[논문] Data Diversity Matters for Robust Instruction Tuning

AI 모델, 똑똑하게 학습시키는 '데이터 다양성'의 비밀
최신 LLM(대규모 언어 모델)을 사용하다 보면 가끔 "이걸 왜 이렇게 답하지?" 싶은 순간이 있습니다. 똑똑한 줄 알았는데, 질문을 조금만 비틀면 엉뚱한 답변을 내놓는 '취약성' 문제 때문이죠. 많은 개발자가 더 좋은 모델을 만들기 위해 '고품질' 데이터 확보에 열을 올립니다. 하지만 이 논문은 우리에게 다른 관점을 제시합니다. 데이터의 '품질'만큼, 아니 어쩌면 그 이상으로 '다양성'이 중요하다는 사실을요.
이 글에서는 데이터의 품질과 다양성을 모두 잡아, 더 똑똑하고 '강건한' AI를 만드는 비법, QDIT 알고리즘을 소개합니다.
왜 이 논문을 읽어야 할까요?
이 연구는 단순히 똑똑한 AI를 넘어, 어떤 질문에도 흔들리지 않는 '강건한(Robust)' AI를 만드는 핵심 열쇠를 쥐고 있습니다. 모델의 신뢰성에 대해 고민하는 개발자라면 반드시 주목해야 할 내용입니다.
문제점: 똑똑한 AI의 '편식' 문제
고품질 데이터로만 학습한 AI를 '최고급 참고서만 푼 모범생'에 비유할 수 있습니다. 이 모범생은 참고서에 나온 문제는 기가 막히게 잘 풀지만, 조금만 응용되거나 처음 보는 유형의 문제가 나오면 당황해서 손도 대지 못합니다.
마찬가지로, '품질' 점수가 높은 데이터(쉽고 정형화된 질문)만 편식한 AI는 평균적인 성능은 높을지 몰라도, 예상치 못한 까다로운 질문에는 매우 취약한 모습을 보입니다. 이는 모델의 강건성을 해치는 치명적인 원인이 됩니다.
