LLM에 학습과정에 포함되어있지 않은 지식을 주입하는 방법 크게 2가지
1. Fine-Tuning :
- 공부 진짜 열심히 해서 실제로 그 지식 습득

2. RAG(Retrieval-Augmented Geneartion) 검색 증강
- 오픈북 시험 / 누가 질문하면 질문에 답변할 수 있는 부분을 찾아서 답변
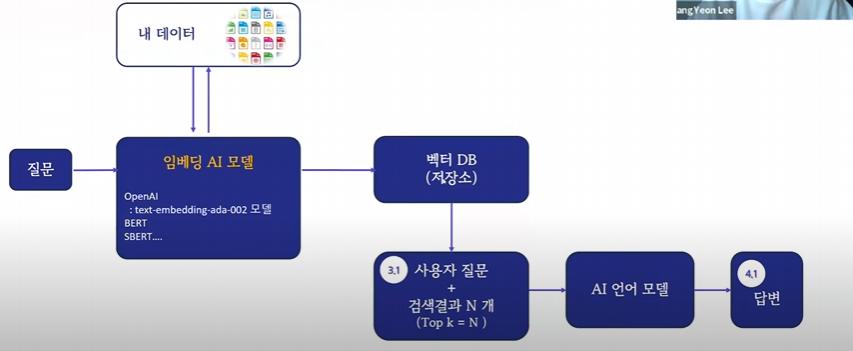
기본흐름

chatgpt는 이미 학습된 걸 바탕으로 답변
rag 내가 올린 데이터 기반으로 답변
과정
- 새로운 지식에 관한 텍스트 데이터(pdf, txt … ) →
- Embedding →
- VectorStore 저장 →
- 프롬프트 구성(외부 텍스트 데이터를 함께 이용해 프롬프터 구성) →
- LLM으로부터 답변
문서 또는 데이터 가공
1. 나누는 이유?
- 언어 모델 및 임베딩 모델 토큰크기
- 기대하는 답변의 성격 또는 형식에 따라 나누는 기준 저알수도
- 문서나 데이터의 현재 형식: 구조화된문서/ 구조가 일관성이 없는 문서
2. 임베딩 모델
-
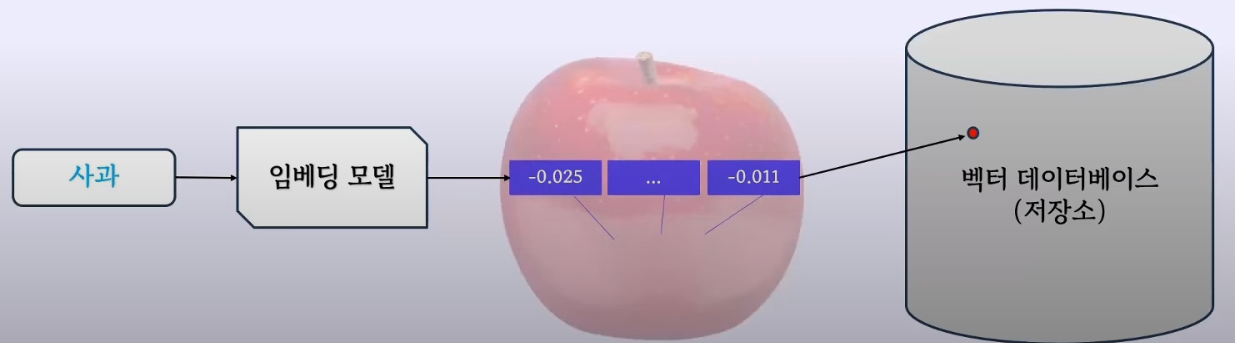
임베딩(Embedding)? 글자, 단어, 문장을 분류하는것
- 모든 과일에는 “과일”스티커, 모든 장난감에는 “장난감”스티커
- 임베딩은 전용 AI모델을 이용해 스티커 대신 숫자를 붙이는것
- 숫자들이 서로 가까울수록 서로의 거리가 가까워서 자연스럽게 분류
-
벡터 데이터베이스(Vector Database)는 과일상자, 장난감사자
-
임베딩 모델?
-
AI가 사람의 언어를 이해하기 위한 방법으로 숫자로 변환을 해주는 역할을 하는 AI 모델

