
파이썬 변수 & 기본 연산
a = 3 # 3을 a에 넣는다
b = a # a를 b에 넣는다
a = a + 1 # a+1을 다시 a에 넣는다
num1 = a*b # a*b의 값을 num1이라는 변수에 넣는다
num2 = 99 # 99의 값을 num2이라는 변수에 넣는다파이썬 자료형 (숫자, 문자형)
name = 'bob' # 변수에는 문자열이 들어갈 수도 있고,
num = 12 # 숫자가 들어갈 수도 있고,
is_number = True # True 또는 False -> "Boolean"형이 들어갈 수도 있다.파이썬 자료형 (리스트형)
a=['사과','배','감']
print(a[0]) #사과
파이썬 자료형 (Dictionary형)
a= {}
a= {'name':'영수','age':24}
파이썬 함수
def f(x):
return 2*x+3
y = f(2)
y의 값은? 7
def hey():
print("헤이")
#파이썬에서 함수 생성시, 들여쓰기는 중요!
hey() #헤이
def sum(a,b,c):
return a+b+c
result = sum(1,2,3)
print(result) #6파이썬 조건문
age = 25
if age > 20:
print("성인입니다")
else:
print("청소년입니다")파이썬 반복문
python
fruits = ['사과','배','감','귤']
for fruit in fruits:
print(fruit)fruits = ['사과','배','감','귤']
for fruit in fruits:
print(fruit)
# 사과, 배, 감, 귤 하나씩 꺼내어 찍힙니다.ages =[5,10,13,23,25,9]
for a in ages:
if a>20:
print("성인입니다")
else:
print("청소년입니다")파이썬 가상환경 설치
python3 -m venv 가상환경 이름
웹페이지 크롤링
맥에서
검사 : 요소 점검
copy selector : 선택자 경로
영화 이름 가져오기
import requests #웹에 접속
from bs4 import BeautifulSoup #데이터 솎아냄
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://movie.naver.com/movie/sdb/rank/rmovie.naver?sel=pnt&date=20210829',headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
trs = soup.select('#old_content > table > tbody > tr')
for tr in trs:
a = tr.select_one('td.title > div > a')
if a is not None:
print(a.text)영화 순위 이름 평점 가져오기
import requests #웹에 접속
from bs4 import BeautifulSoup #데이터 솎아냄
headers = {'User-Agent' : 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get('https://movie.naver.com/movie/sdb/rank/rmovie.naver?sel=pnt&date=20210829',headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
#old_content > table > tbody > tr:nth-child(2) > td.point
trs = soup.select('#old_content > table > tbody > tr')
for tr in trs:
a = tr.select_one('td.title > div > a')
if a is not None:
title = a.text
rank = tr.select_one('td:nth-child(1) > img')['alt']
star = tr.select_one('td.point').text
print(rank,title,star)nosql : not only sql
mongodb 연결 오류
from pymongo import MongoClient
client = MongoClient('mongodb+srv://sparta:<test>@cluster0.eu4e0el.mongodb.net/?retryWrites=true&w=majority')
db = client.dbsparta
doc = {
'name':'영수',
'age':24
}
db.users.insert_one(doc)개인의 보안 환경에 따라 나오는 오류,
오류 해결방안 :
- certifi 패키지 설치
pip install certifi2.코드 수정
에서 <>는 빼고 실행!