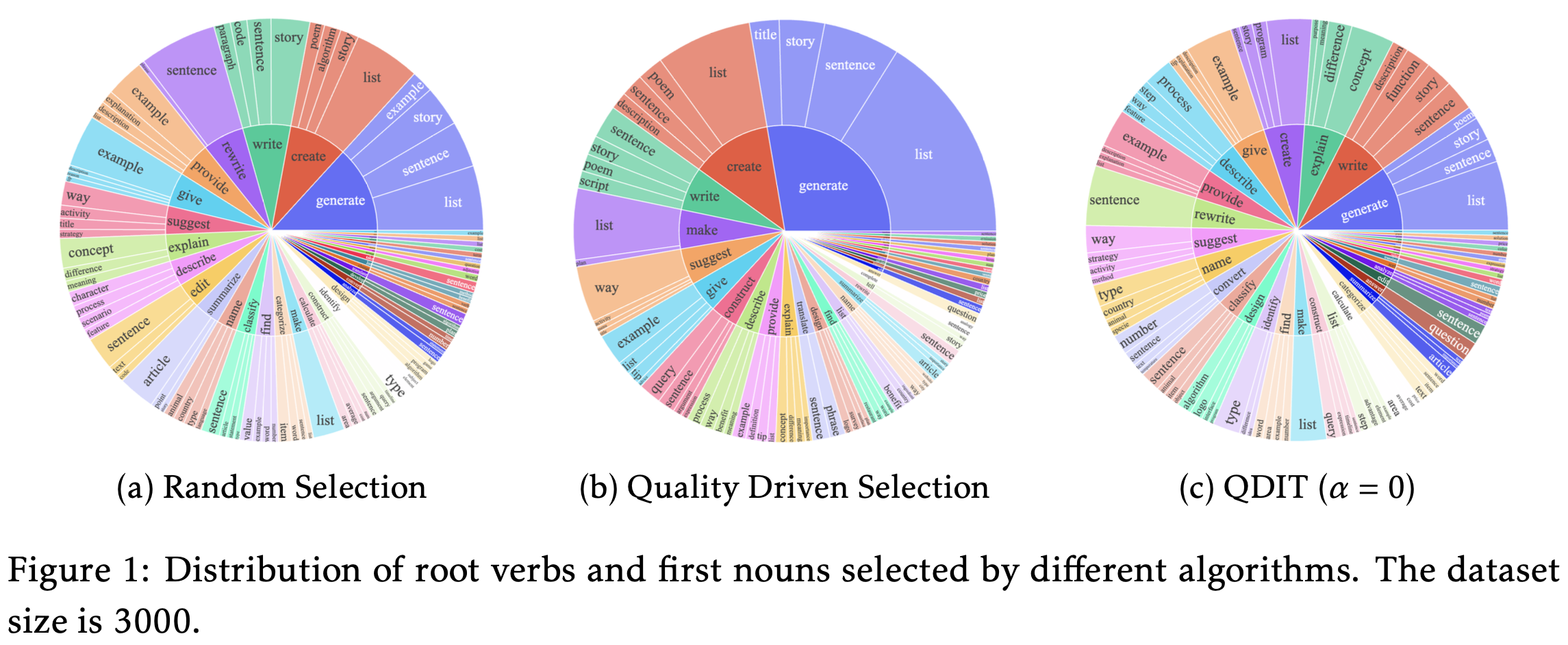
데이터 선택 방식에 따른 언어 분포. (b) 품질만 고려하면 데이터가 특정 주제에 집중(편향)되지만, (c) QDIT를 사용하면 훨씬 넓고 고르게 분포하여 언어적 다양성이 확보됨을 보여줍니다.
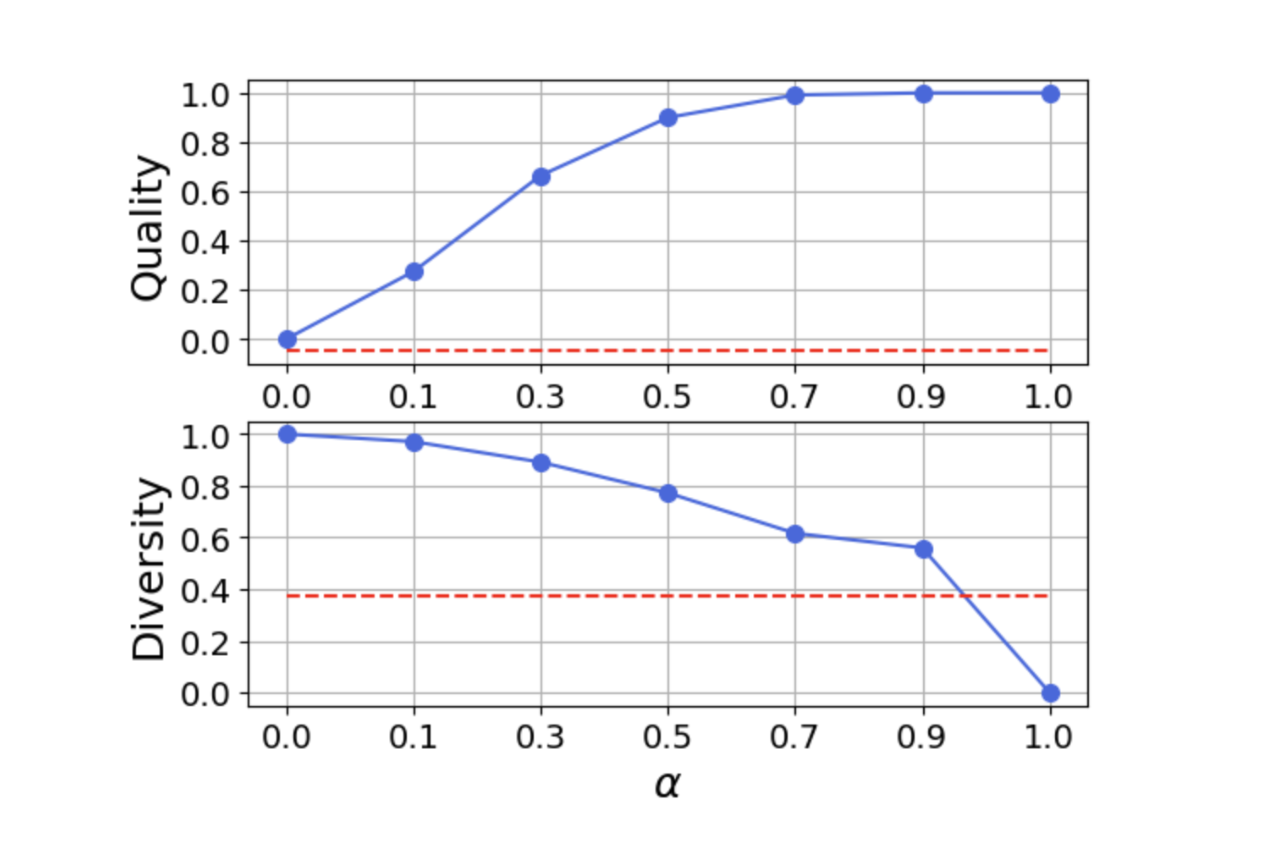
품질-다양성 트레이드오프. α(알파) 값을 1에 가깝게 설정해 품질을 중시할수록, 데이터셋의 다양성 점수는 하락하는 상충 관계를 명확히 보여줍니다
해결책: AI를 위한 '균형 잡힌 식단', QDIT 알고리즘
QDIT는 대규모의 Instruction (명령어) 데이터 풀에서 소수의, 하지만 정말 좋은(고품질) 동시에 다양한(다양한 주제/형태) 데이터셋을 자동으로 뽑아내는 것입니다.
왜 이게 중요하냐면, 수많은 Instruction 데이터 중 일부만 사용해도 모델 성능을 크게 높일 수 있다는 연구 결과가 있는데 (Lima 논문 (이전 포스트 참고) 등), 어떤 데이터를 골라야 "정말 좋은" 데이터셋이 되는지 명확하지 않았기 때문입니다.
사람이 일일이 고르기는 너무 힘들고요...
QDIT는 이 데이터 선택 과정을 자동화하고, 우리가 품질과 다양성 사이의 균형을 조절할 수 있게 해줍니다.
자, 그럼 QDIT가 어떻게 작동하는지 단계별로 살펴보죠.
우리가 큰 보석 광산(전체 데이터 풀 V)에서 가장 가치 있는 보석(고품질 데이터)과 모양/색깔이 다채로운 보석(다양한 데이터) K개를 골라 작은 상자(선택된 데이터셋 A)에 담는다고 상상해 보세요.
