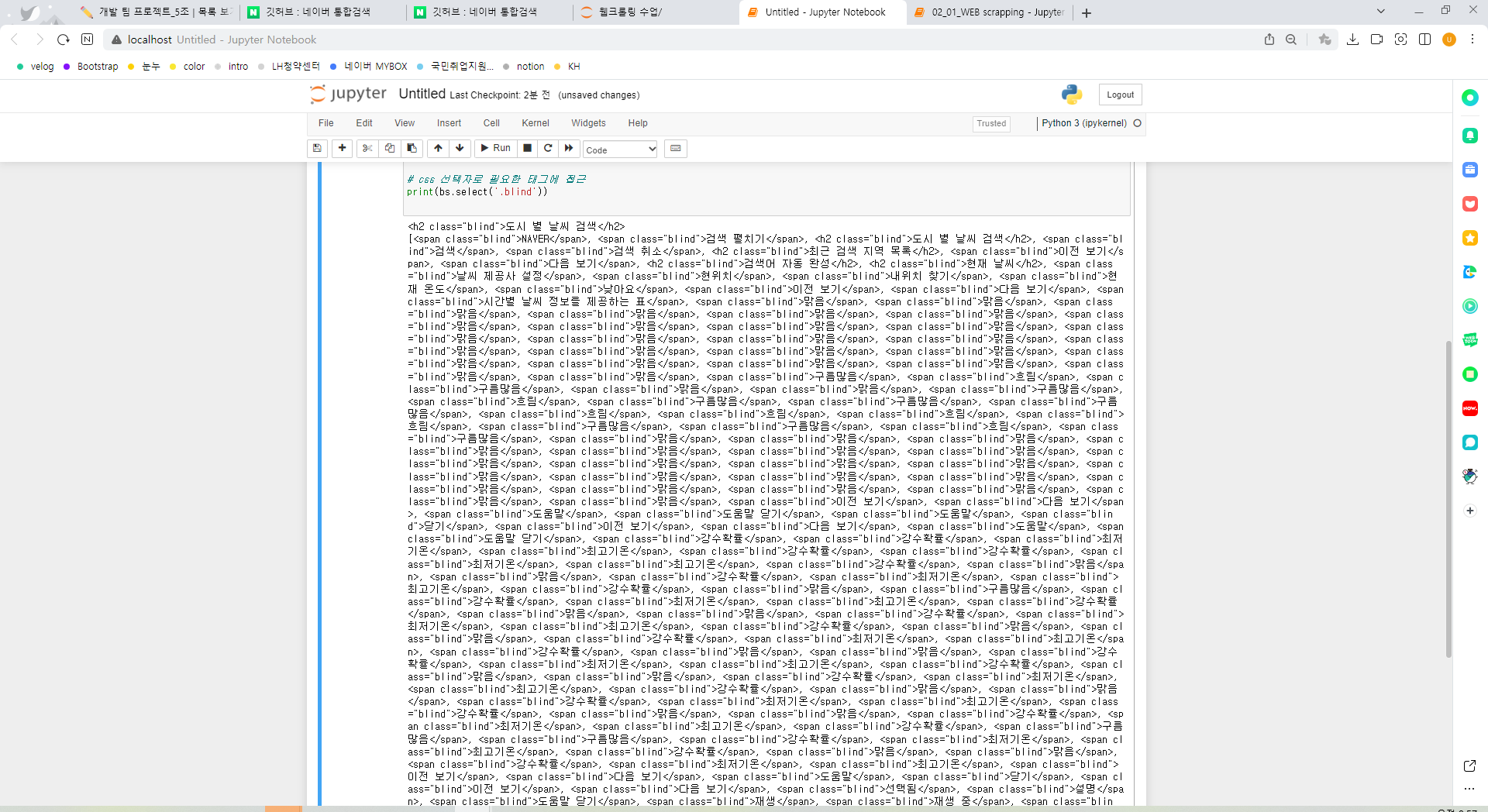
css 선택자로 필요한 태그에 접근
print(bs.select('.blind'))
: class가 blind인 것 모두 갖고오기
-
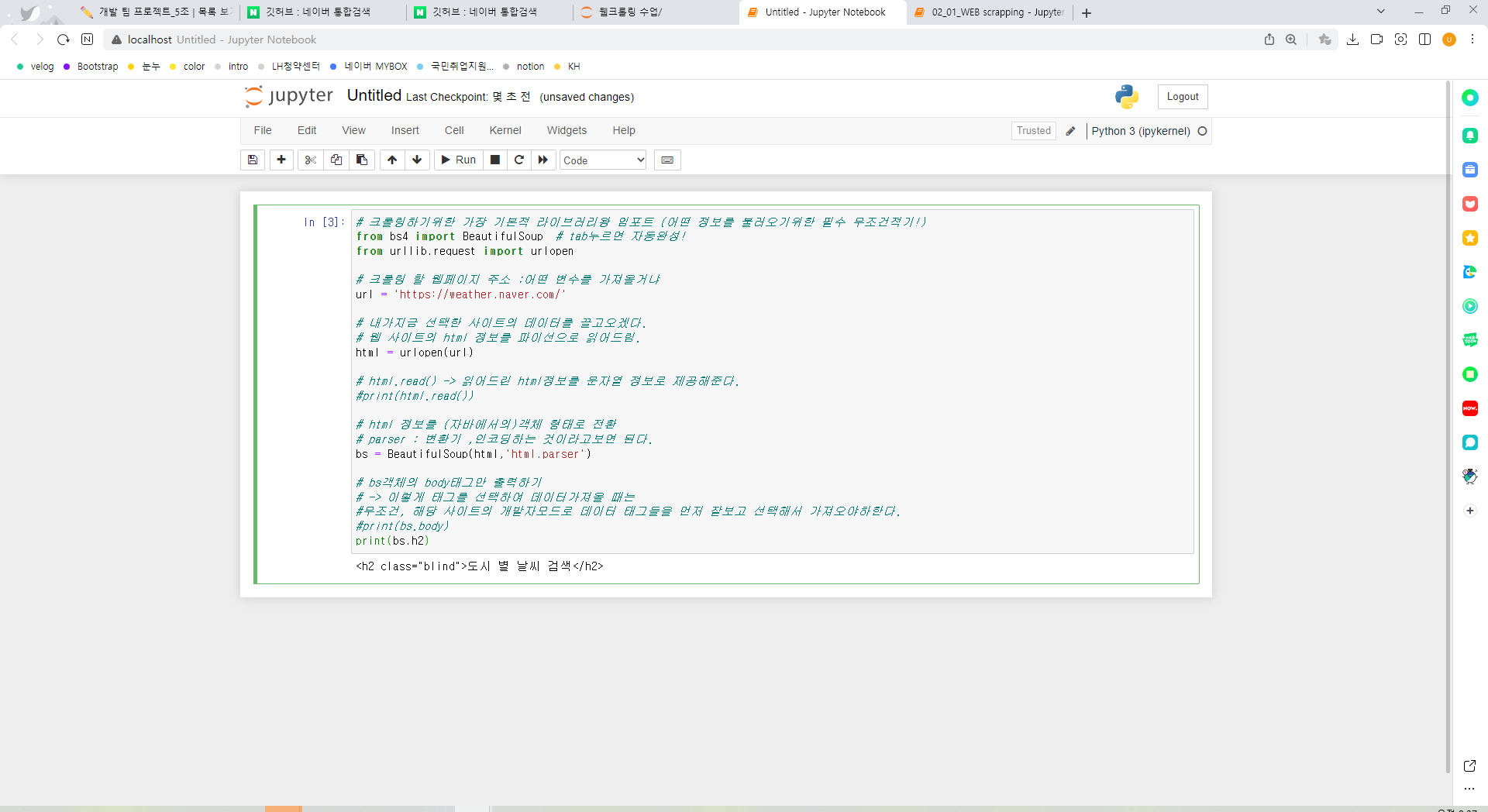
해당사이트의 h2태그만 선택하기
-
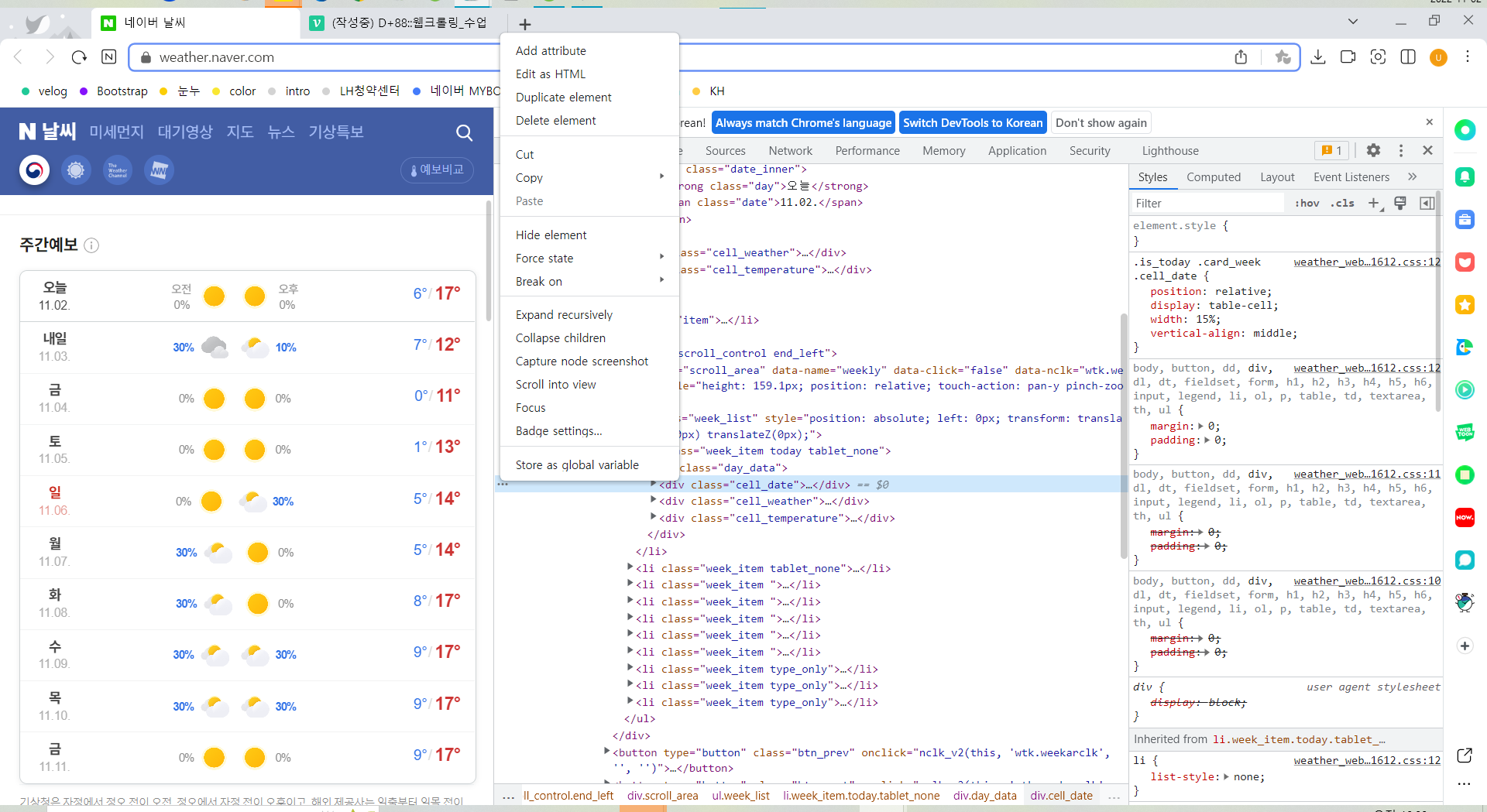
만약 개발자모드로 원하는 태그를 선택해서 가져오려면, 이렇게 개발자모드로 봤을 때 해당 선택태그의 왼쪽 점3개를 클릭하여 복사하면 된다.
bs.select('#hourly > div.weather_graph > div > div > div > table > thead > tr > th.data.heading > span')
-
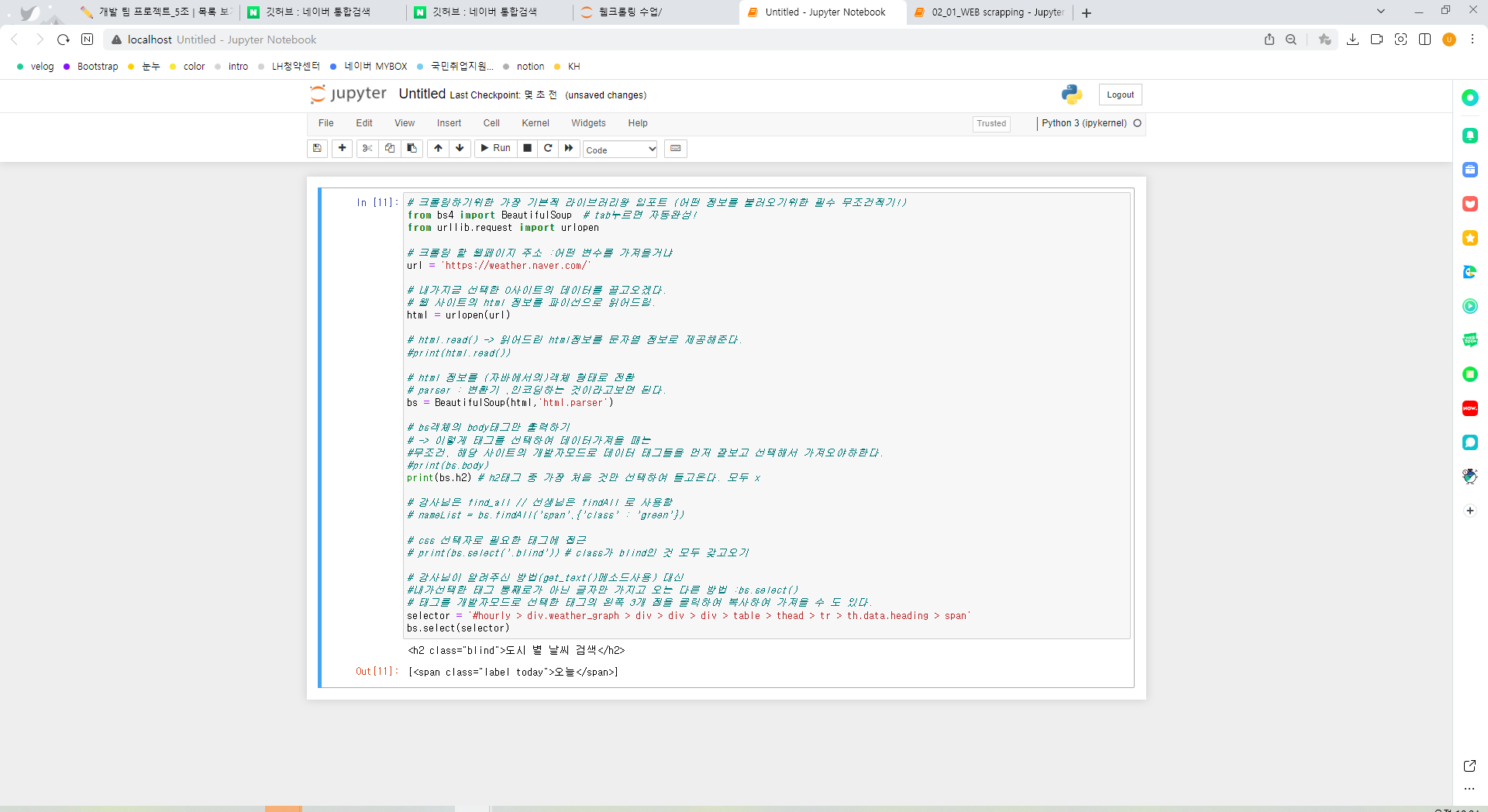
내가 선택한 태그의 전체 내용을 가져오는 것이 아니라
필요한 텍스트만 가져오는 방법
-