from pymongo import MongoClient
import certifi
ca = certifi.where()
client = MongoClient("db 주소", tlsCAFile=ca)
db = client.dbsparta
doc = {
'name':'bob',
'age':27
}
db.users.insert_one(doc)pymongo 코드 요약
# 저장 - 예시
doc = {'name':'bobby','age':21}
db.users.insert_one(doc)
# 한 개 찾기 - 예시
user = db.users.find_one({'name':'bobby'})
# 여러개 찾기 - 예시 ( _id 값은 제외하고 출력)
all_users = list(db.users.find({},{'_id':False}))
# 바꾸기 - 예시
db.users.update_one({'name':'bobby'},{'$set':{'age':19}})
# 지우기 - 예시
db.users.delete_one({'name':'bobby'})영화제목 '가버나움' 평점 가져오기
from pymongo import MongoClient
import certifi
ca = certifi.where()
client = MongoClient(
"mongodb+srv://sparta:test@cluster0.eu4e0el.mongodb.net/?retryWrites=true&w=majority", tlsCAFile=ca)
db = client.dbsparta›
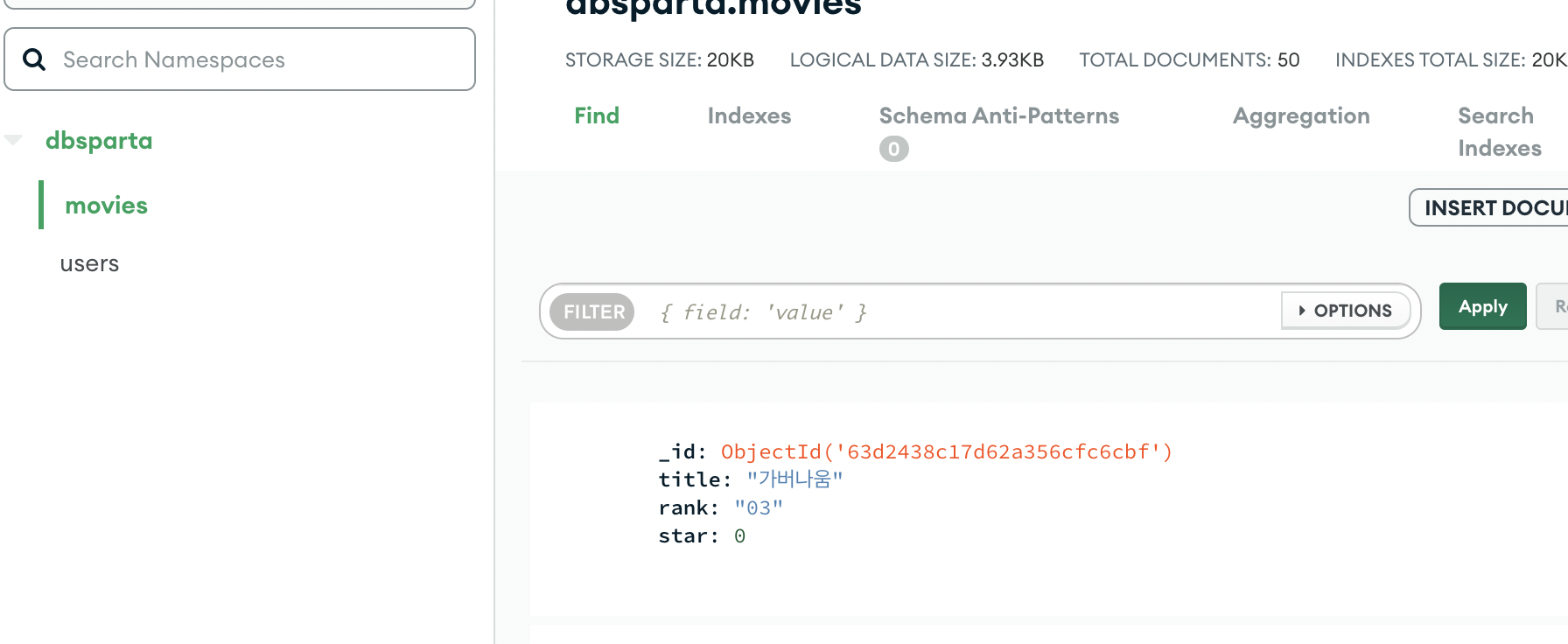
movie = db.movies.find_one({'title':'가버나움'})
print(movie['star']) 
'가버나움' 평점과 같은 평점의 영화 제목들을 가져오기
from pymongo import MongoClient
import certifi
ca = certifi.where()
client = MongoClient(
"mongodb+srv://sparta:test@cluster0.eu4e0el.mongodb.net/?retryWrites=true&w=majority", tlsCAFile=ca)
db = client.dbsparta
movie = db.movies.find_one({'title':'가버나움'})
target_star = movie['star']
movies = list(db.movies.find({'star':target_star},{'_id':False}))
for a in movies:
print(a['title']) 
'가버나움' 영화 평점 0 만들기
db.movies.update_one({'title':'가버나움'},{'$set':{'star':0}})
3주차 숙제(지니뮤직 사이트에서 음원순위,음원 이름, 가수 이름 가져오기)
0) 출력 할 때는 print(rank, title, artist) !