QDIT는 이 보석을 고르는 방법을 자동화하는 알고리즘입니다.
구현 단계:
- Step 0: 사전 준비 - 모든 보석의 가치와 특성 파악하기
QDIT 알고리즘을 시작하기 전에, 데이터 풀에 있는 모든 Instruction 데이터 포인트에 대해 두 가지 정보가 필요합니다.
품질 점수: 각 Instruction-Response 쌍이 얼마나 잘 만들어졌는지 나타내는 점수입니다.- 이미 잘 훈련된 다른 LLM(예: ChatGPT)에게 각 데이터 포인트를 평가하게 해서 점수를 받거나,
- 인간 선호도 데이터로 훈련된 별도의 '보상 모델(Reward Model)'을 사용해서 점수를 매겼다고 합니다.
-
Instruction 임베딩 (Instruction Embedding): 각 Instruction의 '의미'나 '특성'을 숫자로 표현한 벡터입니다.- 'Sentence-BERT' 같은 도구를 사용해서 Instruction 텍스트를 입력하면 고정된 길이의 숫자 벡터를 얻을 수 있습니다.
이 벡터 공간에서 두 Instruction의 임베딩 벡터가 서로 가까우면 '비슷한 Instruction'이라고 봅니다 (코사인 유사도 사용).
구현 시점
이 두 가지(품질 점수와 임베딩)는 QDIT 알고리즘이 실행되기 전에 미리 계산해 두어야 합니다.
전체 데이터 풀 V의 크기가 크더라도, 이 계산은 병렬 처리 등으로 비교적 빠르게 할 수 있습니다. - 'Sentence-BERT' 같은 도구를 사용해서 Instruction 텍스트를 입력하면 고정된 길이의 숫자 벡터를 얻을 수 있습니다.
