- 새로운 구문 (1)
1) 튜플과 구조적 바인딩
- 컬렉션: 여러 자료를 규칙적으로 담아놓은 자료구조
=> 한번에 많은 자료 반환 가능
- 튜플: 컨테이너의 한 종류, 다른 종류의 데이터 형식을 한 집합으로 묶을 수 있음
std:tuple<자료형 1, 자료형 2, ... , 자료형 n> 튜플 이름;으로 선언
make_tuple함수, 복사 생성자 호출, 유니폼 초기화 등 이용 가능
=> 다양한 데이터 형식을 포함하기 때문에 auto로 선언하면 편리
get<인덱스> (튜플 객체 이름);으로 튜플 안의 원소값을 가져올 수 있음
swap: 두 튜플의 구성이 같을 때 원소값을 서로 교환
tuple_cat: 여러개의 튜플을 하나로 합침
std::tie: 튜플을 해체하여 각각의 원소를 변수에 매칭
std::ignore: 해당 위치의 원소는 변수에 매칭하지 않고 넘어감
- 튜플과 구조체의 차이
- 튜플은 인덱스를 기반으로 원소에 접근하지만, 구조체는 명시적인 이름으로 접근
- 튜플은 비교 연산자 =를 기본으로 제공하지만, 구조체는 사용자가 직접 오버로딩 해야함
- 튜플은 swap함수로 두 객체의 원소값을 교환할 수 있지만 구조체는 원소별로 일일이 교환해야함
- 구조적 바인딩: 특정 구조의 데이터 형식을 해체하여 낱낱의 변수에 저장하는 기능. 배열, 구조체, 튜플, 맵에서 사용 가능
- 해체된 원소는 auto[ ] 또는 const auto[ ]처럼 대괄호로 둘러쌓인 변수 집합에 저장
- 해체한 원소를 대입하기만 하면 되기 때문에 간단하지만, 해체한 원소의 개수와 이를 저장할 변수의 개수는 반드시 같아야함
std::ignore함수 사용 불가, 사용하지 않는 원소가 있더라도 변수로 받아야 함
- 튜플과 구조적 바인딩 조합
튜플을 전달받을 때 구조적 바인딩을 사용하면 여러개의 반환값을 데이터 집합이 아닌 개별 변수로 사용할 수 있음... auto[monster_type, monster_name, hp, power] =get_monster_status (monster_a_inst); // 구조적 바인딩 cout<<monster_name<<"("<<monster_type<<") :hp(" <<hp<< "), power(" <<power<< ")"<<endl; // 구조적 바인딩으로 해체된 원소값 출력 ...
2) 범위 기반 for문
- 범위 기반 for문: 데이터 집합을 정확하고 안전하게 순회할 수 있게 도와줌
= 개발자가 반복을 직접 제어하지 않고 대상 데이터 집합의 크기만큼만 순회하는 방법for (데이터 형식 변수 이름: 배열/ 컨테이너) { 반복 실행문 }
사용법이 간단한 대신 순회할 수 있는 데이터 형식은 제한됨
- 컴파일러가 반복 횟수를 명확히 알 수 있는 데이터 형식만 사용 가능)
- 배열, 유니폼 초기화로 초기화된 리스트, begin/ end함수를 제공하는 컨테이너 등 사용 가능
- 포인터에 할당된 동적 메모리는 사용 불가
