
Collection Framework
본 문서는 2021년 12월 20일 에 기록되었습니다.
기존에 작성했던 문서에서 언급하지 않았던 Stack, Queue, TreeMap, TreeSet 등을 포함하여 전반적인 공부를 하고 이에 대해서 최대한 깔끔하게 정리하는 것 을 목표로 삼게 되었습니다.
이 파트틑 알고리즘과도 매우 유사하기 때문에
이 기회에 구성만 해놓고 제대로 공부하고 작성하지 않은 Dev 알고리즘 시리즈 도 추가해보는 것을 목표로 삼게 되었습니다. [도식화 출처 : Essentials of Java]
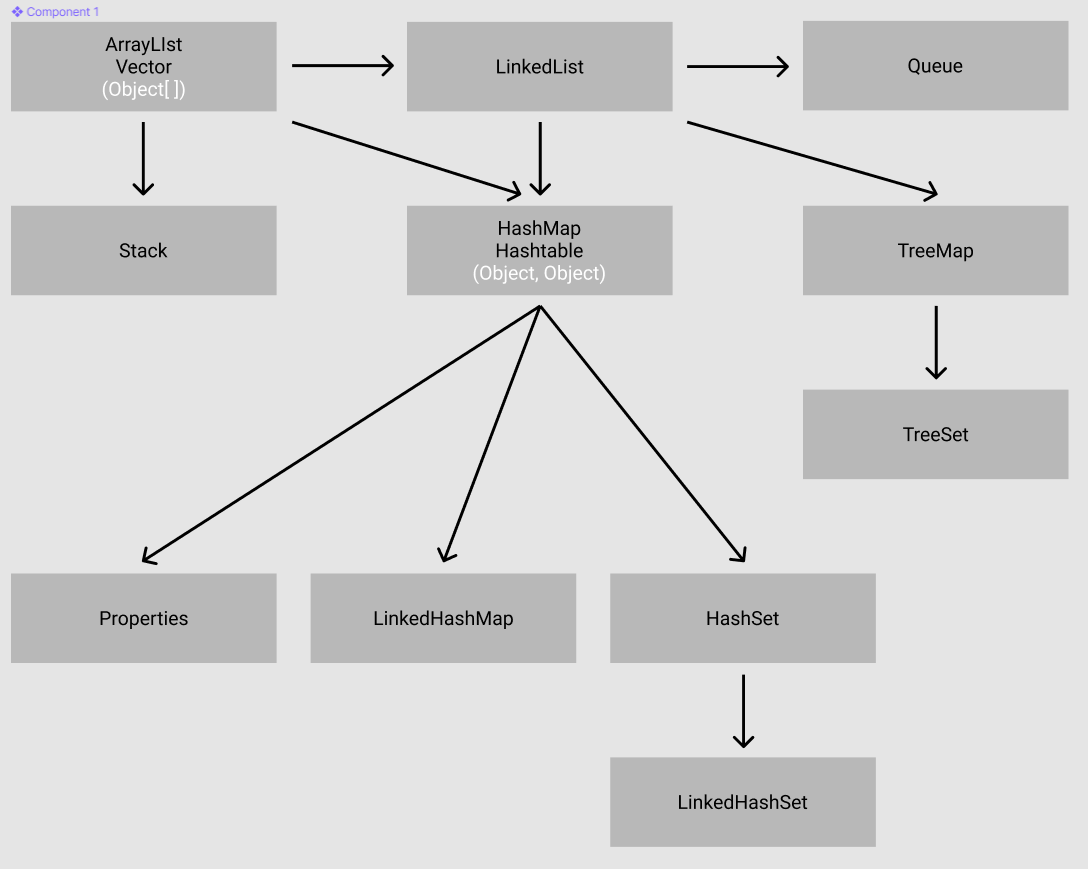
Interface
Collection Framework 는 다음의 핵심 인터페이스를 이용해서 구성되어 있습니다.
