1. huggingface에서 사용할 lm 모델 다운로드 받기 + 환경설정
나는 wsl에서 conda환경을 설정했다.
python 버전은 3.11으로 해야 테디노트님 requirements.txt의 패키지버전들과 충돌이 안나 3.11로 설정했다.
2. Modelfile 설정하기
modelfile을 제대로 설정하지 않으면, 모델이 답변 후 헛소리를 반복하는 경향이 있다고 함. modelfile의 template는 모델 학습 시의 template을 확인하고 넣어주어야한다.
모델의 base모델의 template을 가져와야한다.
나는 llama3-KO-8B 모델을 가져왔기 때문에, llama3 공식 문서에서 제공해주는 prompt template인
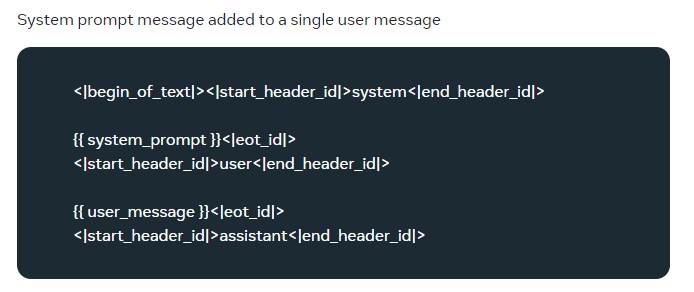
이 코드를 modelfile에 넣어주었다.
HOWEVER,,,, 위 코드 그대로 Ollma에 올려서 run하게 되면
오류 1
template: :3: function "system_prompt" not defined
라는 오류를 만나게 된다.
modelfile의 template의 {{ }}부분을 ollama 공식 github 문서에 나오는 template의 변수명으로 변경해주어야한다.
FROM llama-3-open-ko-8b-instruct-preview.Q8_0.gguf
TEMPLATE """<|begin_of_text|><|start_header_id|>system<|end_header_id|>
{{ .System }}<|eot_id|><|start_header_id|>user<|end_header_id|>
{{ .Prompt }}<|eot_id|><|start_header_id|>assistant<|end_header_id|>"""
SYSTEM """A chat between a curious user and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the user's questions."""
PARAMETER stop <|start_header_id|>
PARAMETER stop <|eot_id|>{{ system_prompt }} -> {{ .System }}
{{ user_message }} -> {{ .Prompt }}
이렇게 변경하면 error 해결된다.
오류 2 stop token 지정하기
테디노트님 튜토리얼의 model은 solar가 base 모델이었고,
나는 llama3를 이용하려고하다보니 token의 명칭이 달라서
수정이 필요했다.
그런데, stop 토큰을
PARAMETER stop <|start_header_id|>
PARAMETER stop <|end_header_id|>로 했을 때는,

화면와 같이 user, assistant role도 출력이 되었다.
그리고,
PARAMETER stop <|start_header_id|>
PARAMETER stop <|eot_id|> 로 하거나,
PARAMETER stop <|eot_id|>
PARAMETER stop <|end_header_id|>로 했을 때는

assistant만 출력이 되었다.
그러면서 답변이 끊이지 않고 이어지는 오류가 발생했다.
몇번을 모델을 지웠다 만들었다 하다가
테디노트님의 로컬에서 Llama3-8B 모델 돌려보기 영상에
LLAMA3에 맞게 Modelfile을 올려주셔서 그대로 들고와 해보니 아주 잘 실행이되었다! 감사합니다 테디노트님!!!
최종 modelfile 코드
FROM llama-3-open-ko-8b-instruct-preview.Q8_0.gguf
TEMPLATE """{{- if .System }}
<|begin_of_text|>system {{ .System }}<|end_of_text|>
{{- end }}
<|begin_of_text|>user
{{ .Prompt }}<|end_of_text|>
<|begin_of_text|>assistant
"""
SYSTEM """A chat between a curious user and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the user's questions."""
PARAMETER temperature 0
PARAMETER num_ctx 4096
PARAMETER stop <|begin_of_text|>
PARAMETER stop <|end_of_text|>
PARAMETER stop <|eot_id|>
PARAMETER stop <|end_of_text|>참고로, num_ctx 변수는 다음 토큰 생성을 위한 context 창의 크기라고 공식문서에는 설명되어있지만 쉽게 말하면 출력되는 토큰의 최대값. 디폴트 값은 2048
3. ollama에 local에 있는 모델 올려주기
ollama 모델 생성
ollama create llama3-KO-8B -f Llama-3-Open-Ko-8B-Instruct-preview-GGUF/Modelfileollama 모델 실행
ollama run llama3-KO-8B이렇게 하면 우선 ollama에 모델을 올린 것까진 성공.
다음 포스트에서는 langserve와 연결하는 과정을 적어보아야겠다.

정리를 잘하셔서 이해하기가 훨씬 쉬웠습니다. 공유 감사합니다!