내 AI가 실수를 통해 성장하는 법: Reflexion 프레임워크 뽀개기
AI가 코드를 짜고, 복잡한 문제를 풀고, 심지어 게임까지 하는 시대입니다. 하지만 이 AI 에이전트들이 막다른 길에 부딪혔을 때, 어떻게 더 똑똑해질 수 있을까요? 단순히 시도를 수천 번 반복하는 것 말고, 실수로부터 배우는 방법은 없을까요? 마치 우리 개발자들이 버그를 잡고, 코드 리뷰를 받으며 성장하는 것처럼 말이죠.
오늘 소개할 Reflexion 프레임워크가 바로 그 질문에 대한 흥미로운 해답을 제시합니다. 이 기술은 LLM 에이전트가 자신의 실패를 스스로 '성찰'하고, 그 교훈을 바탕으로 더 나은 해결책을 찾아가게 만듭니다. 이 글을 끝까지 읽으시면, 왜 Reflexion이 단순히 성능 좋은 AI를 넘어, 스스로 발전하는 '자율 에이전트' 시대를 여는 중요한 열쇠인지 이해하게 되실 겁니다.
가중치 업데이트 없는 학습? '말로 하는 강화학습'
기존의 AI 학습, 특히 강화학습이나 파인튜닝은 모델의 '가중치(weights)'를 직접 수정하는 방식이었습니다. 수많은 데이터를 쏟아부어 모델의 뇌 구조 자체를 바꾸는, 시간과 비용이 많이 드는 작업이죠. 마치 운동선수가 근육을 키우기 위해 수없이 무거운 역기를 드는 것과 같습니다.
하지만 Reflexion은 다릅니다. 가중치는 그대로 둔 채, 언어적 피드백(Verbal Reinforcement)을 통해 행동을 교정합니다. 이게 무슨 의미일까요?
개발자 A: "이 기능 구현이 자꾸 실패하네. 그냥 '실패'라고만 뜨니 답답하다." (기존 방식: 단순한 보상 신호)
시니어 개발자 B: "A님, 지금 코드 보니까 리스트의 순서를 고려 안 했네요. 스택 자료구조를 써서 순서대로 처리하는 로직을 넣어보세요." (Reflexion 방식: 구체적인 언어적 피드백)
Reflexion의 핵심은 바로 이 '시니어 개발자 B'의 역할을 AI가 스스로 해내는 것입니다. 실패했을 때 단순히 reward: 0이라는 신호만 받는 게 아니라, "내가 작성한 코드는 ~를 고려하지 않아서 실패했구나. 다음번엔 ~방식을 써야겠다." 와 같은 구체적인 '성찰 노트'를 스스로 작성합니다. 그리고 다음 시도에 이 노트를 참고하여 더 나은 코드를 짜는 거죠. 이것이 바로 컨텍스트 내 학습(In-context Learning)을 활용한 '언어적 강화'입니다.
| 구분 | 파인튜닝 (기존 방식) | Reflexion (새로운 접근) |
|---|---|---|
| 개선 방법 | 모델 가중치 직접 업데이트 | 성찰 노트를 컨텍스트에 추가 |
| 피드백 | 숫자 (e.g., 성공=1, 실패=0) | 자연어 (e.g., "스택을 안 써서 실패했다") |
| 비유 | 무한 반복으로 근육 키우기 | 선배의 코드 리뷰로 깨달음 얻기 |
| 결과 | 느리고 비쌈, 왜 잘 되는지 알기 어려움 | 빠르고 저렴, 실패 원인 명확 |
Reflexion, 어떻게 작동할까? '주니어 개발자의 성장기'
Reflexion의 작동 방식은 마치 코딩 과제를 받은 주니어 개발자의 성장 과정과 놀랍도록 닮아있습니다. 처음에는 헤매지만, 실수를 통해 배우고 결국에는 문제를 해결해내는 그 과정을 단계별로 따라가 보며 Reflexion의 핵심 메커니즘을 파헤쳐 보겠습니다.
이 성장기에는 세 명의 주요 조력자(모델)가 등장합니다.
- Actor (행동대장): 일단 코드를 짜고 보는 열정 넘치는 주니어 개발자.
- Evaluator (평가자): "성공" 또는 "실패"만 알려주는 냉정한 자동 채점 시스템.
- Self-Reflection (성찰 모델): 실패의 원인을 스스로 분석하고 교훈을 기록하는, 개발자 내면의 '시니어 자아'.
이들의 협업은 다음과 같은 5단계 사이클로 이루어집니다.