-
Step 1: 선택 기준 정하기 - 어떤 보석이 '지금 우리 상자'에 가장 좋을까?
이제 실제로 보석을 하나씩 고를 차례입니다. QDIT는 한번에 하나씩, 총 K개를 고릅니다. 각 단계에서 어떤 보석을 고를지는 '품질-다양성 점수(Quality-Diversity Score)'라는 기준에 따라 결정됩니다.선택하려는 보석 a가 현재 상자 A에 들어갔을 때, 얘가 얼마나 '좋은 보석'인지를 다음 함수 f(a|A, α)로 계산합니다:
f(a|A, α) = (1 − α) * (a를 추가했을 때 다양성 증가량) + α * (a의 품질 점수)α (알파): 0부터 1 사이의 값입니다. 이 값이 중요해요!
- α가 1에 가까우면? 품질 점수 q(a)의 비중이 커집니다. => 품질 위주로 선택
- α가 0에 가까우면? 다양성 증가량의 비중이 커집니다. => 다양성 위주로 선택
- α가 0.5면? 품질과 다양성을 절반씩 봅니다.
(a를 추가했을 때 다양성 증가량): 이건 조금 복잡한 개념입니다. a를 현재 상자 A에 넣었을 때, 전체 광산 V에 있는 아직 선택되지 않은 나머지 모든 보석들이 A에 있는 보석들에 의해 얼마나 더 잘 '대변'되는가를 측정합니다.- 기술적으로는 Facility Location 함수의 증가량 d(A U {a}) - d(A)를 계산합니다. 여기서 d(A)는 Sum over v in V of max over a' in A of sim(a', v)입니다. 즉, a를 추가함으로써 전체 데이터 풀 V의 각 데이터 포인트 v가 현재 선택된 데이터 A 중 가장 비슷한 데이터(max over a' in A of sim(a', v))에 의해 얼마나 잘 커버되는지를 나타내는 다양성 점수입니다. d(a|A)는 a를 추가해서 이 점수가 얼마나 오르는지를 의미합니다.
- 비유: 현재 상자 A에 빨간색 둥근 보석만 있다고 해봅시다. 전체 광산 V에는 파란색 세모 보석도 있고, 초록색 네모 보석도 있어요. 만약 다음에 고를 a가 '파란색 세모 보석'이라면, 얘는 현재 상자에 없는 새로운 특성을 가져오므로 '다양성 증가량'이 클 것입니다. 반면 또 '빨간색 둥근 보석'이라면 다양성 증가량은 작겠죠. 이 다양성 증가량은 a가 전체 V 중 현재 A에 의해 잘 대변되지 않는 영역에 얼마나 속해 있는지를 나타냅니다.
-
Step 2: 반복 선택 - K개의 보석을 다 고를 때까지!
이제 준비된 정보와 선택 기준 함수 f를 가지고 K개의 데이터를 고르는 Greedy 알고리즘을 실행합니다:-
빈 상자 준비: 선택된 데이터셋 A를 빈 상태로 시작합니다. 아직 선택되지 않은 데이터셋 R은 전체 데이터 풀 V입니다.
- A = {}
- R = V
-
K개 선택 반복: 상자에 K개의 보석이 다 찰 때까지 다음을 반복합니다.
- 가장 좋은 보석 찾기: 아직 상자에 넣지 않은
R에 있는 모든 보석들a에 대해, 만약 이 보석a를 현재 상자A에 넣는다면 '품질-다양성 점수f(a|A, α)'가 얼마나 될지 모두 계산해 봅니다. 이 점수가 가장 높은 보석a*를 찾습니다.a* = argmax_{a in R} f(a|A, α)
- 상자에 넣기: 찾은 보석 a*를 상자 A에 넣습니다.
- A = A U {a*}
- 남은 보석에서 제외: a*는 이제 상자에 들어갔으니, 아직 선택되지 않은 보석 R에서 제외합니다.
- R = R \ {a*}
- 갯수 세기: 상자에 담긴 보석 수를 1 늘립니다.
- 가장 좋은 보석 찾기: 아직 상자에 넣지 않은
-
완료: 상자에 K개의 보석이 다 찼으면 알고리즘을 종료합니다. 상자 A에 담긴 K개의 데이터가 QDIT가 선택한 최종 데이터셋입니다.