1) 앞에서 두 글자만 끊기! text[0:2] 사용
2) 순위와 곡제목이 깔끔하게 나오지 않을 거예요. 옆에 여백이 있다던가, 다른 글씨도 나온다던가.. 파이썬 내장 함수인 strip() 사용
strip() : 공백 자르기
1. tr정보 copy selector 해서 가져오기
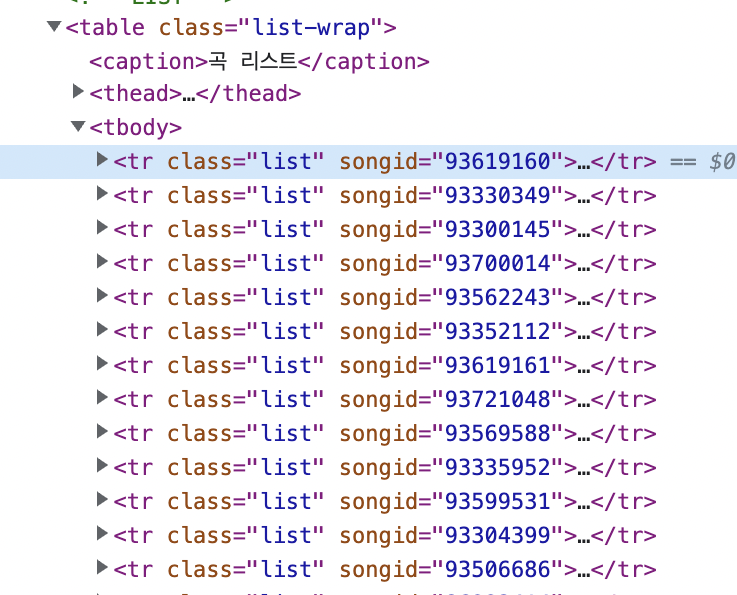
2. rank 정보 copy selector 해서 가져오기
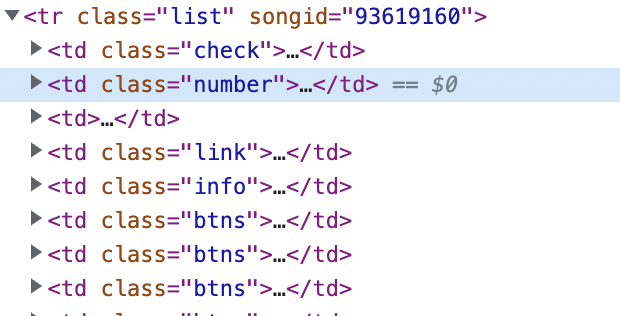
3. title 정보 copy selector 해서 가져오기
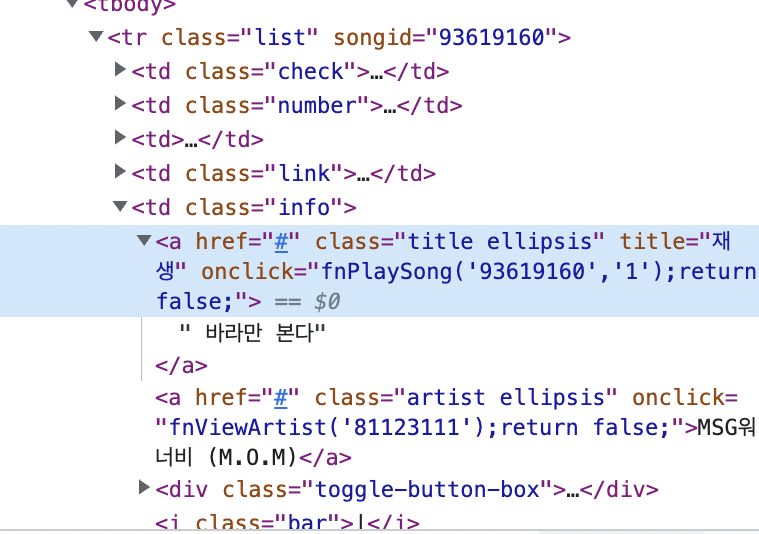
4. artist 정보 copy selector 해서 가져오기

from bs4 import BeautifulSoup # 데이터 솎아냄
import requests # 웹에 접속
from pymongo import MongoClient
import certifi
ca = certifi.where()
client = MongoClient(
"mongodb+srv://sparta:test@cluster0.eu4e0el.mongodb.net/?retryWrites=true&w=majority", tlsCAFile=ca)
db = client.dbsparta
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36'}
data = requests.get(
'https://www.genie.co.kr/chart/top200?ditc=M&rtm=N&ymd=20210701', headers=headers)
soup = BeautifulSoup(data.text, 'html.parser')
trs = soup.select(
'#body-content > div.newest-list > div > table > tbody > tr')
for tr in trs:
title = tr.select_one('td.info > a.title.ellipsis').text.strip()
rank = tr.select_one('td.number').text[0:2].strip()
artist = tr.select_one('td.info > a.artist.ellipsis').text
print(rank, title, artist)웹페이지에 있는 정보를 사용해서 코딩을 해보니 재미있었다!

개발자