
🔎 PREDICT YOUR MBTI!

입력받은 문장으로 화자의 MBTI를 추론해주는 서비스입니다.
🧐 왜 만들었나요?
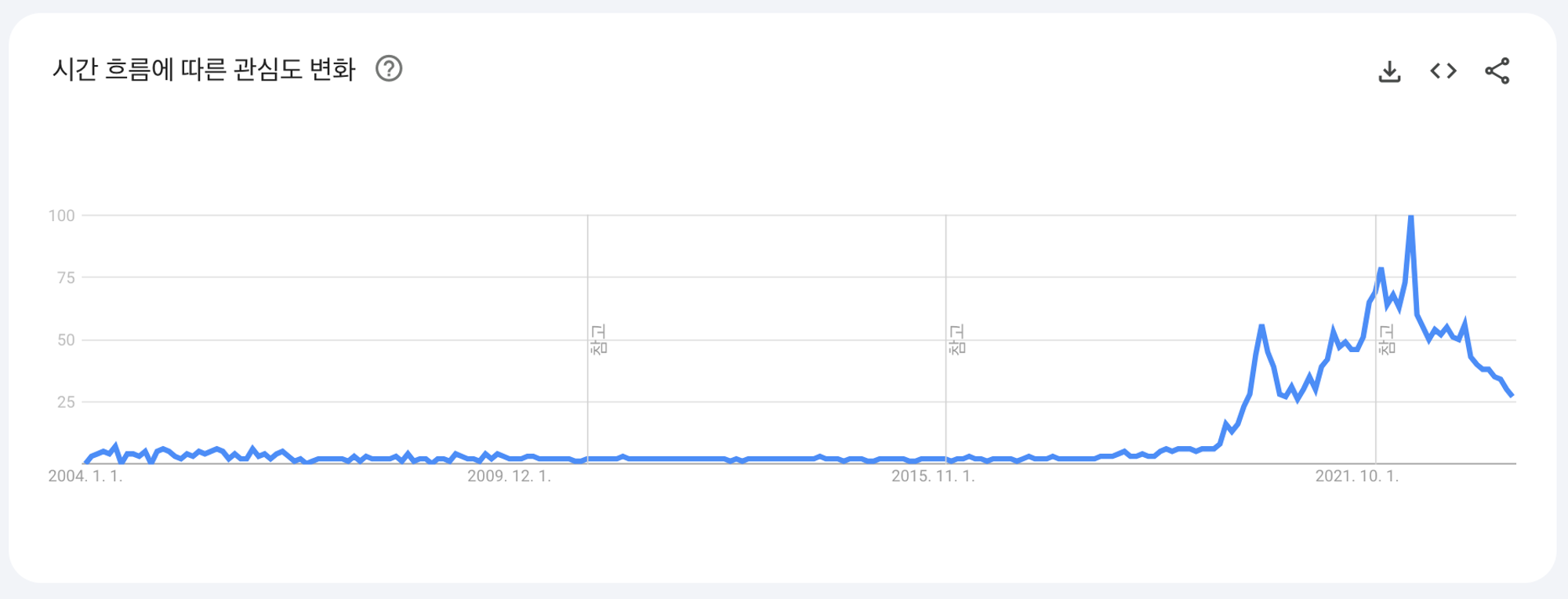
- 몇년 전부터 성격 유형 검사인 MBTI가 갑자기 엄청난 유행을 탔습니다.
그 후로 처음 만난 사람에게 아이스브레이킹을 위해 MBTI를 물어보곤 하는 등
