Hybrid Search란
키워드 기반 검색인 Lexical Search와 유사도 기반 검색인 Semantic Search는 각각 장단점이 있고 사용이 유리한 상황이 서로 다르다.
Lexical Search : OpenSearch와 같은 전통적인 검색 엔진에서 주로 사용되는 방법으로, BM25와 같은 희소 벡터 알고리즘을 통해 키워드 기반 매칭을 진행한다. 특정 도메인 용어를 검색하기에 용이하지만 오타 및 동의어에 취약하다.
Semantic Search : 키워드가 일치하지 않더라도 의미론적으로 유사한 검색 결과를 반환한다. 검색 결과는 임베딩 품질에 의존도가 높다.
Hybrid Search는 각 검색 방법의 장점만을 추려 사용된다. 특정 도메인 용어나 제품 용어가 포함된 쿼리로 검색했을 때도 Lexical Search의 검색 결과를 통해 보조한다. 의미론적으로 유사한 동의어 검색의 경우 및 오타가 일부 포함되더라도 Semantic Search가 벡터 기반으로 가장 가까운 내용을 반환하기 때문에 보다 정확도를 높일 수 있다.
Lexical Search와 Semantic Search의 결과를 결합하는 방법은 크게 총 2가지가 존재한다. CC(Convex Combination), RRF(Reciprocal Rank Fusion)의 2가지 방법으로, 아래와 같이 간단히 요약할 수 있다.
-
CC : Lexical Search와 Semantic Search 각각 문서의 모음에 아래와 같이 가중치(α, β)를 부여하여 취합한다.
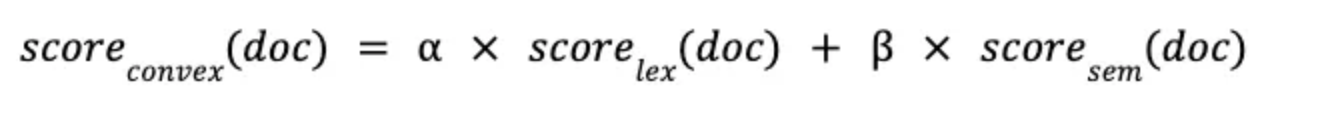
-
RRF : 쿼리를 실행할 때 순위가 매겨진 문서를 반환하며, 취합 시에 상단이 위치한(순위가 높은) 문서에 점수를 부여한다. 이때, k 값은 순위가 낮은 문서의 조정을 위한 상수이다.
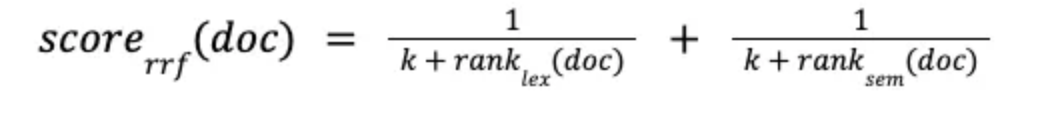
LangChain을 통한 Hybrid Search 구현 방법
Hybrid Search를 위한 LangChain의 EnsembleRetriever는 각기 다른 쿼리 응답의 조합을 위해 RRF 기법을 채택한다. 아래와 같은 코드로 작성할 수 있겠다. OpenSearchLexicalSearchRetriever를 위한 코드 구성은 링크를 참고할 것을 권장한다.
from langchain.retrievers import EnsembleRetriever
from langchain_community.vectorstores import OpenSearchVectorSearch
vector_db = OpenSearchVectorSearch(
index_name=index_name,
opensearch_url=oss_endpoint,
embedding_function=embeddings,
http_auth=http_auth,
is_aoss =False,
engine="faiss",
space_type="l2"
)
# Sementic Retriever(유사도 검색, 3개의 결과값 반환)
opensearch_semantic_retriever = vector_db.as_retriever(
search_type="similarity",
search_kwargs={
"k": 3
}
)
search_semantic_result = opensearch_semantic_retriever.get_relevant_documents(query)
opensearch_lexical_retriever = OpenSearchLexicalSearchRetriever(
os_client=os_client,
index_name=index_name
)
# Lexical Retriever(키워드 검색, 3개의 결과값 반환)
opensearch_lexical_retriever.update_search_params(
k=3,
minimum_should_match=0
)
search_keyword_result = opensearch_lexical_retriever.get_relevant_documents(query)
# Ensemble Retriever(앙상블 검색)
ensemble_retriever = EnsembleRetriever(
retrievers=[opensearch_lexical_retriever, opensearch_semantic_retriever],
weights=[0.50, 0.50]
)
search_hybrid_result = ensemble_retriever.get_relevant_documents(query)아래와 같이 실제 LLM을 호출할 때 context로 EnsembleRetriever의 결과인 search_hybrid_result를 전달하면 Hybrid Search를 수행할 수 있다.
