

Ch06. 메모리와 캐시 메모리
메인 메모리
RAM (Random Access Memory)
- 휘발성 메모리
- 데이터 읽기, 쓰기 가능
- 실행 중인 프로그램과 데이터 저장
ROM (Read Only Memory)
- 비휘발성 메모리 (영구 저장)
- 데이터 읽기만 가능
- 시스템 부팅에 필요한 BIOS, 펌웨어 등 저장
RAM의 종류
RAM 용량이 크면 많은 프로그램을 동시에 빠르게 실행할 수 있어 성능이 향상됨. (일정 수준 이상에서는 큰 차이 없음)
-
DRAM (Dynamic RAM)
- 시간이 지나면 데이터가 동적으로 사라지는 RAM -> 데이터 재활성화 필요
- 일반적으로 메인메모리로 사용
-
SRAM (Static RAM)
- 전원이 켜져 있는 동안 데이터가 유지되는 RAM
- 보통 캐시 메모리에 사용
| DRAM | SRAM | |
|---|---|---|
| 재충전 | 필요 | X |
| 속도 | 느림 | 빠름 |
| 가격 | 저렴함 | 비쌈 |
| 집적도 | 높음 | 낮음 |
| 소비 전력 | 적음 | 높음 |
| 사용 용도 | RAM | 캐시 메모리 |
-
SDRAM (Synchronous Dynamic RAM)
- 클럭 신호와 동기화된 DRAM
- 클럭에 맞춰 CPU와 정보를 주고 받을 수 있는 DRAM
- SDR SDRAM (Single Data Rate SDRAM)으로도 불림.
-
DDR SDRAM (Double Data Rate SDRAM)
- 대역폭(date rate, 데이터를 주고 받는 길의 너비)을 2배 넓혀 속도를 높인 SDRAM
- 한 클럭당 CPU와 데이터를 2번 주고받을 수 있음.
| 대역폭 | 명칭 |
|---|---|
| 2 | DDR SDRAM |
| 4 | DDR2 SDRAM |
| 8 | DDR3 SDRAM |
물리 주소와 논리 주소
- 물리 주소: 실제로 데이터가 저장된 HW상의 주소, 메모리 HW가 사용하는 주소
- 논리 주소: 실행 중인 프로그램 각각에 부여된 0번지부터 시작하는 주소, CPU와 실행 중인 프로그램이 사용하는 주소
메모리에 저장된 정보는 계속에서 변하기 때문에 CPU와 실행 중인 프로그램은 메모리의 물리 주소를 알지 못함.
-> 따라서 CPU와 메모리가 상호작용하기 위해서는 논리 주소와 물리 주소 간에 변환이 필요
- 메모리 관리 장치(MMU; Memory Menagement Unit): 논리 주소 -> 물리 주소의 변환 수행
- CPU와 주소 버스 사이에 위치
- CPU가 발생시킨 논리 주소 + 베이스 레지스터 값 => 물리 주소
ex) 베이직 레지스터: 1000, 논리 주소: 100 => 물리 주소: 1100 - 베이직 레지스터: 프로그램의 시작 물리 주소 저장
메모리 관리 기법
논리 주소 범위(실행 중인 프로그램 외)를 벗어나는 명령어 실행 방지
각 프로그램이 독립적으로 실행될 수 있도록 보호
- 한계 레지스터: 논리 주소의 최대 크기 저장
프로그램 물리 주소 범위: 베이스 레지스터 값 ~ (베이스 레지스터 값 + 한계 레지스터 값)
CPU는 메모리에 접근할 때 먼저 접근하고자 하는 논리 주소가 한계 레지스터보다 작은지 검사함.
접근하려는 논리 주소가 한계 레지스터보다 크면 인터럽트(트랩) 발생
저장 장치 계층 구조
각기 다른 저장 장치들을 계층화하여 표현한 구조
- CPU와 저장 장치가 가까울수록 빠르다.
- 속도가 빠른 저장 장치는 용량이 작고 가격이 비싸다.