Reflexion의 학습 사이클: '시도, 평가, 성찰, 그리고 재시도'. LLM 에이전트는 단순히 시도를 반복하는 것이 아니라, 자신의 실패를 언어적으로 분석하고(d) 그로부터 얻은 교훈을 다음 행동(e)에 반영합니다. 이 과정은 마치 인간이 실수를 통해 배우는 방식과 유사하며, 에이전트가 복잡한 문제를 빠르게 해결하도록 돕습니다.
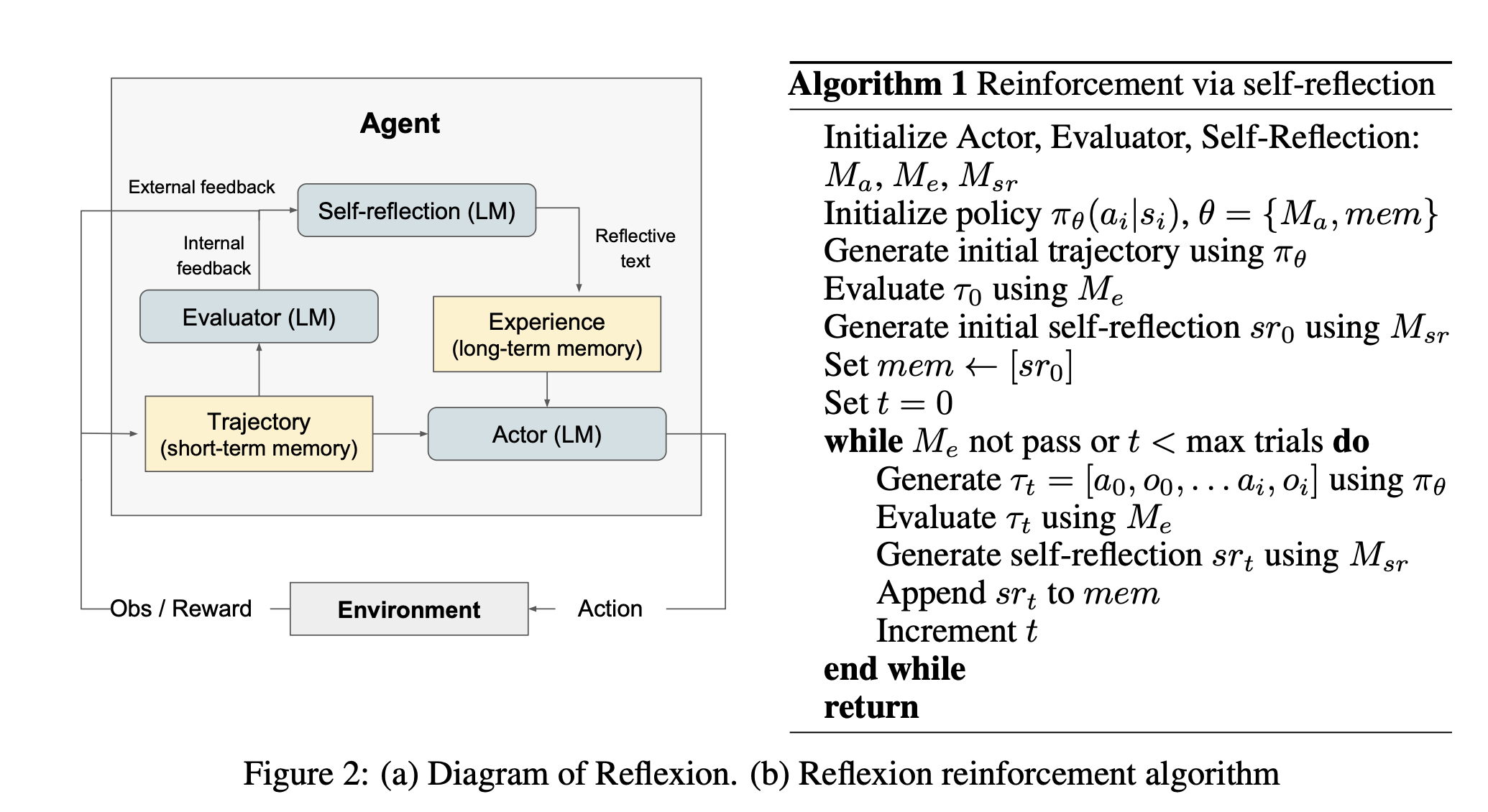
1단계: 시도 (Trial by Actor)
우리의 주니어 개발자(Actor)는 먼저 문제(e.g., "사용자 목록을 정렬하는 함수를 만드세요")를 보고 해결책을 구상하여 코드를 작성합니다. 첫 시도이므로, 아직 특별한 노하우나 경험은 없습니다. 그저 자신의 현재 지식으로 최선의 코드를 제출합니다.