(Collection 인터페이스는 List 와 Map 의 부모 인터페이스이다. )
- List | 순서 가 있는 데이터 집합, 중복허용
- Set | 무질서한 데이터 집합, 중복불가
- Map | 무질서한 키-값 데이터 집합, 키는 중복불가, 값은 중복허용
4. Collection | List 와 Set 의 상속 부모
Collection Framework 이후에 생긴 클래스는 위의 인터페이스 명칭을 사용합니다.
Collection Framework 이전에 생긴 Vector, Stack, Hashtable, Properites 클래스는 독자적 명칭을 유지합니다.
또한, 되도록이면 새로 추가된 ArrayList 나 HshMap 등을 사용하는 것이 좋습니다.
Collection
다음과 같은 메서드들이 정의되어 있습니다.
사실 메서드 이름만 봐도 그 기능이 예상이 가기 때문에...
retain(Collection c) 정도만 확인해두고 넘어가면 될 것 같습니다.
| 메서드 |
|---|
| boolean add(Object o) boolean addAll(Collection c) |
| void clear() |
| boolean contains(Object o) boolean containsAll(Collection c) |
| boolean equals(Object o) 일반규약 확인 int hashCode() 일반규약 확인 |
| boolean isEmpty() |
| Iterator iterator() |
| boolean remove(Object o) boolean removeAll(Collection c) |
| booelan retain(Collection c) // 남기고 다 지우기 |
| int size() |
| Object[] toArray() Object[] toArray(Object[] a) |
List
순서 가 있는 질서가 있는 데이터의 집합으로 중복을 허용 하는 데이터 구조
List 를 상속하여 다음과 같은 클래스들이 구현되되었습니다.
- ArrayList
- LinekdList
- Vector
- Stack(Stack 은 Vector 를 상속)
다음과 같은 메서드들이 정의되어 있습니다.
| 메서드 |
|---|
| void add(int index, Object element) boolean addAll(int index, Collection c) |
| Object get(int index) |
| int indexOf(Object o) // 순방향 탐색 int lastIndexOf(Object o) // 역방향 탐색 |
| ListIterator listIterator() ListIterator listIterator(int index) // List 객체에 접근 가능한 ListIterator 반환 |
| Object remove(int idex) |
| Object set(int index, Object element) |
| void sort(Comparaotr c) // 지정된 비교자로 List 정렬 |
| List subList(int fromIndex, int tolndex) // 지정된 범위에 있는 객체 List 반환 |
Set
순서 가 없는 무질서한 데이터의 집합으로 중복을 불허 하는 데이터 구조
Set 을 상속하여 다음과 같은 클래스들이 구현되었습니다.
- HashSet
- SortedSet
- TreeSet
추가적인 메서드가 없다.
Map
순서 가 없는 무질서한 키-값 데이터 집합으로 키는 중복을 불허 하고 값은 중복을 허용 하는 데이터 구조
Map 을 상속하여 다음과 같은 클래스들이 구현되었습니다.
- Hashtable
- HashMap
- SortedMap
- LinkedHashMap (LinkedHashMap 은 HashMap 을 상속)
- TreeMap (TreeMap 은 SortedMap 을 상속)
다음과 같은 메서드들이 정의되어 있습니다.
| 메서드 |
|---|
| void clear() |
| boolean containsKey(Object Key) boolean containsValue(Object value) |
| Set entrySet() // Map 에 저장되어있는 Key-Value 쌍을 Map.Entry 타입의 객체로 저장한 Set 을 반환 |
| boolean equals(Object o) 일반규약 확인 int hashCode() 일반규약 확인 |
| Object get(Object key) |
| booelan isEmpty() |
| Set keySet() // 저장된 모든 key 객체 반환 |
| Object put(Object key, Object value) void putAll(Map t) |
| Object remove(Object key) // key 가 일치한 key-value 객체 삭제 |
| int size() // key-value 객체 숫자 반환 |
| Colection values() // Map 에 저장된 모든 key-value 반환 |
Map.Entry
Map 에서 다루는 데이터 구조인, 키-값 데이터 구조를 Entry 라고 부름니다.
