
본 후기는 작성자가 소속된 회사와는 상관 없는 개인의 생각입니다.
Intro
작년 11월 회사에서 서버리스 환경을 시도했으나, 여러 이유로 철회하였습니다.
이 시기에 개인적으로 코드형 인프라(IaC)인 AWS CDK를 배우게 되었습니다.
AWS CDK를 사용해서 Microservices Serverless 서버를 띄우는 경험은 색다르고 재밌었습니다.
추가적으로 Terraform이라는 도구도 경험하게 되면서 선언형 문법을 포함해 많은 부분에서 충격을 받았습니다.
전체적으로 Terraform이 추구하는 길이 재밌게 읽었던 제로 트러스트 보안과 같은 것 같아서 더 흥미로운 것 같습니다.
본 후기는 클라우드를 공부하고 있는 신입 개발자의 시선으로 작성되었습니다.
최대한 내용을 검증하고 작성하였으나, 사실과 다른 내용이 존재할 수 있습니다.
HashiCorp
HashiCorp는 인프라 자동화, 보안, 유틸리티 솔루션을 제공해주는 기업입니다.
이번 컨퍼런스에서는 다음과 같은 내용이 중점적으로 다뤄진 것 같습니다.
1, HashiCorp 서비스에 대한 전반적인 개요
2. 신뢰 모델과 제로 트러스트 모델
3. 멀티/하이브리드 클라우드 운영
4. 국내 고객 사례
이 중에서 가장 재밌게 들었던 신뢰 모델과 트러스트 모델을 중심으로 후기를 작성하였습니다.
Armon Dadgar님의 개요를 따르되, 보충할 내용은 도서 "제로 트러스트 보안"에서 참조하였습니다.
멀티/하이브리드 클라우드 운영과 제로 트러스트 보안 - Armon Dadgar
올해 키노트는 HashiCorp CTO인 Armon Dadgar님이 발표하셨습니다.
컨퍼런스에서 동시 통역으로 들었던 경험이 처음이라서 매우 신기했습니다.
- 서비스를 만드는 과정
- 신뢰 모델/경계 모델에 대하여
- 신뢰 모델/경계 모델의 문제점
3.1. 신뢰 그 자체
3.2. 대규모 트래픽에 부적합한 구조
1. 서비스를 만드는 과정
Armon Dadgar는 서비스 개발 및 운영 과정을 3개의 단계로 구분하였습니다.
- Pre Deploy
- Version Control : GitHub과 같은 버전 관리 툴
- Static Analysis : 코드 정적 분석 툴
- Development & Deployment
- 서비스를 개발하고 배포하는 과정
- Observability
- 서비스 모니터링을 통해서 제품을 안정적으로 운영
2. 신뢰 모델/경계 모델에 대하여
인터넷 사용자가 늘어나며 공용 IP수가 빠르게 줄었습니다. 이에 사설 네트워크 할당 RFC 1597을 통해서 사설 네트워크 개념이 생겼습니다.
기업들은 독립적인 주소 체계를 가진 네트워크를 가지게 되었습니다. 기업 간의 연결이 필요한 경우에는 네트워크 인터페이스를 이용합니다.
이때, 기업이 외부 인터넷을 이용해야 합니다.
하지만 공용 인터넷과 사설 인터넷의 주소 체계가 다른 문제가 있습니다.
이에 IP 네트워크 주소변경 RFC 1631를 통해서 NAT(Network Address Translation)이 등장했습니다.
NAT은 다음과 같은 특성을 가지고 있어서, 사실상 스테이트풀한 방화벽의 특성을 지니고 있습니다.
- NAT 내부에서 외부로 나갈 수 있다.
- NAT 외부에서 내부로 들어올 수 없다.
이러한 환경에서 신뢰 모델/경계 모델이 등장했습니다.
해당 모델은 다음과 같이 구분됩니다.