구현 시점
이 반복 단계는 핵심 계산(f(a|A, α) 계산)을 매번 수행해야 해서 Step 0보다 시간이 오래 걸릴 수 있습니다. 특히 다양성 증가량 계산은 현재 선택된 데이터 A와 전체 데이터 풀 V를 모두 고려해야 하기 때문입니다. 논문에서는 이를 빠르게 하기 위해 Lazy Greedy 같은 최적화 기법을 사용했다고 언급합니다.
-
요약하자면:
- 준비: 전체 데이터에 대해 품질 점수와 임베딩을 미리 계산해 둡니다.
- 선택: 빈 손으로 시작해서 K개를 고를 때까지 반복합니다.
- 반복 내용: 매 단계마다 아직 안 고른 데이터들 중, 현재까지 고른 데이터들과 함께 봤을 때 품질과 다양성을 가장 크게 높여줄 데이터를 하나 골라서 추가합니다. 품질과 다양성 중 무엇을 더 중요하게 볼지는 α 값으로 조절합니다.
결과: '균형 잡힌 식단'의 놀라운 효과
QDIT라는 영양사가 짜준 균형 잡힌 식단으로 학습한 AI는 어떤 변화를 보였을까요? 결과는 놀라웠습니다.
핵심은 '최악의 경우(Worst-Case)' 성능 향상입니다. 품질만 고려했을 때보다 모델이 가장 어려워하는 까다로운 질문에 대한 답변 능력이 눈에 띄게 좋아졌습니다.
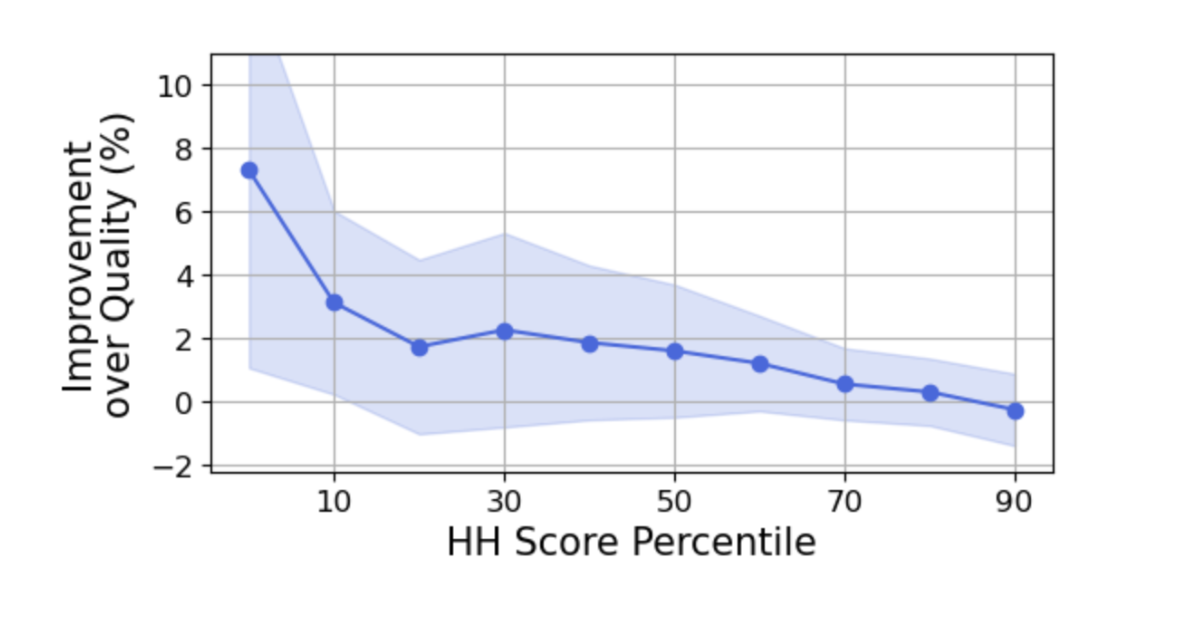
QDIT(Quality-Diversity Instruction Tuning) 방법이 품질 기반 데이터 선택 방법 대비 HH 점수 백분위별 성능 개선율(%)을 보여줍니다.