Class
여기서부터는 Collection Framework 의 클래스들에 대해서 배울 것입니다.
학습의 주된 목표는 암기가 아닌 이해이다.
그리고 로직에 대한 이해 뿐만 아니라 언제, 왜 사용해야 하는가? 에 대한 이해입니다.
내가 구현하고자 하는 비즈니스 로직 상의 특징을 반영하여 어떤 자료구조를 쓸 것인가 를 잘 생각해보면, 길이가 늘어나 필요가 없고 중간 값을 삭제할 이유도 없다면 굳이 이러한 클래스를 쓸 이유도 없습니다. 기본 자료형 배열을 쓰는 것이 최고의 선택일 수도 있다고 생각합니다.
Class - List
ArrayList
ArrayList 는 기존의 Vector 클래스를 개선한 것입니다.
이는 Vector 와 구현원리와 기능적 측면에서 동일하다고 할 수 있습니다.
그럼에도 Vector 가 남아있는 이유는 이전에 작성한 코드와의 호환성 때문입니다.
따라서 둘 중 ArrayList 를 사용하도록 하자.
ArrayList 클래스를 열어보면 다음과 같습니다.
public class ArrayList<E> extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable {
// 상수 타입 변수
private static final long serialVersionUID=상수값;
private static final int DEFAULT_CAPACITY=10;
private static final Object[] EMPTY_ELEMENTDATA={};
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA={};
// 실제 배열 공간 | transient 는 직렬화 키워드이다.
transient Object[] elementData;
// 배열 사이즈
private int size;
}이러한 ArrayList 는 세가지 생성자를 가지고 있다.
자세한 코드는 java.util.ArrayList 를 참고하도록 하자.
- 10의 길이(DEFAULT_CAPACITY) 인 Object 배열 생성
- 지정 길이(int initialCapacity) 인 Object 배열 생성 | 권고
- Collection 이 저장되어 있는 Object 배열 생성
public ArrayList() { /* ... */ }
public ArrayList(int initialCapacity) { /* ... */ }
public ArrayList(Collection<? extends E> c) { /* ... */ }ArrayList 도 결국은 배열을 다루고 있다.
그리고 배열은 생성 당시에 정해진 길이에서 늘어나거나 줄일 수 없는 특징을 가질 수 있다.
이를 늘리거나 줄일려면 길이+1 의 배열 객체를 생성하여 전부 옮겨 담아야 한다.
ArrayList 은 이 과정을 메서드화 시켰을 뿐이지, 배열의 한계를 벗어난 것은 아니다.
따라서 배열의 길이를 안다면, 처음부터 그 길이에 맞는 값 을 넣는 것이 좋다.
다음과 같은 메서드들이 정의되어 있다.
| 메서드 |
|---|
| booelan add(Object o) void add(int index, Object element) boolean addAll(Collection c) boolean addAll(int index,Collection c) |
| boolean remove(Object o) boolean removeAll(Collection c) boolean retainAll(Collection c) |
| Object[] toArray() Object[] toArray(Object[] a) |
| void trimToSize() void ensureCapacity(int minCapacity) |
| 이후 생략(Essesntials of Java 585 p 혹은 API 참고) |
LinkedList
LinkedList 는 배열의 단점을 극복하기 위해 만들어진 자료구조이다.
배열의 장단점은 아래 인용구문을 확인하자.
배열은 다음과 같은 장점이 있다.
1. 구조가 간단하여 사용하기 쉽다.
2. 데이터를 읽어오는데 걸리는 시간이 가장 빠르다.배열은 다음과 같은 단점이 있다.
1. 크기를 변경할 수 없다.
2. 비순차적인 데이터의 추가 또는 삭제에 시간이 많이 걸린다.