- 외부 인터넷
- 서버 (DMZ)
- 사설 네트워크
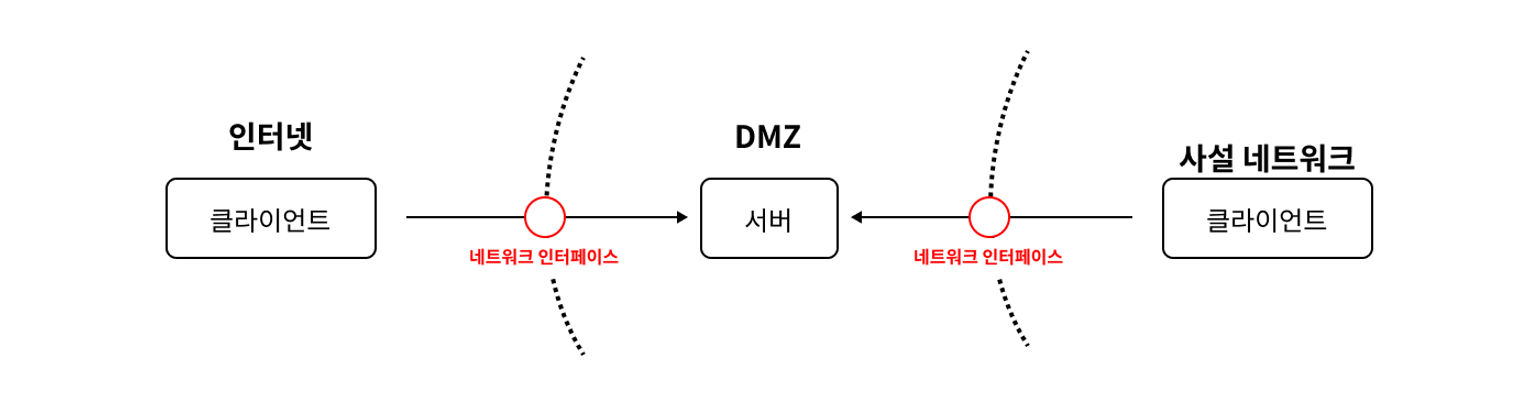
위를 신뢰 모델/경계 모델이라고 부르는 이유는 각 구성요소의 경계선만 주의하기 때문입니다.
즉, 경계선에만 WAF, VPN 등과 같은 보안 솔루션을 적용합니다. 일단 경계선을 넘어오면 안전한 사용자로 간주하고 신뢰합니다,
3. 신뢰 모델/경계 모델의 문제점
대표적인 문제점은 2가지가 있습니다.
- 신뢰 그 자체
- 대규모 트래픽에 부적합한 구조
3.1. 신뢰 그 자체
해당 모델에서는 신뢰가 바로 보안 취약점이 됩니다.
공격자가 경계선을 넘을 경우 신뢰받는 개발자와 동일한 행위가 가능해집니다.
3.2. 대규모 트래픽에 부적합한 구조
신뢰 모델에서는 기본값이 허용(Allow)입니다.
서비스가 엔터프라이즈급이 될수록 거부 대상 트래픽(Deny Traffic)이 늘어나기 떄문에, 이러한 구조는 비효율적입니다.
4. 제로 트러스트 모델
제로 트러스트 모델은 기본적으로 모든 요청을 믿지 않습니다.
요청자가 어떤 위치에 있는지와 무관하게 잠재적 공격자로 간주합니다.
따라서 제로 트러스트 모델은 신뢰 모델/경계 모델의 근본적인 단점을 극복할 수 있습니다.
3.1. 신뢰 그 자체
3.2. 대규모 트래픽에 부적합한 구조Armon Dadgar는 이와 관련해 몇가지 키워드를 제시하였습니다.
- Explicit Auth : 명확하고 명정하게 인증하자
- Default Deny : 접근 권한이 없으면 기본적으로 거절하라
- Identification based Control : ID 기반 통제
5. 서비스 개발과 Identification
Armon Dadgar는 서비스 개발에서 일어나는 Identity 관계를 다음의 네 가지로 구분하였습니다.
각각의 Identity 별로 디테일한 설명, 주의사항 및 솔루션을 안내해주고 있습니다.
- Human Identity
- Machine Identity
- Machine to Machine Identity
- Machine to Human Identity
5.1. Human Identity
어떠한 요청자 A가 누구인지 어떻게 표현해야 할까요?
Armon Dadgar는 SSO나 IDP를 활용할 것을 안내하였습니다.
- SSO(Same Sign On) : 통합 로그인
- IDP(Identity Provider) : 신원 공급자
여기서 IDP는 조금 생소한 개념일텐데, 어떠한 요청자 A에 대한 임시 신분증을 공급해주는 역할을 합니다.
5.2. Machine Identity
어떠한 어플리케이션 A가 누구인지 어떻게 표현해야 할까요?
Armon Dadgar는 자사 서비스인 HashiCorp Vault를 소개하며, 다음과 같이 어플리케이션 A에 대한 신원 정보를 저장, 관리, 활용하는 방식을 안내합니다.