2단계: 평가 (Evaluation by Evaluator)
제출된 코드는 자동 채점 시스템(Evaluator)으로 넘어갑니다. 이 시스템은 유닛 테스트를 돌려보거나 정답과 결과를 비교하여 "성공(Pass)" 또는 "실패(Fail)"라는 명확한 결과만 알려줍니다. 왜 틀렸는지는 알려주지 않는, 다소 불친절한 평가자입니다.
3단계: 성찰 (Self-Reflection)
"실패" 결과를 받은 주니어 개발자는 좌절하지 않습니다. 바로 Reflexion의 심장인 '성찰' 단계에 들어갑니다. 개발자는 자신의 실패한 코드, 실행 과정, 그리고 '실패'라는 결과를 모두 테이블 위에 올려놓고 복기합니다.
"아, 사용자 객체에 나이가 없는 경우(null)를 고려하지 않아서
TypeError가 났구나. 다음번엔 코드를 실행하기 전에 반드시 null 체크 로직을 먼저 추가해야겠다."
이렇게 실패의 원인을 분석하고, 다음 시도를 위한 구체적인 개선 방안을 담은 '성찰 노트(Reflection Note)'를 스스로 작성합니다. 이 과정이 바로 Self-Reflection 모델이 하는 일입니다. AI가 스스로 자신의 코드 리뷰어가 되어 구체적인 해결책을 제시하는 것입니다.
4단계: 기록 (Recording to Memory)
이 소중한 깨달음이 담긴 '성찰 노트'는 그냥 흘려보내지 않습니다. 개발자는 이 노트를 자신의 경험적 기억 버퍼(Episodic Memory Buffer), 즉 '오답 노트'나 '개발 회고록'에 차곡차곡 기록해둡니다. 이 기억 버퍼에는 "null 체크 실패 경험", "배열 인덱스 초과 문제 해결법" 등 성공적인 해결을 위한 핵심 전략들이 저장됩니다.
5단계: 재시도 (Retry with Memory)
이제 두 번째 시도에 나섭니다. 주니어 개발자(Actor)는 다시 문제를 마주하지만, 이번엔 맨몸이 아닙니다. 코드를 짜기 전, 먼저 자신의 '오답 노트(기억 버퍼)'를 펼쳐봅니다.
"이 문제 유형은 이전에 null 체크 때문에 실패했었지. 이번엔 꼭 먼저 처리해야 해."
기억 버퍼에 저장된 '성찰 노트'를 먼저 참고하여, 같은 실수를 반복하지 않고 훨씬 더 정교하고 효율적인 코드를 작성합니다. 이 '시도 → 평가 → 성찰 → 기록 → 재시도' 사이클이 반복되면서, 주니어 개발자는 점차 시니어 개발자처럼 노련하게 문제를 해결하게 됩니다. Reflexion 에이전트는 바로 이 과정을 통해 스스로 성장합니다.
그래서, 얼마나 똑똑해졌을까? 압도적인 성능 향상
이론은 그럴듯한데, 실제 성능은 어떨까요? 결과는 놀라웠습니다.
- 순차적 의사결정 (AlfWorld): 가상 환경에서 "사과를 찾아 씻어서 식탁 위에 두세요" 같은 복잡한 임무를 수행하는 테스트입니다. 기존 에이전트는 엉뚱한 곳을 헤매거나 같은 실수를 반복하며 성공률이 75%에서 정체됐습니다. 하지만 Reflexion 에이전트는 단 몇 번의 성찰만으로 거의 모든 임무(97%)를 완수했습니다.