LinkedList 는 배열에 Node 라는 것을 추가하여 만들어진 자료구조이다.
이는 일전에 맛보았던 블록체인의 특징과 SQL 이론의 그래프 이론의 개념과 유사해보였다.
LinkedList 는 배열을 가지고 있고 각 배열의 다음 칸으로 향하는 Node 를 가지고 있다.
배열의 추가 및 삭제가 매우 빠른 속도로 처리되는 장점이 있다.
또한, 배열의 다음 요소에 대한 접근도 매우 빠르다는 장점이 있다.
그러나 배열의이전 요소에 대한 접근은 어려운 것을 극복하기 위해
배열의 다음 요소에 대한 접근성을 가진 Doubly LinkedList 도 만들어지게 되었다.
그러나 배열의 마지막 칸에서 첫번째 칸으로 가는 것과 그 반대는 어려웠기에
배열의 시작과 끝이 연결된 Doubly Circular linked List 도 만들어지게 되었다.
ArrayList + LinkedList
| 클래스 | 읽기 | 추가/삭제 |
|---|---|---|
| ArrayList | 빠르다 | 느리다 |
| LinkedList | 느리다 | 빠르다 |
위의 특성을 고려하여 처음 데이터를 저장할 때는 ArrayList 를 사용하고
작업할 때는 LinkedList 를 사용하면 좋은 효율을 얻을 수 있을 것이다.
ArrayList arrayList=new ArrayList(1000000);
for( int i=0; i<100000; i++){
arrayList.add(i+"");
}
LinkedList linkedList=new LinkedList(arrayList);
for(int i=0; i<1000; i++) linkedList.add(500, "X");Stack & Queue & PriorityQueue & Deque
Stack, Queue
Stack 과 Queue 는 다음과 같은 특징을 가진다.
- Stack | LIFO | 마지막에 들어간 요소가 가장 빨리 나온다.
- Queue | FIFO | 처음 들어간 요소가 가장 빨리 나온다.
그 특징을 생각해보면 Stack 은 ArrayList가 Queue 는 LinkedList 가 적합하다.
Queue 는 첫 요소가 계속 사라질텐데 그때마다 배열을 새로 생성하고 옮기는 것은 부적절하다.
아래는 Stack 및 Queue 객체 생성 방법이다.
Stack stack=new Stack();
Queue queue=new LinkedList();이상한 점이 보이는가?
바로 Stack 은 본인의 생성자를 쓰고 있지만 Queue 는 LinkedList 의 생성자를 쓰고 있다는 점이다.
이는 API 를 확인하면 알 수 있다.
// Stack
public class Stack<E> extends Vector<E> {}
// Queue
public interface Queue<E> extends Collection<E> {}그렇다 Queue 는 인터페이스였기 때문에 생성자를 가질 수 없는 것이다.
그렇다면 어떻게 LinkedList 가 들어갈 수 있을까?
Essentials of Java 에는 LinkedList 가 Queue 의 구현체이기 때문에 가능하다고 했다.
따라서 우리는 LinkedList 를 타고 올라가보면 다음과 같은 상속도를 확인할 수 있다.
// LinkedList
public class LinkedList<E>
extends AbstractSequentialList<E>
implements List<E>, Deque<E>, Cloneable, java.io.Serializable {}
// Deque
public interface Deque<E> extends Queue<E> {}그렇다.
우리는 Deque 가 뭔지는 모르지만, Deque 가 Queue 를 상속하고
LinkedList 가 Deque 를 구현함으로써 최종적으로 Queue 의 구현체가 되었음을 알 수 있다.
자식타입은 부모타입으로 선언된 변수 공간에 업캐스팅 되어 들어갈 수 있는 특징을 생각해보자.