- X축 (HH Score Percentile): 모델이 얻은 HH 점수의 백분위를 나타냅니다. 10 백분위는 모델의 가장 낮은(가장 나쁜) 성능을, 90 백분위는 가장 높은(가장 좋은) 성능을 의미합니다.
- Y축 (Improvement over Quality (%)): QDIT가 품질 기반 선택보다 성능이 얼마나 향상되었는지를 백분율로 나타냅니다. 값이 양수이면 QDIT가 더 좋고, 음수이면 품질 기반 선택이 더 좋습니다.
- 파란색 선 (Line): 다양한 HH 점수 백분위에서 QDIT의 평균 성능 개선율을 보여줍니다.
옅은 파란색 영역 (Shaded Area): 평균 개선율의 표준 편차를 나타냅니다. 이는 여러 데이터셋에서 결과의 변동성을 보여줍니다.
그래프에서 핵심적인 내용은 다음과 같습니다.
- QDIT는 HH 점수가 낮은 백분위(예: 10 백분위)에서 품질 기반 선택에 비해 성능 개선율이 가장 높습니다(약 7% 개선). 이는 QDIT가 모델의 가장 나쁜 성능, 즉 worst-case 시나리오에서 강점을 보인다는 것을 의미합니다.
- HH 점수 백분위가 높아질수록 성능 개선율은 점차 감소합니다. 상위 백분위(예: 90 백분위)에서는 개선율이 0%에 가깝거나 약간 음수입니다. 이는 QDIT가 모델의 가장 좋은 성능, 즉 best-case 시나리오에는 큰 영향을 미치지 않거나 미미하게 저하시킬 수 있음을 시사합니다.
이러한 결과는 논문의 핵심 주장 중 하나인 '데이터 다양성을 높이면 Instruction Following 성능, 특히 모델의 robustness(강건성)가 향상된다'는 것을 뒷받침합니다. QDIT는 데이터 다양성과 품질 사이의 균형을 조절하여, 특히 모델이 어려워하는 instruction에 대한 응답 능력을 개선하는 데 효과적임을 보여줍니다.
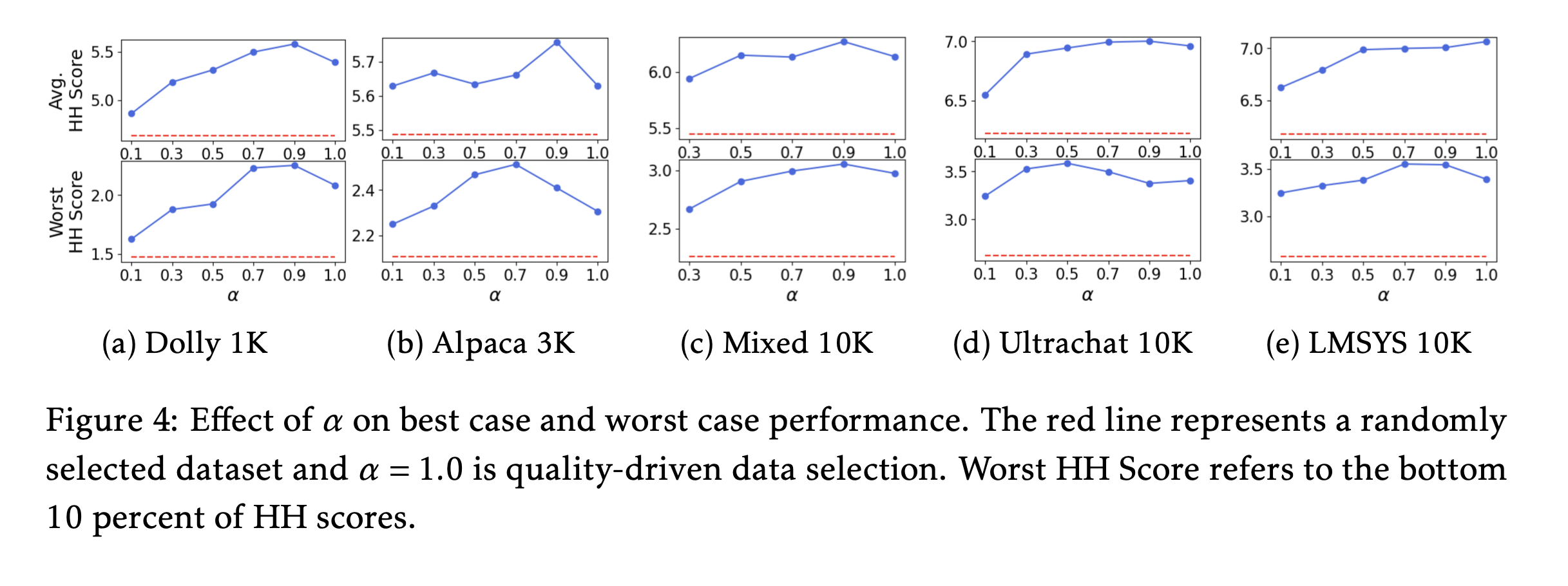
α 값에 따른 모델 성능. α가 0.5~0.9 사이, 즉 품질과 다양성의 균형을 맞췄을 때 최악 성능(점선)과 평균 성능(실선)이 가장 높게 나타납니다. 어느 한쪽에 치우치는 것은 정답이 아님을 보여줍니다.