MBTI는 우리의 일상에서 자연스럽게 녹아들었습니다. - MBTI 성격 유형 검사가 없던 시절에 살던 인물이나 가상 인물의 MBTI는 무엇일까 라는 궁금증이 생겼습니다.
- 데이터 분석을 통해서 과거 인물들이 쓰거나 말한 문장을 입력하면 MBTI를 예측해주는 프로그램을 만들어 궁금증을 해결해야겠다고 생각했습니다.
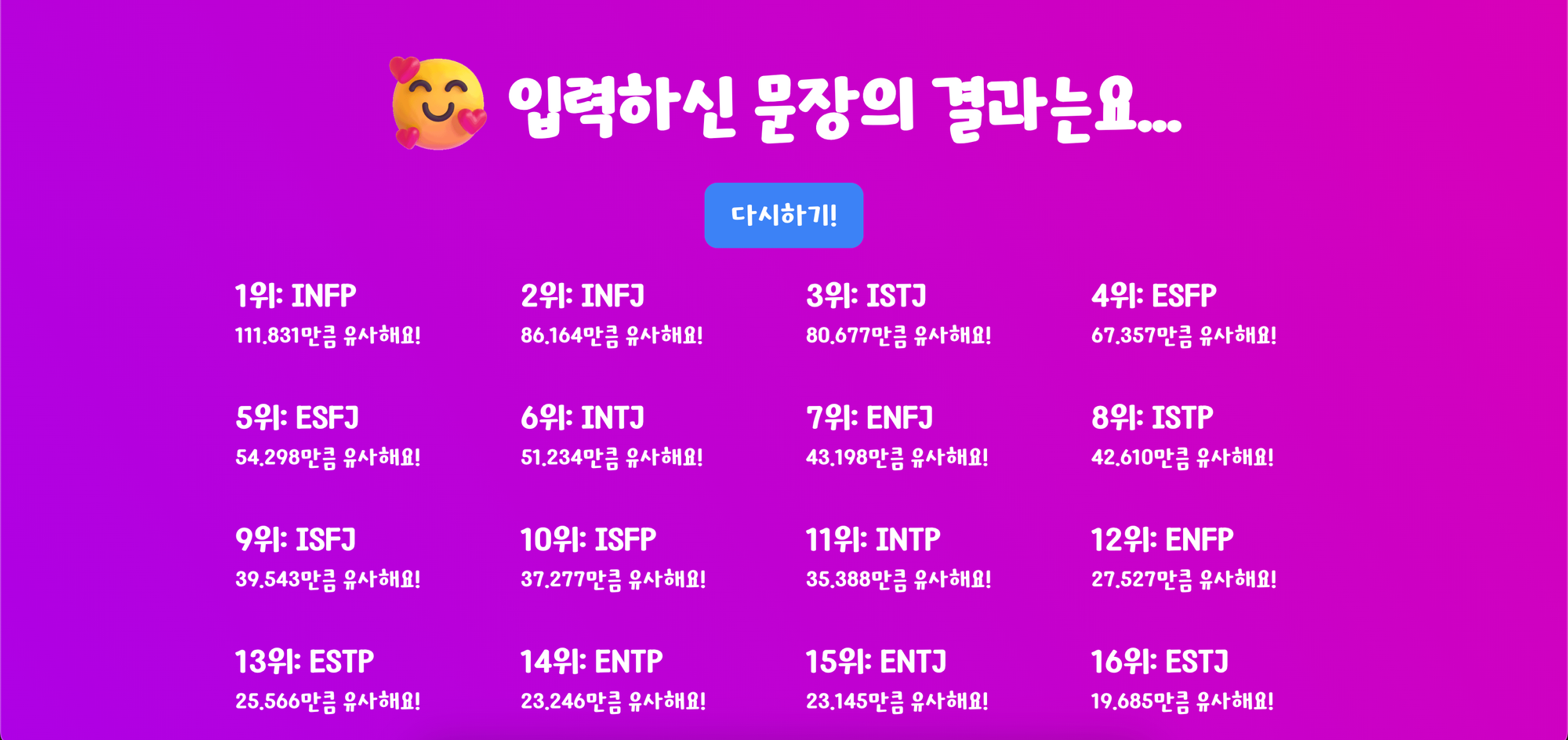
📋 사이트 미리보기