- 임베딩 모델의 성능은 RAG 챗봇을 만들 떄 매우중요
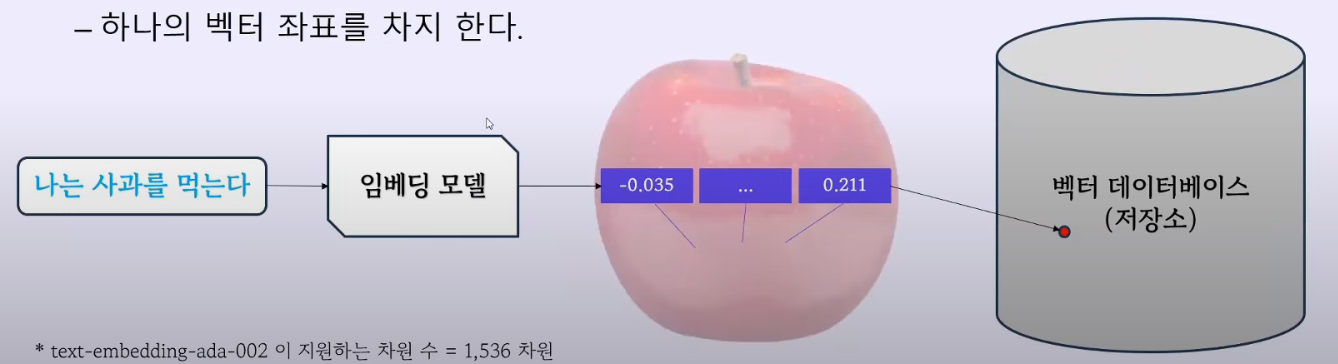
-임베딩 모델은 지정된 차원수를 가지고 있다
- 오픈 AI Ada 모델(모델명:text-embedding-ada-002)DMS 1536차원 지원
-
다양한 임베딩 모델
- OpenAI의 모델들 : text-embeding-ada-002/
text-search-davinci--001/
text-search-curie--001 - 구글: Bert / Sbert
- OpenAI의 모델들 : text-embeding-ada-002/
-
3. 벡터 데이터베이스
- 벡터 데이터베이스(Vector Database)는 과일상자, 장난감사자
- 장난감을 주제, 크기, 색깔로 나눠 상자에 넣듯이
- 임베딩 모델을 이용해 붙은 숫자를 이용해, ‘벡터’라는 조각으로 나누어 저장
4. 사용자 검색
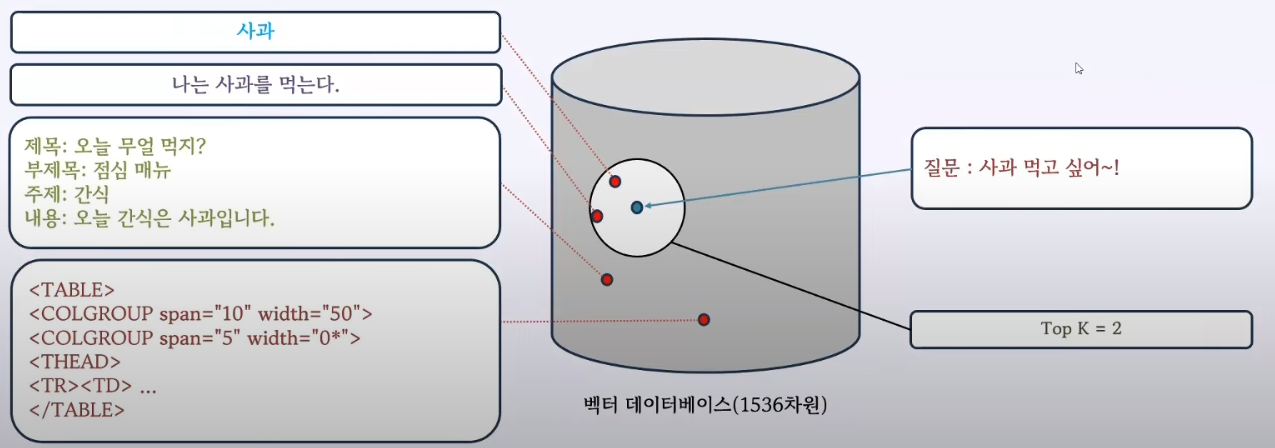
- k개를 순서대로 나열하고 가장 유사도가 높은 것부터 가져옴
5. 프롬프트와 답변 생성
- 프롬프팅 엔지어링
- LLM 모델