이는 너무나 당연한 것이다.
priorityQueue
Queue 의 구현체 중 하나로 PriorityQueue 도 있는데,
이는 저장 순서와 무관하게 우선순위가 높은 것부터 꺼내게 되는 특징이 있으며 null 값을 넣을 수 없습니다. 이를 무시하고 null 을 넣을 시에는 NullPointerException 이 발생합니다.
기본 배열을 통하고 있다는 점은 다르지 않지만,
Priority Queue 는 자료구조 Heap을 응용한 것이며, 이는 JVM 의 Heap 과 전혀 다른 것입니다. 프로세스가 궁금하다면 Heap Sort 를 참고하면 좋을 것 같습니다.
Priority Queue 는 Heap Sort | Priority Queue Sort 를 확인하면 좋을 것 같습니다.
Deque
양쪽으로 추가 삭제가 가능한 자료구조
스텍과 큐를 합쳐놓은 자료구조로써 아래의 표를 참고하자
| Deque | Stack | Queue |
|---|---|---|
| offerLast() | offer() | push() |
| pollLast() | - | pop() |
| pollFirst() | poll() | - |
| peekFirst() | peek() | - |
| peekLast() | - | peek() |
Iterator & ListIterator & Enumeration
사실 Iterator 를 사용해본 적이 있거나
자세히 공부하려고 구글링을 해본 사람이라면
이 부분에 대한 매력이 없음을 느낄 수 있다고 생각한다.
적어도 나는 이 인터페이스의 사용 이유 를 잘모르겠다.
지금에 와서는 adv for문 (for each 문이라고도 하지만, .forEach() 와 혼란스럽기 때문에 나는 adv for문이라고 하는 것을 선호한다.) 도 있고 여러 방법이 있는데 속도 및 기능적으로 제한 적인 위 방법을 사용해야 할 이유가 있는가?
따라서 나는 이 내용에 대한 추가적인 필기를 해야 할만큼의 필요성을 느끼지 못하고 있다.
혹시 공부하고 싶은 사람이 있다면, Essentials of Java 614p 혹은 구글링을 통한 포스트 참고 를 추천한다.
Arrays
Arrays 클래스를 사용할 이유는 다음과 같은 경우가 있을 것 같다.
- 배열을 출력하고 싶을 때
- 배열을 정렬하고 싶을 때
- 배열을 검색(Binary Search) 하고 싶을 떄
// 배열을 출력하고 싶을 때
int valuesOfOne={ 3, 0 };
int valuesOfTwo={ {3,0},{1,2} };
int valuesOfThress={ { {3,0},{1,2} } , { {1,4},{5,2} } };
System.out.print(Arrays.toString(valuesOfOne));
System.out.print(Arrays.deepToString(valuesOfTwo));
System.out.print(Arrays.deepToString(valuesOfThree));
// 배열을 정렬하고 검색(Binary Search) 하고 싶을 때
int values[]={ 3, 2, 0, 1, 4 };
int resultOfBinarySearch=Arrays.binarySearch(values, 2); // -5
Arrays.sort(values); // 0 1 2 3 4
int resultOfBinarySearch=Arrays.binarySearch(values, 2); // 2 추가적으로 다른 기능들도 지원된다.
- 배열을 List 로 바꾸고 싶을 때 asList
- 배열 처리를 여러 쓰레드로 나누어 처리하고 싶을 때
1번은 추가 설명이 불필요하다고 생각하고 2번에 대해서는 나중에 람다와 스트림을 배울 때 보완하려고 한다.
본 내용은 2021년 12월 21일 에 추가 되었다.
Arrays.asList 의 사용법 및 주의사항
Arrays.asList 를 이용하면 손쉽게 List 타입 객체를 만들 수 있다.
그러나 주의할 점은 추가 변형이 불가 하다라는 것이다.
아래의 코드를 실행하면 UnsupportedOperationException 이 발생한다.
// java.lang.UnsupportedOperationException
List<Integer> list=Arrays.asList(3,4,5,6);
list.add(3);따라서 다음의 방법을 사용할 수도 있으나 권고하지는 않는듯하다.