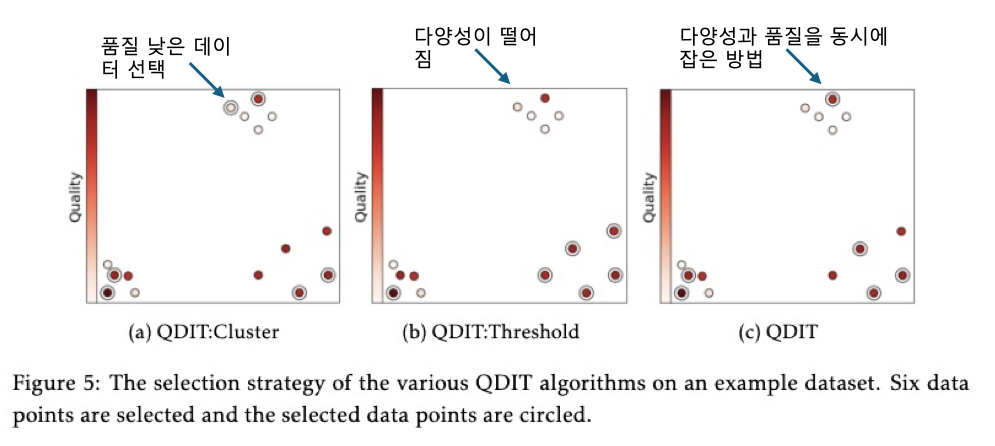
Figure 5는 QDIT 알고리즘 및 그 변형들이 데이터 포인트들을 어떻게 선택하는지 시각적으로 보여줍니다. 각 패널은 6개의 데이터 포인트를 선택했을 때의 결과이며, 선택된 데이터 포인트는 회색 원으로 표시되어 있습니다. 데이터 포인트의 색깔은 품질(Quality)을 나타내며, 빨간색이 진할수록 품질이 높습니다.
이러한 QDIT의 효과는 다른 모델, 다른 데이터 크기에서도 일관되게 나타났으며, 다양한 평가 방식(GPT-4, 인간 평가 등)에서도 그 우수성이 검증되었습니다.
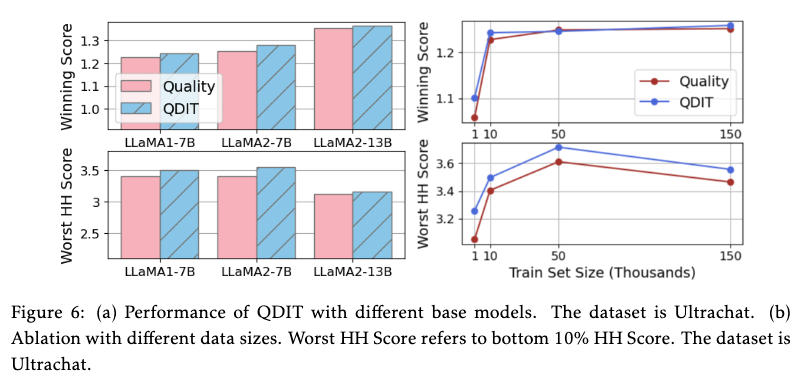
QDIT의 일반성과 확장성. (a) LLaMA-2 13B 같은 다른 모델에서도, (b) 데이터 크기가 작거나 클 때도 QDIT는 꾸준히 효과를 발휘합니다. 특히 데이터가 적을 때 효과가 더 큽니다.