ex) for문과 범위 기반 for문#include <iostream> #include <array> using namespace std; int main (void) { array<int, 10> numbers { 7, 8, 2, 5, 3, 9, 0, 4, 1, 6 }; for (int i = 0; i < 10; ++i) { // for 문으로 배열 출력 cout << numbers[i] << ", "; } cout << endl; for (auto &value : numbers) { // 범위 기반 for 문으로 배열 출력 cout << value << ", "; } cout << endl; return 0; }
- 범위 기반 for문 활용
- 데이터 집합 원소 복사:
for (auto변수 이름: 배열/ 컨테이너) {}
=> 데이터 집합을 순회하면서 변수에 값이 차례로 복사- 데이터 집합 원소 참조:
for (auto&변수 이름: 배열/ 컨테이너) {}
=> 데이터 집합의 원소를 참조로 접근, 참조 변수이므로 원소값 변경 가능- 데이터 집합 원소 상수 참조:
for (const auto&변수 이름: 배열/ 컨테이너) {}- 데이터 집합 원소 Rvalue 참조:
for (auto&&변수 이름: 배열/ 컨테이너) {}
=> 개별 원소를 저장할 변수를 auto 형식으로 선언하면 형식 연역을 통해 데이터를 안전하게 전달 가능
** Rvalue 참조: 임시로 만들어지거나 특정 범위에서만 존재하는 값, 이름 없는 객체로 선언 범위를 벗어나면 소멸
3) 제어문의 초기화 구문
- 초기화 구문: 제어문에서 사용할 변수를 제어문 바깥에서 초기화할 때 사용 => 제어문에서 조건식 앞에 초기화 구문을 작성하고 ;을 추가하면 분기문에서 사용할 변수의 초기화나 사전에 필요한 조치들이 어떤 것인지 명확하게 알 수 있음
4) 람다 표현식
- 람다 표현식: = 클로저
함수를 단순하게 만들고 로직을 이해하기 쉽게 만들어줌
작성된 범위에서 실행되어 부수적인 코드 불필요람다 표현식에서 선언부의 변수를 사용하기 위한 방법을 캡처라고 함[&changes] (int payment, int price) mutable throw() -> int { // 외부 변수 캡처, 매개변수 목록, 복사 캡처 여부, 예외처리, 반환 형식 int change = payment- price; changes[0]= change/1000; change %=1000; return payment-price; // 정의부 } (payments[i], price[i]) // 호출부
모든 선언부의 변수를 참조 형식으로 사용하려면 &을, 읽기 전용으로 사용하려면 = 기호를 사용
- 새로운 구문 (2)
1) 폴드 표현식
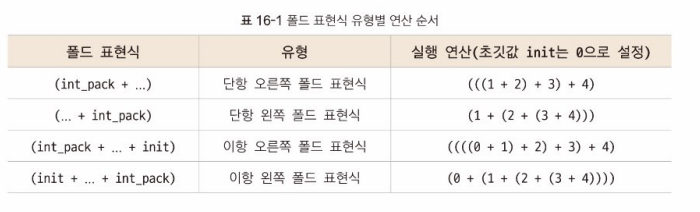
- 폴드 표현식: 개수가 정해지지 않은 매개변수를 하나로 묶은 매개변수 팩을 반복해 계산
가변인수 템플릿의 재귀호출을 함수 하나로 간단하게 표현할 수 있는 방법
- 매개변수 팩: 데이터 형식과 개수가 모두 정해지지 않은 템플릿 매개변수들을 하나로 묶어줌
매개변수 팩을 처리하려면 재귀함수와 마지막 매개변수를 처리할 말단 함수를 정의해야 하는데, 이때 두 함수의 이름은 같아야 함
- 폴드 표현식: 매개변수 팩을 쉽게 사용할 수 있도록 도와줌
(매개변수 팩 이름 연산자 ...)형태로, 프로그래밍이 실행되면 매개변수 팩의 원소를 펼쳐서 지정된 연산을 차례로 수행함- 단항: 매개변수 팩 한가지로만 폴드 표현식을 사용
- 이항: 매개변수 팩과 초깃값 두가지로 폴드 표현식 사용