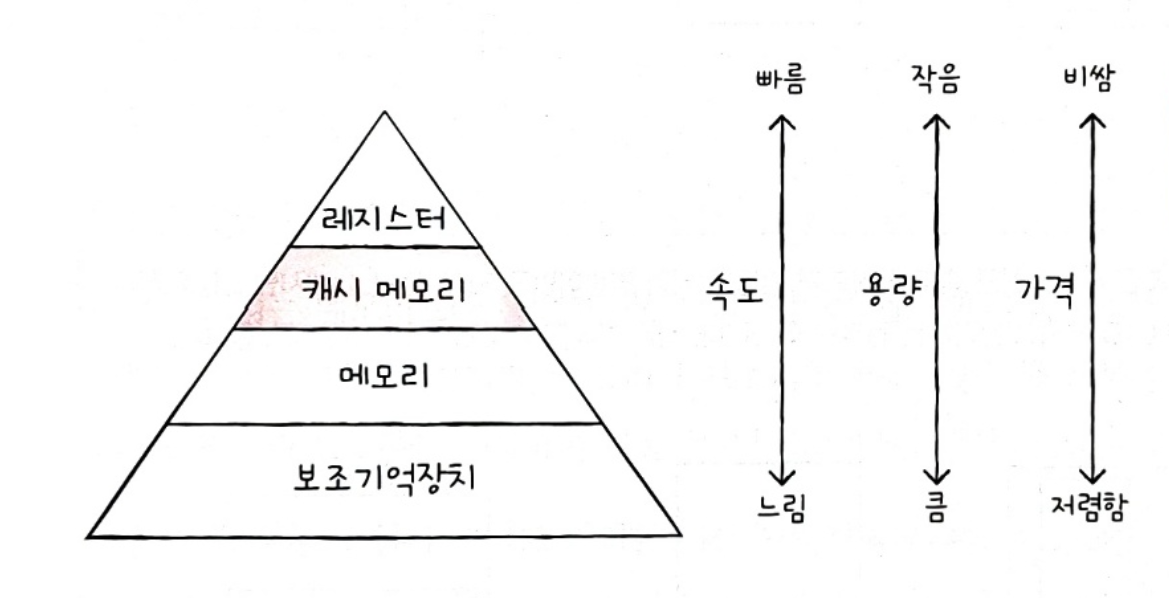
캐시 메모리
-
등장 배경: 기술 발전으로 CPU의 연산 속도가 급격히 증가하면서 CPU와 메인 메모리 간의 속도 차이로 발생하는 병목 현상을 해결하기 위해 도입
-
CPU와 메인 메모리 사이에 위치한 SRAM 기반의 고속 메모리
-
캐시 계층 구조
- 코어와 가까운 순서대로 계층을 구성
- L1 캐시 - L2 캐시 - L3 캐시
- 용량: L1 < L2 < L3
- 속도: L1 > L2 > L3
- 가격: L1 < L2 < L3
- 접근 순서: L1 > L2 > L3
L1, L2 캐시는 코어마다 존재하고, L3 캐시는 여러 코어가 공유하는 형태
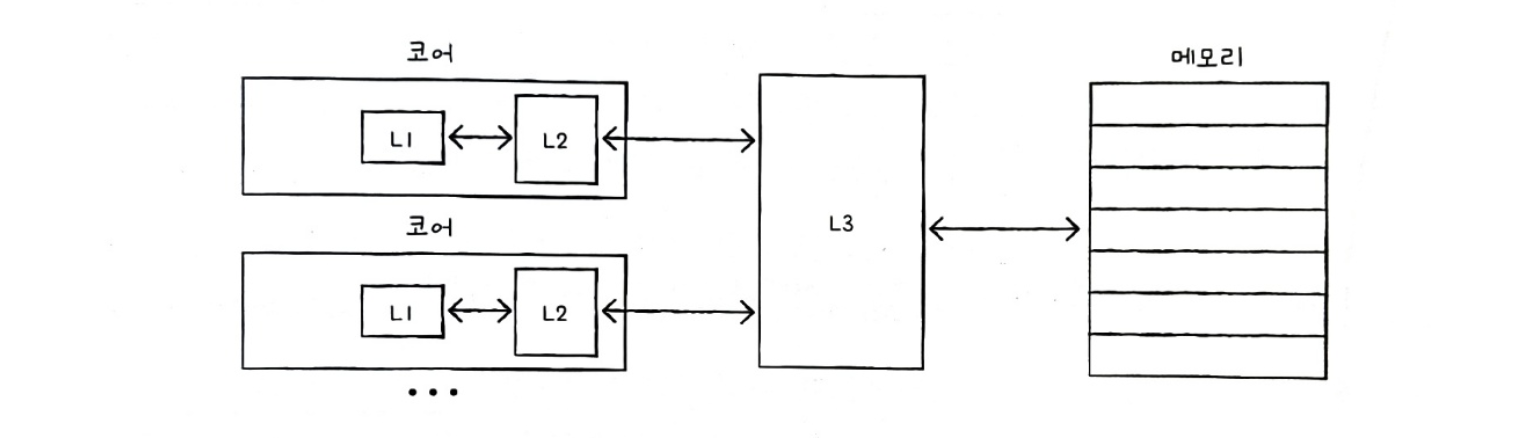
- 캐시 히트 (Cache Hit): 요청한 데이터가 캐시에 있는 상태
- 캐시 미스 (Cache Miss): 요청한 데이터가 캐시에 없는 상태. 메모리에서 데이터를 읽어 옴.
