- STL의 컨테이너와 알고리즘
- STL= standard template library (표준 템플릿 라이브러리)
1) 컨테이너와 반복자
- 컨테이너: 같은 타입의 여러 객체를 저장할 수 있는 묶음 단위의 데이터 구조. 데이터를 저장하고 관리하며 저장된 원소에 접근할 수 있는 멤버 함수를 제공 한 가지 타입의 객체들만 보관 가능
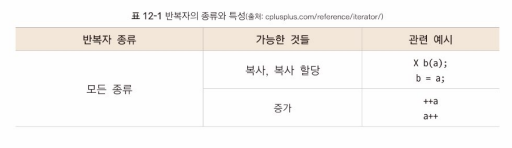
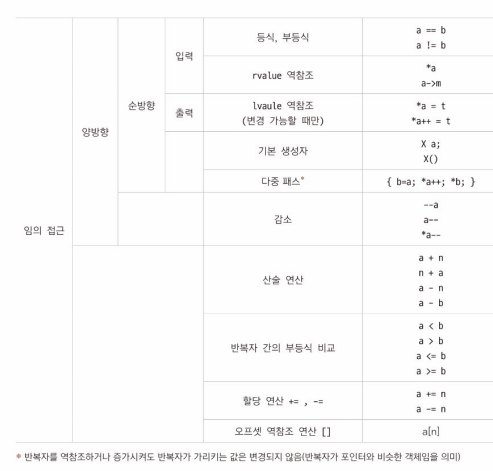
- 반복자: 컨테이너 내부 원소들을 순회하는 객체 (포인터와 유사)
컨테이너에 저장된 원소에 효과적으로 접근 가능
컨테이너의 내부 정보를 외부에 노출시키지 않고도 원소에 접근할 수 있다는 장점
뒤로 이동 불가능하거나 무한한 개수의 원소를 가진 컨테이너에는 사용 불가
- begin: 공통의 멤버 함수로, 위치 반환
begin 함수가 반환하는 반복자에 *를 이용하면 해당 원소에 접근 가능- end: 공통의 멤버 함수로, 컨테이너에 저장된 맨 마지막 원소의 바로 다음 위치 반환
- 컨테이너가 빈 상태라면 begin과 end는 같은 위치 가리킴
- STL에서 모든 컨테이너는 자신만의 반복자를 제공하는데, 컨테이너의 특성에 따라 각각의 반복자가 사용할 수 있는 연산과 함수가 다름
- 순차 컨테이너: 데이터가 순서대로 삽입
- 원소들이 선형으로 배열, 각 원소는 인덱스로 접근 가능
- 원소를 추가/ 삭제하는 일이 빈번하면 list나 deque를, 원소에 빠르게 접근해야 할 땐 vector나 array를 사용
- array: 고정된 크기의 배열을 담는 컨테이너로, 동적 배열의 메모리 할당/ 해제 문제에서 자유롭지만 배열 변수가 포인터로 변환되었을 때 배열 길이를 알 수 없다는 문제가 존재
<array>헤더에 정의(이때 지정하는 원소의 데이터 형식은 기본 외에 개발자가 직접 만든 클래스도 가능)#include <array> using namespace std; array<데이터 형식, 크기> 객체 이름;
초기화는 일반 배열과 같은 방법으로일반 배열처럼 [ ]을 이용해 원소에 접근 가능array <int, 5> myArray {1, 2, 3, 4, 5}; myArray= {1, 2, 3, 4, 5, 6}; // 크기와 값 개수가 달라 오류
at함수를 사용해 인덱스를 전달하면 안전하게 접근 가능array <int, 5> myArray {1, 2, 3, 4, 5}; myArray.at(10)= 0; // 예외 발생 (std::out_of_code)size함수를 사용하면 배열의 크기를 알 수 있음 (메모리 크기 X)array <int, 5> myArray {1, 2, 3, 4, 5}; cout <<myArray.size() <<endl; 5
- vector: 동적인 길이의 배열 컨테이너로, 임의의 위치에 저장된 원소에 빠르게 접근할 수 있고 동적 배열 관리를 안전하게 수행한다는 장점 존재
<vector>헤더에 정의#include <vector> using namespace std; vector<데이터 형식> 객체 이름; vector<데이터 형식> 객체 이름 (크기); vector<데이터 형식> 객체 이름 (크기, 초깃값); vector<데이터 형식> 객체 이름 = {값1, 값2, ...}; //유니폼 초기화일반 배열처럼 [ ]로 접근 가능,
at함수 사용 가능
push_back이라는 멤버함수로 벡터의 끝에 원소 계속 추가 가능
(단, 배열의 임의의 위치에 원소를 추가하거나 제거하는 것은 매우 느리며, 기존에 할당된 공간이 다 차서 더 큰 새로운 공간으로 이동할 때는 원소를 복사해야해 시간이 오래걸림)