이 방법에서는 어떤 Exception 도 발생하지 않는다.
List<Integer> list=new ArrayList<>(Arrays.asList(3,4,5,6);
list.add(3);그래서 왜 안되는건데?
의문의 내용은 두 가지였다.
- 내부클래스여서 안된다고? 대체 무슨 인과성이지?
- 그러면 내부 클래스에서 안된다며, 어떻게 ArrayList 의 생성자에서는 이를 받아들인거야?
내부 클래스여서 안된다고? 단순히 그 이유?
애초에 두 ArrayList 의 제어자가 달랐다.
static 타입의 ArrayList라서 변경이 불가능했던 것일까?
아니다. 그렇다면 다른 이유가 있을 거라고 생각한다.
// java.util.ArrayList
public class ArrayList<E> extends AbstractList<E>
implements List<E>, RandomAccess, Cloneable, java.io.Serializable { /* */}
// java.util.Arrays.ArrayList
private static class ArrayList<E> extends AbstractList<E>
implements RandomAccess, java.io.Serializable{ /* */}어떤 장소에 저장하고 있는지도 확인해보자.
애초에 저장된 공간값이 상수값이라서 변경이 불가능하다.
// java.util.ArrayList 필드 안의 멤버변수
// 오브젝트 타입 배열
transient Object[] elementData;
// java.util.Arrays.ArrayList 필드 안의 멤버변수
// fianl 타입 + 타입 매개변수 E 타입 배열
private final E[] a;new ArrayList(Collection c) 업캐스팅?
만약 업캐스팅 되어서 들어간거라면 내부 클래스의 시작점을 찾아보자.
생성자에 넣으면 업캐스팅 되는 것이 맞았다.
// java.util.Arrays 약 3806 번 라인, 내부클래스 ArrayList
private static class ArrayList<E> extends AbstractList<E>
implements RandomAccess, java.io.Serializable{ /* */}
// java.util
public abstract class AbstractList<E> extends AbstractCollection<E> implements List<E> { /* */ }
// java.util
public abstract class AbstractCollection<E> implements Collection<E> { /* */}Comparator & Comparable
java.lang.Comparable 와 java.util.Comparator 의 실제 소스는 다음과 같다.
// java.util.Comparator
public interface Comparator {
int compare(Ojbect o1, Object o2) {}
boolean equals(Object obj);
}
// java.lang.Comparable
public interface Comparable {
public int compraeTo (Object o);
}모든 클래스는 Object 클래스를 상속하고 따라서 equals 메서드를 가지고 있음은 모두 알 것이다. 따라서 Comparator 이 가지고 있는 abstract boolean equals(Object obj) 는 재정의 해야 함을 강조할 뿐이다.
Class - Set
HashSet
본 문서는 2021년 12월 04일 에 기록되었다.
그러나 다음의 이유로 재작성을 결정하게 되었다.
- 체계적이지 못한 공부 및 정리
- Collection Framework 의 몇몇 자료구조의 누락
Collection Framework(구버전)
데이터를 저장하는 자료구조와
이를 처리하는 알고리즘을 클래스화 시켜놓은 프레임 워크
컬랙션 프레임워크는 매우 쓸만한 프레임워크라고 생각한다.
하지만 여러가지 불편한 점들이 있다.
ArrayList 나 HashSet 은 adv for 문을 통해서 해결할 수 있으나,
HashMap 같은 경우는 인자가 2개가 있어서 이를 쓸 수없다.
그렇기 때문에 forEach 문을 이용해서 각 Entry 에 접촉해 데이터를 빼낼 수 있다.
이에 관해서는 람다식 을 제대로 공부해보고 추가해보도록 하자.
종류
ArrayList
일반적으로 배열은 길이가 늘어날 수 없다.
이를 늘리려면 임시배열을 이용해서 늘려야 한다.