- 캐시 적중률: 캐시 히트 횟수 / 전체 기억장치 엑세스 횟수
참조 지역성 원리 (Locality of Reference)
CPU가 메모리에 접근할 때의 주된 경향을 바탕으로 만들어진 원리
- 시간 지역성 (temporal locality): 최근에 접근했던 메모리 공간에 다시 접근할 가능성이 높다.
- 공간 지역성 (spatial locality): 접근한 메모리 공간의 근처를 접근할 가능성이 높다.
캐시 메모리는 참조 지역성 원리에 따라 사용할 데이터를 예측하고 캐시 적중률을 높임.
Ch07. 보조기억장치
하드 디스크
데이터를 플래터 표면에 자기적으로 저장하는 보조기억장치
-
구성 요소
- 플래터(pplatter)
- 회전하는 원판으로, 표면에 데이터를 자기적으로 저장함.
- 여러 트랙이 있고, 각 트랙은 여러 섹터로 구성됨. - 스핀들(spindle)
- 플래터를 회전시키는 부품 - 헤드(head)
- 바늘처럼 생긴 부품으로, 데이터를 읽고 씀. - 디스크 암(disk arm)
- 헤드를 이동시키는 장치
- 플래터(pplatter)
-
플래터의 데이터 저장 단위
- 트랙 (track): 동심원 형태로 배열된 데이터 저장 단위
- 섹터 (sector): 트랙을 구성하는 기본 데이터 저장 단위. 트랙의 작은 조각
하드 디스크의 가장 작은 전송 단위. - 실린더 (cylinder): 여러 플래터의 동일한 트랙 번호가 결합된 논리적 단위
-
디스크 접근 동작 순서
- 헤드를 해당 트랙으로 이동
- 원하는 섹터가 헤드 아래로 회전되어 올 때까지 대기
- 데이터 전송
-
디스크 접근 시간
= 탐색 시간 + 회전 지연 + 전송 시간
- 탐색 시간 (seek time): 임의의 트랙에서 원하는 트랙으로 헤트를 이동시키는 시간
- 회전 지연 (rotational latency): 헤드가 있는 곳으로 플래터를 회전시키는 시간
- 전송 시간 (transfer time): 하드 디스크와 컴퓨터 간에 데이터 전송 시간
플래시 메모리
전기적으로 데이터를 읽고 쓸 수 있는 반도체 기반 보조기억장치
- NAND 플래시 메모리: 대용량 데이터 효율적 저장. ex) USB 플래시 드라이브, SSD, 메모리 카드
- NOR 플래시 메모리: 주로 실행 코드 저장. ex) 펌웨어, BIOS
- 셀 (cell): 플래시 메모리에서 데이터를 저장하는 가장 작은 단위
- 셀 구조에 따른 플래시 메모리 종류
| SLC (Single-Level Cell) | MLC (Multi-Level Cell) | TLC (Triple-Level Cell) | |
|---|---|---|---|
| 셀당 bit | 1bit | 2bit | 3bit |
| 수명 | 긺 | 보통 | 짧음 |
| 성능 | 빠름 | 보통 | 느림 |
| 가격 | 높음 | 보통 | 낮음 |
- 플래시 메모리 데이터 저장 단위
- 페이지: 여러 셀로 구성된 데이터 읽기와 쓰기 단위
- 블록: 여러 페이지로 구성된 데이터 삭제 및 프로그램 단위
- 플레인: 여러 블록이 모인 단위
- 다이: 여러 플레인이 모인 단위
Ch08. 입출력장치
장치 컨트롤러
-
등장 배경
- 장치의 종류가 매우 다양하여 정보를 주고 받는 방식을 규격화하기 어려움.