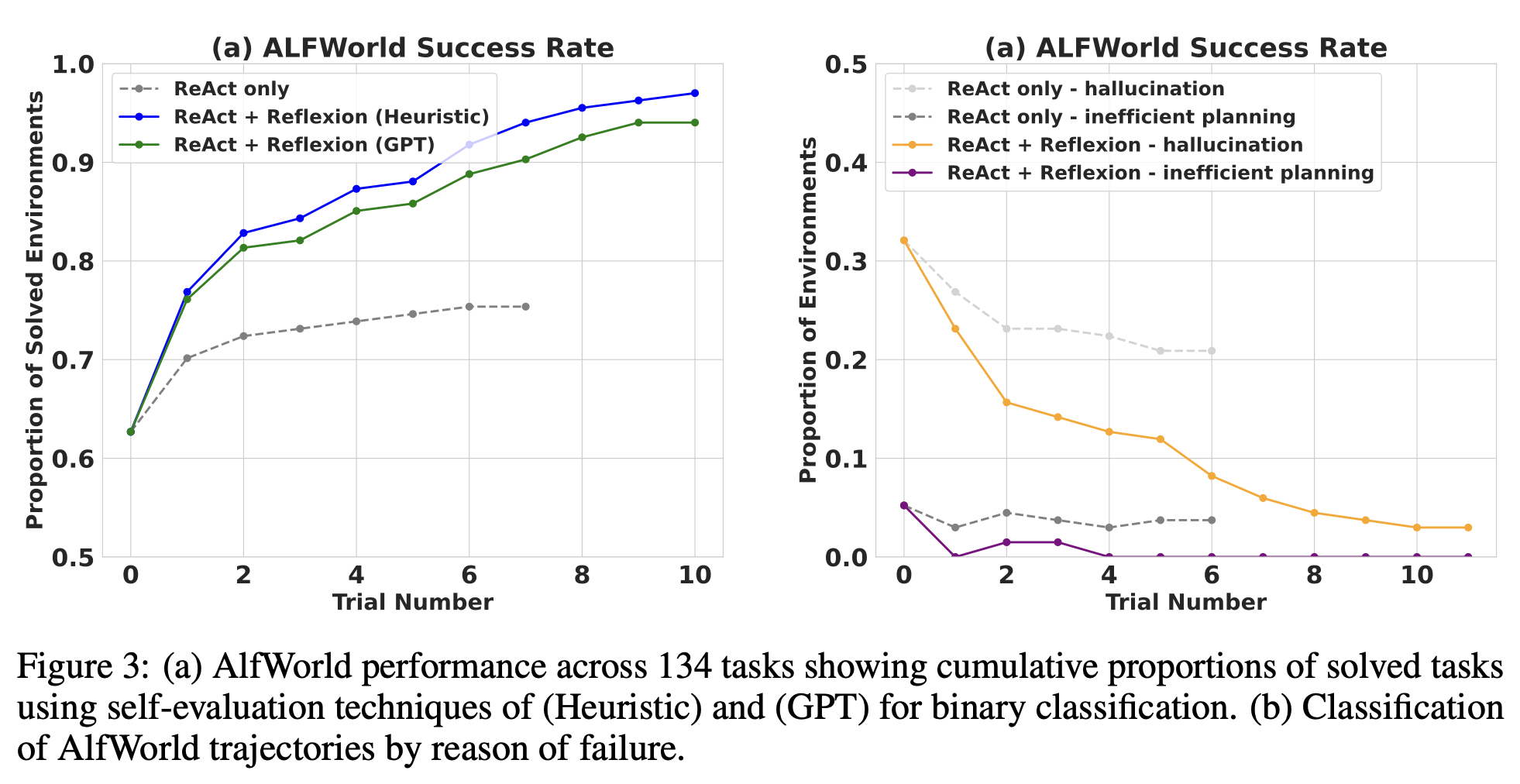
ReAct 단독 에이전트(회색 선)는 약 6~7번의 시도 후 성능 개선이 정체되지만, Reflexion을 적용한 에이전트(파란색/초록색 선)는 시도를 거듭할수록 꾸준히 성능이 향상되어 최종적으로 97%의 성공률을 달성합니다. 이는 '자기 성찰'을 통해 얻은 경험이 효과적으로 누적되어 학습을 가속화한다는 것을 명확히 보여줍니다.
- 프로그래밍 (HumanEval): Python 코딩 문제 풀이에서, Reflexion은 스스로 유닛 테스트를 만들어 코드를 검증하고, 에러 메시지를 분석해 코드를 디버깅했습니다. 그 결과, 당시 최고 성능이었던 GPT-4의 정확도(80.1%)를 뛰어넘는 91.0%라는 새로운 SOTA(최고 기록)를 달성했습니다. 어려운 Leetcode 문제에서는 성공률을 2배나 높였죠.
이는 Reflexion이 단순히 문제를 푸는 것을 넘어, '더 잘 푸는 법'을 스스로 터득하고 있음을 보여줍니다.
마치며: 스스로 성장하는 AI를 향한 첫걸음
Reflexion은 AI 에이전트 연구에 중요한 시사점을 던집니다.
"성공은 좋은 스승이지만, 실패는 더 위대한 스승이다."
이 프레임워크는 AI에게 '실패'라는 데이터를 그냥 버리는 것이 아니라, 가장 값진 학습 자료로 활용하는 법을 가르쳐주었습니다. 이는 단순히 더 높은 점수를 내는 것을 넘어, AI가 더 투명하고, 예측 가능하며, 효율적으로 발전할 수 있는 길을 열어줍니다.
개발자로서 우리는 매일 버그와 싸우고, 동료의 피드백을 통해 성장합니다. Reflexion은 바로 그 인간적인 '성찰의 과정'을 AI에게 부여한 것입니다. 앞으로 우리가 마주할 AI 에이전트들은 아마도 우리처럼 자신의 실수 노트를 들여다보며, 어제보다 더 나은 코드를 짜기 위해 고민하고 있을지 모릅니다. 스스로 실수하고 성장하는 AI, 정말 흥미진진한 미래가 아닐까요?