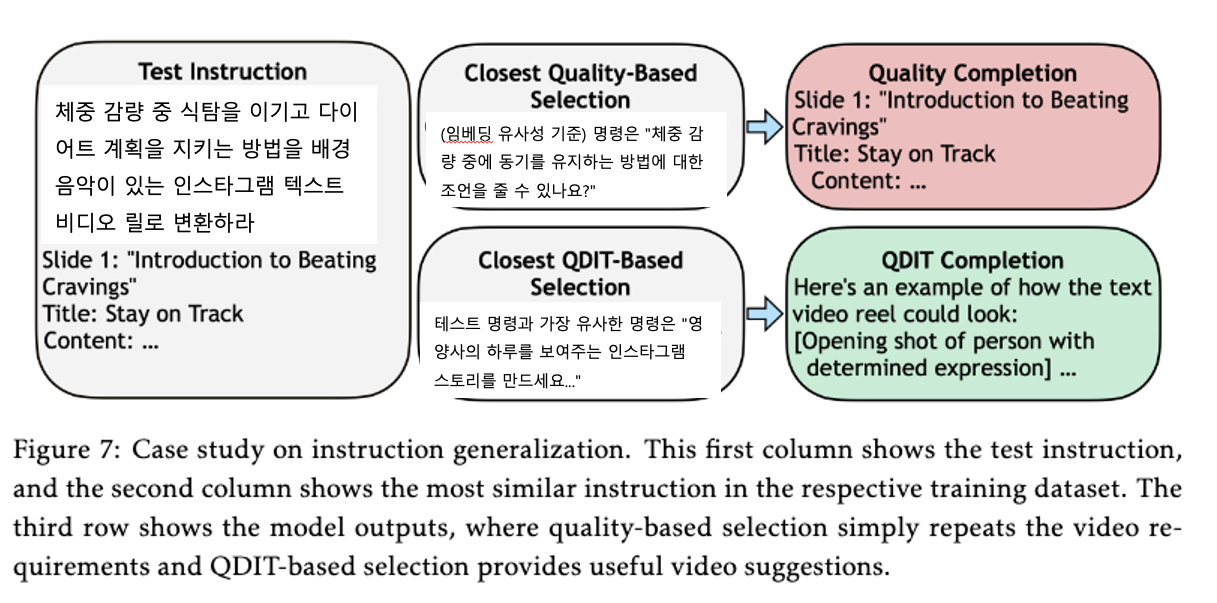
이 사례 연구는 데이터 다양성이 높은 QDIT 방식이 테스트 명령과 더 유사한 형식의 훈련 데이터를 포함할 가능성이 높으며, 이는 모델이 새로운 명령에 직면했을 때 더 잘 일반화하고 적절하게 응답할 수 있게 함을 시사
결론 및 요약
결론은 명확합니다. 최고의 AI를 만들고 싶다면, 단순히 '좋은 데이터'를 모으는 것을 넘어 '다양한 데이터를 균형 있게' 모아야 합니다.
- AI의 편식은 금물: 고품질 데이터만으로는 예측 불가능한 질문에 취약한 '유리몸' 모델이 될 뿐입니다.
- 다양성은 강건성의 핵심: 데이터 다양성은 모델이 가장 어려워하는 문제를 해결하는 능력을 키워, 모델 전체의 신뢰도를 높입니다.
- QDIT는 훌륭한 레시피: QDIT 알고리즘은 이 과정을 자동화하여, 개발자가 더 적은 노력으로 더 강건하고 안정적인 모델을 만들 수 있는 구체적이고 강력한 도구를 제공합니다.
이제 우리 AI에게 최고급 사료만 줄 것이 아니라, 영양 균형을 고려한 '건강 식단'을 제공해야 할 때입니다.