라마인덱스에서의 hybridsearch 구현
하이브리드 검색에 적합한 Retriever 선택
키워드 검색을 위한 Retriever:
BM25Retriever 또는 SimpleKeywordTableRetriever:
BM25는 텍스트의 빈도와 관련성을 기준으로 순위를 매기는 알고리즘으로, 전통적인 키워드 검색에 적합합니다.
SimpleKeywordTableRetriever는 키워드를 기반으로 문서를 인덱싱하고, 입력된 검색어와 정확히 일치하는 키워드가 포함된 문서를 반환하는 단순한 키워드 검색 방식입니다.
이 중 BM25Retriever가 좀 더 발전된 키워드 검색 방식으로, 문서의 길이와 검색어 빈도를 고려한 순위 계산을 합니다.
시맨틱(유사도) 검색을 위한 Retriever:
EmbeddingRetriever 또는 GPTSimpleVectorRetriever:
EmbeddingRetriever는 문서와 검색어를 임베딩 벡터로 변환하여, 유사도를 기반으로 문서 간의 의미적 연관성을 찾아줍니다.
GPTSimpleVectorRetriever도 비슷하게 GPT나 LLM(대규모 언어 모델)의 임베딩을 사용하여 의미 기반 검색을 수행합니다.
EmbeddingRetriever가 벡터 기반 검색을 처리하는데 적합하고, 특히 LlamaIndex에서는 이러한 임베딩을 사용하여 시맨틱 검색을 처리할 수 있습니다.
하이브리드 검색을 위해 두 가지를 결합하는 방식:
HybridRetriever:
HybridRetriever는 키워드 검색과 시맨틱 검색을 동시에 수행한 후, 두 결과를 결합하여 사용자에게 반환하는 방식입니다.
키워드와 의미적 유사성을 동시에 고려하는 것이 핵심입니다.
HybridRetriever는 검색 결과의 가중치를 조정하여, 특정 검색 방식에 더 큰 비중을 둘 수도 있습니다.
WeightedRetriever:
WeightedRetriever는 다양한 리트리버의 결과에 가중치를 부여하여 결과를 결합할 수 있습니다.
예를 들어, 키워드 검색 결과에 70%, 시맨틱 검색 결과에 30% 가중치를 줄 수 있습니다.
SimpleDirectoryReader를 사용하지 않는 이유는 데이터의 형식 때문입니다. 사용자가 제공한 데이터는 Excel 파일 형식으로 되어 있기 때문에, SimpleDirectoryReader 대신 pandas를 사용하여 데이터를 로드하고 처리하는 것이 더 적합합니다.
- ServiceContext
ServiceContext는 임베딩 모델, LLM(대규모 언어 모델), 텍스트 분할기 등 서비스와 관련된 설정을 관리합니다. 주로 문서 처리에 필요한 다양한 설정과 모델을 관리하는 데 사용됩니다.
역할:
임베딩 모델: 텍스트를 벡터로 변환하기 위한 모델 설정.
LLM: 질의에 답변을 생성하거나 요약을 수행하는 데 사용되는 대규모 언어 모델 설정.
텍스트 분할기: 긴 문서를 처리할 때 일정한 크기로 나누는 역할을 하는 문서 분할기 설정.
기타 서비스 관련 설정: 다른 외부 API와의 상호작용을 포함한 여러 서비스 관련 설정을 관리.
- StorageContext
StorageContext는 인덱스 데이터를 저장하고 불러오는 방법을 관리합니다. 즉, 생성된 인덱스와 벡터 데이터를 디스크 또는 데이터베이스(예: Chroma)와 같은 외부 스토리지에 저장하거나, 이미 저장된 인덱스를 불러오는 역할을 합니다.
역할:
인덱스 저장: 생성된 인덱스를 디스크나 데이터베이스에 저장.
인덱스 로드: 이전에 저장된 인덱스를 불러와 재사용.
벡터 스토어 설정: Chroma, Pinecone 등 벡터 스토어를 설정하고 관리.
데이터 관리: 인덱스와 임베딩 벡터를 저장하거나 로드할 때의 관리 작업.
요약:
ServiceContext:
문서 처리 및 임베딩, LLM, 텍스트 분할기 등의 서비스 관련 설정을 관리합니다.
임베딩 모델, LLM, 텍스트 처리 방법 등을 정의하는 데 사용됩니다.
StorageContext:
인덱스 데이터의 저장 및 불러오기를 관리합니다.
벡터 스토어(Chroma, Pinecone 등)를 설정하여 벡터 데이터를 저장하고, 디스크나 외부 스토리지에 인덱스를 저장하거나 로드하는 역할을 합니다.