이러한 알고리즘을 구현해 놓은 것이 ArrayList 이다.
import java.util.ArrayList;
public class Main{
public static void main(String[] args){
ArrayList<Integer> dataList=new ArrayList<>()
}
}boolean add(Object obj);
ArrayList 에 새로운 요소를 넣는다.
반환타입은 boolean 이다.
boolean remove(Object obj);
ArrayList 에 .equal 한 요소를 제거한다.
반환타입은 boolean 이다.
Generic get(int index);
ArrayList 에 index 를 이용해 접근한다.
반환타입은 Generic 과 동일하다.
HashSet
Set 의 자료구조를 따른다.
값들이 중복되지 않는 특성을 가진다.
따라서 특정한 값의 포함여부를 확인할 때 매우 효과적이다.
import java.util.HashSet;
public class Main {
public static void main(String[] args) {
HashSet<Integer> userSet=new HashSet<Integer>();
}
}int size();
HashSet 의 길이를 반환한다.
boolean ad(Object obj);
HashSet 에 새로운 요소를 넣는다.
반환타입은 boolean 이다.
boolean contians(Object obj);
HashSet 에 새로운 요소를 넣는다.
반환타입은 boolean 이다.
boolean remove(Object obj);
HashSet 에 .equal 한 요소를 제거한다.
반환타입은 boolean 이다.
HashMap
Key-Value 로 대응되는 Entry 타입의 데이터들로 이루어진 Map 자료구조 중 하나
자세한 것은 아래에 후술
Generic2 put(Generic Generic2);
HashMap 에 새로운 요소를 넣는다.
HashMap Key 추출하기
Key 추출은 2가지 방법을 사용할 것이다.
1. 타입 변환을 통한 추출
2. Ramda 인 forEach 문을 이용한 추출
타입 변환을 통한 추출
public class Main{
public static void main(String[] args){
Set<String> wordKey=wordMap.keySet();
Iterator<String> wordIter=wordKey.iterator();
ArrayList<String> wordList=new ArrayList<String>();
while(wordIter.hasNext()) {
wordList.add(wordIter.next());
}
System.out.println(wordList);
}
}forEach 문을 이용한 추출
public class Main{
public static void main(String[] args){
wordList.forEach((key,value)->{
System.out.println(key);
});
}
}HashMap Value 추출하기
Key 추출은 2가지 방법을 사용할 것이다.
1. 타입 변환을 통한 추출
2. Ramda 인 forEach 문을 이용한 추출
타입 변환을 통한 추출
public class Main{
public static void main(String[] args){
Collection<String> wordValue=wordMap.values();
Iterator<String> wordValueIter=wordValue.iterator();
ArrayList<String> wordValueList=new ArrayList<String>();
while(wordValueIter.hasNext()) {
wordValueList.add(wordValueIter.next());
}
System.out.println(wordList);
}
}forEach 문을 이용한 추출
public class Main{
public static void main(String[] args){
wordList.forEach((key,value)->{
System.out.println(value);
});
}
}HashMap key,value 추출하기
Key 추출은 2가지 방법을 사용할 것이다.
1. 타입 변환을 통한 추출
2. Ramda 인 forEach 문을 이용한 추출
타입 변환을 통한 추출
public class Main{
public static void main(String[] args){
Set<Entry<String, String>> wordEntrySet=wordMap.entrySet();
Iterator<Entry<String, String>> wordEntryIter=wordEntrySet.iterator();
Entry<String, String> wordEntry;
String wordEntryKey="";
String wordEntryValue="";
while(wordEntryIter.hasNext()) {
wordEntry=wordEntryIter.next();
wordEntryKey=wordEntry.getKey();
wordEntryValue=wordEntry.getValue();
System.out.println(wordEntryKey+"/"+wordEntryValue);
}
}
}forEach 문을 이용한 추출
public class Main{
public static void main(String[] args){
wordList.forEach((key,value)->{
System.out.println(key+"/"+value);
});
}
}