2) 3방향 비교 연산자
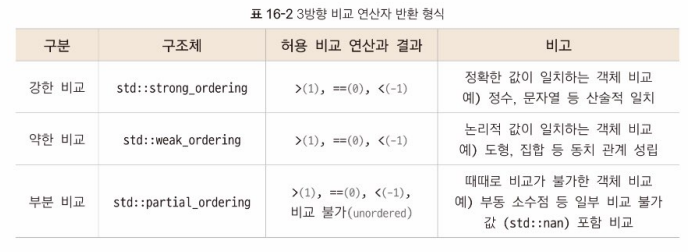
- 3방향 비교 연산자: 객체를 비교하는 과정을 단순하게 해주는 연산자
비교연산자 (>, <, ==, >=, <=, !=)를 모두 오버로딩할 필요 없이 <=>를 사용해 모든 연산자를 대신 오버로딩
compare헤더를 포함해야 사용 가능
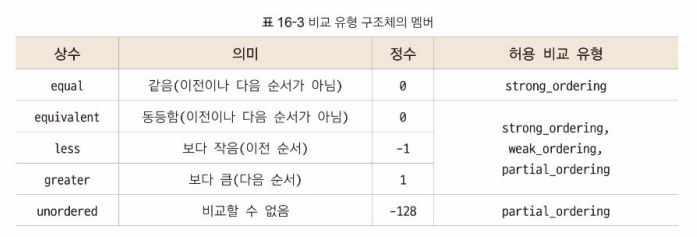
실제 반환하는 데이터 형식은 구조체에 정의된 멤버 상수
(허용 비교 유형: 해당 상수를 허용하는 구조체)
=> 3방향 비교 연산자는 비교 결과를 사전에 정의도니 구조체의 멤버상수로 반환한다. 정확한 값이 일치하는 객체를 비교한 결과는 strong_order로 반환되며, less/ greater/ equal/ equivalent 값을 가진다.
비교가 불가능한 객체는 partial_order로 반환되며 해당 구조체에 비교할 수 없음을 나타내는 unordered 멤버 상수가 반환됨
3) using 키워드
- using의 활용
- 상속 멤버의 접근 지정자 변경: 자식 클래스에서 부모 클래스의 멤버를 using으로 선언하면 접근 범위가 변경되고 부모 클래스에서 접근 지정자는 무시됨 (protected로 지정된 멤버를 using으로 변경 가능)
- 열거형 사용 선언: 열거형 선언을 구조체나 클래스 내부에 있는 데이터 형식처럼 사용하려면 해당 클래스나 구조체에서 using키워드로 선언
= 구조체나 클래스에서 using을 사용해 외부에 선언된 열거형 데이터를 내부에 선언된 열거형처럼 사용 가능
=> 열거형과 구조체, 클래스 간 관계를 논리적으로 만들 수 있음- 별칭 만들기: 별칭이 지칭하는 함수 등에 템플릿을 포함할 경우 using만 사용할 수 있음, using다음 바로 별칭이 나오기 때문에 가독성 좋음
using 별칭 = 식별자로 별칭 제작 가능
4) 함수 키워드
- default: 컴파일러가 제공하는 기본 함수를 사용할 것임을 명시 = 컴파일러가 자동으로 만들어주는 매개변수 없는 기본 생성자를 사용할 것이라고 알려줌
사용시 생성자의 경우 매개변수가 없는 기본 생성자가 호출되고, 연산자는 오버로딩되지 않은 기본 연산자가 호출됨
- delete: 더이상 사용하지 않는 함수에 붙이는 키워드로, 함수가 더이상 사용되지 않고 삭제되었음을 알려줌
함수가 존재하지 않을 때와 delete를 사용했을 때 오류가 다르게 표기됨
함수의 시그니처나 이름을 변경할 때 기존 함수에 delete를 붙이면 변경 전 함수를 사용하던 개발자가 컴파일오류를 통해 사용중인 함수가 제거되었음을 알 수 있음
- override: 가상 함수를 상속받았음을 명확하게 알려줌
(오버라이딩인지 아닌지 컴파일러가 판단하는 기준 제시)
+)오버라이드로 재정의한 함수의 선언부 가장 마지막에 적어 사용
- final: 특정 시점에 가상함수의 재정의나 클래스, 구조체의 상속을 막기 위해 사용. final이 추가된 가상함수나 클래스는 더이상 상속할 수 없음
=> 제공자의 의도와 다르게 가상 함수가 변경되는 것을 막을 수 있음 (일반 함수에는 사용 불가, 클래스나 가상 함수에만 사용)
+)오버라이드로 재정의한 함수의 선언부 가장 마지막에 적어 사용