리스트로 나오는 것을 포문돌려 출력하기
# 크롤링하기위한 가장 기본적 라이브러리왕 임포트 (어떤 정보를 불러오기위한 필수 무조건적기!)
from bs4 import BeautifulSoup # tab누르면 자동완성!
from urllib.request import urlopen
# 크롤링 할 웹페이지 주소 :어떤 변수를 가져올거냐
url = 'https://weather.naver.com/'
# 내가지금 선택한 0사이트의 데이터를 끌고오겠다.
# 웹 사이트의 html 정보를 파이선으로 읽어드림.
html = urlopen(url)
# html.read() -> 읽어드린 html정보를 문자열 정보로 제공해준다.
#print(html.read())
# html 정보를 (자바에서의)객체 형태로 전환
# parser : 변환기 ,인코딩하는 것이라고보면 된다.
bs = BeautifulSoup(html,'html.parser')
# bs객체의 body태그만 출력하기
# -> 이렇게 태그를 선택하여 데이터가져올 때는
#무조건, 해당 사이트의 개발자모드로 데이터 태그들을 먼저 잘보고 선택해서 가져오야하한다.
#print(bs.body)
#print(bs.h2) # h2태그 중 가장 처음 것만 선택하여 들고온다. 모두 x
# 강사님은 find_all // 선생님은 findAll 로 사용함
# nameList = bs.findAll('span',{'class' : 'green'})
# css 선택자로 필요한 태그에 접근
# print(bs.select('.blind')) # class가 blind인 것 모두 갖고오기
# 강사님이 알려주신 방법(get_text()메소드사용) 대신
#내가선택한 태그 통째로가 아닌 글자만 가지고 오는 다른 방법 :bs.select()
# 태그를 개발자모드로 선택한 태그의 왼쪽 3개 점을 클릭하여 복사하여 가져올 수 도 있다.
selector = '#hourly > div.weather_graph > div > div > div > table > thead > tr > th.data.heading > span'
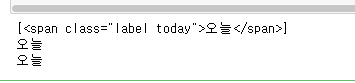
bs.select(selector) # [<span class="label today">오늘</span>] -> 대괄호에 싸여져 나온다.!! 이는 파이썬에서 리스트형태!!
print(bs.select(selector)) # 태그 전체를 출력 -> 리스트이다!
# 태그 안의 글자를 출력 : 그런데 여러개를 선택했는데 그중 하나의 글자를 선택하려면 선택한 글자들 하나하나를 선택해서 가져와야한다! for문돌리듯이
print(bs.select(selector)[0].get_text()) # 오늘
# 그래서 위에서 말한대로 포문돌려서 해보자
alltext = bs.select(selector)
for text in alltext:
one = text.get_text()
print(one)
- 출력결과
find_all