- Identity Declare : 어플리케이션 A가 누구인지 정의합니다.
- Secret Manager : Key Vaule 구조로 값을 저장하며, Value에는 정적인 값이 담깁니다.
- Dynamic Secret : Key Value 구조로 값을 저장하되, Value에는 동적인 역할이 담깁니다.
이 중에서도 Dynamic Secret을 사용하면 다음과 같은 것들을 손쉽게 구성할 수 있습니다.
- N일 이하 자동 교체
- 키에 대한 라이프 사이클 관리 필요 없음
- 키의 삭제에 대한 추가 유지 보수 필요 없음
5.3. Machine to Machine Identity
어플리케이션 A가 어플리케이션 B에 접속하는 것을 어떻게 제어할까요?
만약 어플리케이션의 수가 수천개에 달한다면, 어떻게 안정적이고 효율적으로 운영할 수 있을까요?
Armon Dadgar는 HashiCorp Consul을 사용한 사례를 소개하였습니다.
- Discovery
- Server Mash
- Network Automation
예시를 통해서 구체적으로 살펴볼 수 있었습니다.
5.3.1. 수 천 개의 Spot에 LB 연결 시 성능 저하
일반적으로 서버들에 부하 분산을 하기 위해서 로드 밸런서(Load Balancer)를 사용합니다.
하지만 서버의 숫자가 수 천개가 늘어나면 결국 로드 밸런서에 부하가 걸리고 성능 저하가 발생합니다.
로드 밸런서는 결국 IP 기반 하드 코딩 것과 같기 때문입니다.
하지만 Consul을 사용하면 Namespace 기반 연결을 통해서 이 문제를 해결할 수 있습니다.
5.3.2. 수 천 개의 Spot의 연결 허용과 연결 거부
다음의 요구사항을 어떻게 달성할 수 있을까요?
- 어플리케이션 A에서는 어플리케이션 C에 접속이 가능하다.
- 어플리케이션 B에서는 어플리케이션 C에 접속이 불가능하다.
단순히 IAM 권한을 정의하거나 IP 기반 하드 코딩 방식이 맞을까요?
서버 및 컨테이너의 수가 수 천개가 넘어가면 어떻게 될까요?
여기서는 Consul을 사용해서 TLS Handshake하는 과정을 안내합니다.
이를 통해 모든 요청-응답은 제한된 사용자 만이 가능해집니다.
이 때, 모든 어플리케이션들(N개) 앞에는 TLS 핸드 쉐이크를 위한 프록시 서버를 배치합니다.
5.3.3. 방화벽이 있는 상태에서의 Consul
만약 다음의 요구사항을 달성해야 한다면 어떻게 할 수 있을까요?
- 애플리케이션 A에서는 DB A에 접속 가능
- 애플리케이션 B에서는 DB A에 접속 가능
Java, PHP 와 같은 전통적인 웹 서버의 경우 보안 정보와 함께 방화벽을 통과해야 합니다.
이 경우에도 Consul을 사용할 수 있다고 하였는데, 솔직히 이 부분은 이해가 되지 않았습니다.
추후에 동영상이 공개되면, 다시 확인해보면 좋을 것 같습니다.
5.4. Machine to Human Identity
어떠한 어플리케이션 A에 요청자 A가 접속하고 싶으면 어떻게 해야 할까요?
전통적인 어플리케이션에는 아마도 다음과 같은 구조를 따를 것입니다.
- 요청자 A -> VPN -> ? -> PAM -> 어플리케이션 A
이 경우, 요청자 A의 부주의를 포함한 다양한 보안 위협에 노출이 됩니다.
하지만 HashiCorp Boundary를 사용하면 Boundary를 통해서 어플리케이션 A로 접속하는 경로를 열게 됩니다.
- 요청자 A -> Boundary -> 어플리케이션 A
물론, 이 과정에서 요청자 A는 5.1.에서 언급한 SSO로 스스로를 인증해야 합니다.
6. 결론
클라우드 환경에서 서비스를 운영하고 있는 기업이라면 보안 정보 관리의 위험성에 노출되어 있습니다.
기존의 신뢰 모델/경계 모델은 다음과 같은 단점이 있습니다.
- 보안 취약점에 노출된다.
- 대규모 트래픽에 부적절하다.
하지만 제로 트러스트 모델은 위와 같은 단점을 해결합니다.
이를 위해서 HashiCorp에서는 Vault, Consul, Boundary 등의 제품을 제공합니다.
