20221103_thu
BeautifulSoup
# title 가져오기
# 지난번 시간은 이미지가 모두 있는 경우였는데,
# 이번시간은 이미지가 없는 타이틀도 어떻게 예외처리해서 뽑아올 것인지 해봐라.
from urllib.request import urlopen
from bs4 import BeautifulSoup
# 예외처리해보기
from urllib.request import urlopen
from urllib.error import HTTPError
from urllib.error import URLError
html = urlopen('https://news.naver.com/main/list.naver?mode=LS2D&mid=shm&sid1=105&sid2=226')
bs = BeautifulSoup(html.read(), 'html.parser')
# [전체 기사 타이틀 뽑기]
#------------------------------------------------------------------------------#
# 기사 타이틀 전체 한꺼번에 뽑기. 클래스 한꺼번에 두개 선택한다.
target_class=["type06_headline", "type06"]
articles = bs.select_one("#main_content > div.list_body.newsflash_body ").select_one('li')
for target in target_class:
articlesss = bs.find("ul", {'class':target}).find_all('li')
for articlez in articlesss:
try:
atitle = articlez.dl.find_all('dl>dt')[1].a.text
except IndexError:
atitle = articlez.dl.find_all('dl>dt')[0].a.text
except:
pass
print(title.strip('|n|t'))# 줄띄움 + 탭
print(atitle)
#------------------------------------------------------------------------------#
# [각각 기사 타이틀 뽑아서 출력하기]
#------------------------------------------------------------------------------#
# 첫번째: 헤드라인은 1-10까지 존재하기 때문에 클래스가 type06_headline 인 기사
articles = bs.find("ul", {"class":"type06_headline"}).find_all("li")
# 두번째 : 헤드라인이 11-20까지 존재 클래스가 type06인 기사
articles2 = bs.find("ul", {"class":"type06"}).find_all("li")
#
# 위에 첫번째 두번째를 한꺼번에 전체 감싸서 처리하는 방법
# ul 태그는 리스트형태로 출력된다. 이를 반복문으로 추출한다.
totalArticles = bs.find("div", {"class":"list_body newsflash_body"}).find_all("li")
# print(totalArticles)
# 예외처리발생 index 에러 벗어났다.
for article in articles:
title='' # 타이틀 지정해주기.
try:
title=article.dl.find_all("dt")[1].a.text # 1번째가 있으면 타이틀가져오기
print(title)
except IndexError: #index 에러발생 예외처리
title=article.dl.find_all("dt")[0].a.text # 0번째 텍스트로 타이틀을 가져온다.
print(title)
except :
pass
# 두번째 : 헤드라인이 11-20까지 존재 클래스가 type06인 기사
articles2 = bs.find("ul", {"class":"type06"}).find_all("li")
for article2 in articles2:
title='' # 타이틀 지정해주기.
try:
title=article2.dl.find_all("dt")[1].a.text # 1번째가 있으면 타이틀가져오기
print(title)
except IndexError:
title=article2.dl.find_all("dt")[0].a.text # 0번째 텍스트로 타이틀을 가져온다.
print(title)
except :
pass
# 만약 에러가 난다면 inex에러가 나온다.
#------------------------------------------------------------------------------#Selenium
: 셋팅이 좀 걸린다. 자바스크립트를 실행하고 결과를 가져온다.
# 셀레니움 설치하기
# 코랩사용시 이후 다운로드설치 필요없지만
# 주피터이용시 구글링하여 크롭웹드라이버를 쳐서 다운로드가 필요하다.
!pip install selenium
!apt-get update # apt install을 정확히 실행하기 위해 ubuntu 업데이트
!apt install chromium-chromedriver
!cp /usr/lib/chromium-browser/chromedriver /usr/bin
import sys
sys.path.insert(0,'/usr/lib/chromium-browser/chromedriver')
from selenium import webdriver
chrome_options = webdriver.ChromeOptions()
chrome_options.add_argument('--headless')
chrome_options.add_argument('--no-sandbox')
chrome_options.add_argument('--disable-dev-shm-usage')
- 셀레니움 자체로 사이트 주소들어가서 바로 데이터 크롤링하는 것과 같다.
파이썬파일명:selenium스타벅스
파이썬_파일명: 넘파이
-
런타임 > 노트 설정 > none말고 다른 걸로 아무거나 선택하여 변경하기
: 이걸 선택하지 않으면 그래픽카드를 선택하지 않고 실행하는 것과 같기때문에 이는 본체에 그래픽카드를 넣어두고 실행하는 것과 같다.
-
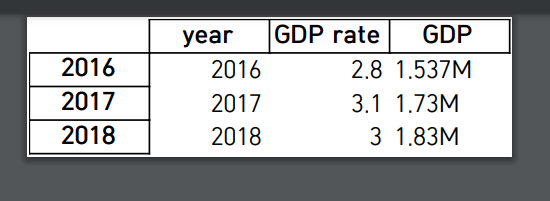
배열형식으로 만들어본 엑셀파일로 열어본 결과
정규식 Regular Expression

Dev.Vinch