- CPU와 메모리에 비해 I/O장치의 데이터 전송률이 낮음. -> 병목 현상
-
역할
- CPU와 I/O장치 간의 통신 중개
- 오류 검출
- 데이터 버퍼링: 데이터를 버퍼(buffer)에 일시적으로 저장하여 장치 간에 전송률을 비슷하게 맞추는 방법
=> 전송률이 낮은 I/O장치와의 전송률 차이를 데이터 버퍼링으로 완화
-
구성
- 데이터 레지스터: CPU와 I/O장치 사이에 주고 받을 데이터가 담기는 레지스터. 버퍼 역할
- 상태 레지스터: I/O장치의 상태 정보 저장
- 제어 레지스터: I/O장치가 수행할 내용에 대한 제어 정보와 명령 저장
장치 드라이버
장치 컨트롤러가 컴퓨터 내부와 정보를 주고 받을 수 있도록 하는 프로그램
- 장치 제어
- 장치와 SW 간의 인터페이스 제공
기본 숙제
p.185 확인 문제 3번
주로 캐시 메모리로 활용된다. ( SRAM )
주로 주기억장치로 활용된다. ( DRAM )
대용량화하기 유리하다. ( DRAM )
집적도가 상대적으로 낮다. ( SRAM )
p.205 확인 문제 1번
레지스터 - 캐시 메모리 - 메모리 - 보조기억장치
추가 숙제
RAID의 정의와 종류 간단히 정리해보기
RAID (Redundant Array of Independent Disks)
데이터의 안전성과 높은 성능을 위해 여러 하드 디스크나 SSD를 마치 하나의 장치처럼 사용하는 기술
-
등장 배경: 크기가 작은 여러 개의 디스크들을 서로 연결하여 하나의 큰 용량을 가진 디스크 배열을 구성하면 보다 저렴한 가격으로 더 큰 용량을 가진 디스크 서브시스템을 구성할 수 있음.
=> 각 디스크에 데이터를 분산 저장하여 동시 액세스 가능, 병렬 전송으로 데이터 전송 시간 단축
=> 그러나 고장 가능성 증가 (MTTF 단축) *MTTF(Mean Time To Failure): 결함 발생 평균 기간
RAID는 이를 개선하기 위해(결함 허용도를 높이기 위해) 제안됨. -
핵심 기술: 검사 디스크(check disk)들을 이용해 오류 검출 및 복구 기능 추가
RAID 레벨
-
RAID 0 - 스트라이핑
데이터를 스트라이핑하여 여러 디스크에 분산 저장하는 방식
* stripe: 분산되어 저장된 데이터
장점: 데이터 동시에 읽고 쓰기 가능 -> 읽기, 쓰기 성능 향상
단점: 데이터 중복 X -> 데이터 보호 X, 신뢰성 낮음. -
RAID 1 - 미러링
데이터를 미러링하여 동일한 데이터를 두 개에 디스크에 동시에 저장하는 방식
장점: 신뢰성 향상, 간단한 데이터 복구, 읽기 성능 향상
단점: 저장 용량 감소(전체 디스크의 절반만 사용), 디스크가 하나일 때와 쓰기 성능 동일 -
RAID 4
블록 레벨 스트라이핑 + 전용 패리티 디스크
* parity bit: 오류를 검출하고 복구하기 위한 정보
* 패리티 디스크: 오류 검출 및 복구에 사용되는 디스크
장점: 읽기 성능 향상
단점: 낮은 쓰기 성능 - 쓰기 작업마다 전용 패리티 디스크를 업데이트해야 하므로 여러 쓰기 작업이 동시에 발생하면 병목 현상 발생 -
RAID 5
블록 레벨 스트라이핑 + 분산 패리티. 패리티 정보를 분산하여 저장하는 방식
장점: RAID 4의 병목 현상 개선 - 패리티 정보가 여러 디스크에 분산 저장되므로 특정 디스크에 병목이 발생하지 않음.
단점: RAID 4보다 복구 과정 복잡 - 패리티 정보가 분산되어 있으므로 각 디스크에서 정보를 읽어와야 함. -
RAID 6
블록 레벨 스트라이핑 + 이중 분산 패리티. 두 개의 독립적인 패리티를 두는 방식
장점: RAID 5의 복구 문제 개선 - RAID 5는 하나의 디스크 고장만 복구할 수 있지만 RAID 6는 두 개의 디스크가 동시에 고장 나도 복구할 수 있음. -> 높은 신뢰성
단점: RAID 5보다 쓰기 성능 낮음.