🖥️ 기술 스택
데이터 분석
- Pandas
- Matplotlib
- Numpy
서버
- Ngrok
- Flask
클라이언트
- React
- TypeScript
- Jotai
- tailwindcss
😎 이렇게 구현했어요
세 줄로 요약해드리자면...
- 영문으로 MBTI별 특징이 정리된 데이터를 찾아 한국어로 번역하여 모델을 생성했습니다.
- 이를 문장의 형태소 단위로 잘라 입력받은 문장을 통해 유사도를 도출하는 함수를 생성했습니다.
- 플라스크를 사용하여 API를 구축하고 리액트를 사용하여 API를 연결해 웹으로 서비스를 제공했습니다.
자세히 설명해드리자면...
먼저 kaggle.com에서 MBTI별 특징이 정리되어있는 csv를 찾아 해당 데이터를 이용하자고 생각했습니다.

해당 데이터에는 두 가지의 문제점이 있었습니다.
- 영어로 구성되어있어 한국어로 된 문장을 입력했을 때 데이터 분석이 불가능합니다.
- 리스트 형식으로 구성되어있어 한번 분석하는데에 데이터 매핑으로 인한 많은 시간이 소요됩니다.
이런 문제점을 데이터 학습을 통해 모델을 구축할 때 다음과 같이 해결하기로 결정했습니다.
for index, mbti in tqdm(mbti_list.iterrows()):
key = mbti['type']
content = mbti['posts']
translated_content = translator.translate(content, src="en", dest="ko")
mbti_dict[key] += translated_content.text- googletrans 라이브러리를 사용하여 영어로 구성된 데이터를 한국어로 번역했습니다.
- mbti별 딕셔너리를 만들어 번역된 문장을 한 문자열에 병합했습니다.
이렇게 되면 밑과 유사한 구조의 학습된 데이터를 얻을 수 있습니다.
{
"ISTJ": "직관 시작 편향 넌센스 시작 요구 직관 스마트 오만한 보험 직관적인 직관적 문제 이해 추상적인",
"ISFJ": "...",
...
}이 데이터를 기준으로 문장의 형태소를 잘라 비교해주는 함수를 정의했습니다.
def calculate_similarity(sentence, mbti_data):
sentence = sentence.lower()
similarities = {}
for mbti, traits in mbti_data.items():
mbti_traits = traits.lower()
matching_words = sum(word in sentence for word in mbti_traits.split())
similarity_percentage = (matching_words / len(mbti_traits.split())) * 100
similarities[mbti] = similarity_percentage
return similarities서비스를 웹 어플리케이션으로 제공하기 위해 플라스크를 사용하여 API를 구축했습니다.
app = Flask(__name__)
CORS(app)
run_with_ngrok(app)
@app.route("/mbti", methods=['POST'])
def home():
content = request.json['content']
similarities = calculate_similarity(content, mbti_dict)
response_data = {}
for mbti, percentage in similarities.items():
response_data[mbti] = percentage**3
return jsonify({"mbti": response_data})
app.run()클라이언트 단에서 리액트와 tailwindcss, Jotai, TypeScript를 사용하여 API를 연결하고 서비스 레이아웃을 구성했습니다.
🎥 시연 영상
유튜브에서 확인하실 수 있습니다! 바로가기
📖 추후 서비스 확장 계획
- d3 라이브러리를 사용하여 도출된 결괏값을 데이터 시각화를 통해 사용자에게 제공할 예정입니다.
- 현재보다 더욱 많은 데이터를 학습시킨 모델을 기준으로, 결과를 더 정확하게 도출시킬 예정입니다.
- 사용자에게 특정 문장을 제시하고, 해당 문장 작성자의 MBTI를 맞추는 퀴즈 게임을 구현할 예정입니다.
- 현재는 문장을 형태소 단위로 잘라 판단하고 있으나, 더욱 정교한 알고리즘을 구상하여
- 문장 전체적인 분위기를 파악해 유사도를 도출하게 로직을 변경할 예정입니다.
- 어떤 단어나 문장에서 어떤 MBTI와 유사도가 높았는지를 따로 보여주는 레이아웃을 제공할 예정입니다.
😀 느낀 점
- 굉장히 다양한 도메인에서 데이터 분석을 유용하게 사용할 수 있다는 것을 느꼈습니다.
- 데이터 분석을 통해 이 프로젝트 외에도 유익 또는 흥미있는 서비스를 만들 수 있다는 것을 느꼈습니다.
- 간단한 서비스에도 데이터 분석을 사용하면 서비스의 퀄리티가 매우 높아진다는 것을 느꼈습니다.
🥹 마무리
학교에서 데이터 분석 수업시간 때 수행평가로 토이 프로젝트를 만들어와야했는데,
아이디어를 구상하는 데에 시간을 다 쓰다보니 급하게 만들었던 서비스입니다.
그런데 선생님께서 매우 긍정적으로 해당 프로젝트를 봐주셔서
별 건 없지만 짧게나마 회고를 해보았습니다.
다음에도 시간이 된다면 데이터 분석을 이용해서 재미있는 사이트를 만들어볼 것 같습니다!
긴 글 읽어주셔서 감사합니다! 항상 화이팅입니다~~

프론트엔드 공부중

배포해주세요잉