insert/ erase: 중간에 새로운 원소 추가/ 제거vec.insert(vec.begin() +3, 25); // vec[3] 앞에 25 추가 vec.erase(vec.begin() +3) // vec[3] 제거 (제거 후 모든 원소 한칸씩 당겨져 저장)=>
insert는 한칸씩 뒤로 밀려 저장,erase는 한칸씩 당겨져 저장
- 함수 템플릿 사용하기
STL에서 제공하는 컨테이너는 모두 클래스 템플릿 형태로, 특정 타입의 객체를 저장할 수 있는 전용 컨테이너 선언 가능, (ex) 같은 vector 컨테이너라도 데이터 형식을 다르게 선언 가능) 직접 만든 구조체나 클래스 형식의 데이터도 저장 가능
- 다양한 형식의 벡터 컨테이너를 하나의 함수로 처리하고 싶다면 함수 템플릿을 이용하면 됨
=> 템플릿 매개변수 (T)를 이용해 다양한 형식을 전달받아 처리 가능template <typename T> void print_vector (vector<T> &vec)
- 값을 변경할 수 없는 정적 반복자
const iterator: 정적 포인터처럼 기능해 반복자가 가리키는 원소값을 변경할 수 없음,cbegin과cend함수로 얻을 수 있음
- 거꾸로 동작하는 리버스 반복자
: 벡터의 뒤부터 앞으로 움직임
for (vector<int>::reverse_iterator it= vec.rbegin(); it != vec.rend(); it++)
- list: 연결리스트, 데이터가 노드라 불리는 개별 객체로 구성
각 노드는 다음 노드를 가리키는 포인터를 포함 => 데이터를 삽입하고 삭제하는데 효율적이며, 순서 유지 가능
<list>헤더에 정의
push_front,push_back,pop_front,pop_back,size,empty사용 가능
이중 연결 리스트로 구현되어 각 원소에는 다음/ 이전 원소 가리키는 포인터가 존재
벡터는 임의 접근이 가능하며 원소를 상수시간에 접근할 수 있지만 리스트는 임의 접근이 불가능하며, 원소에 접근하려면 이전 원소를 차례로 따라가야 함
=> 벡터는 원소에 자주 접근하고 수정해야할 때, 리스트는 삽입과 삭제가 빈번할 때 유용
- deque: 여러개의 메모리 블록을 나눠서 저장, 저장할 공간이 부족하면 일정한 크기의 새로운 메모리 블록을 만들어서 연결=> 벡터에서 발생하는 복사저장이 일어나지 않음: 벡터의 단점을 보완하는 컨테이너
<deque>헤더에 정의
메모리의 재할당이 자주 발생하지 않음
데이터를 양쪽 끝에서 효율적으로 추가/ 제거할 수 있으며 중간 부분에서도 상수 시간에 원소를 삽입/ 삭제할 수 있음
push_front,push_back,pop_front,pop_back,size,empty,back,front사용 가능
- 연관 컨테이너: 데이터가 오름차/ 내림차순처럼 이미 정의된 순서로 삽입 (언제나 정렬된 상태 유지): 데이터를 저장하고 검색할 때 사용
- set: 고유한 값을 정렬된 순서로 저장
<set>헤더에 정의,
std::set <데이터형식> 객체 이름;으로 선언
erase,clear,insert,find,count,begin,end사용 가능
연관 컨테이너에 속하지만 이진 탐색 트리를 사용해 원소를 저장하고 정렬된 순서를 유지하기 때문에 정렬 컨테이너이기도 함
원소 삽입시 자동 정렬 (오름차순 기본), 클래스나 구조체의 원소 저장시 해당 형식에 오버로딩된 비교 연산자에 따라 정렬순서 결정
=> 데이터를 항상 정렬된 상태로 유지해 검색을 효율적으로 할 수 있음
- multiset: 기본적으로 set와 같지만 중복된 값 저장 가능
<set>헤더에 정의,
std::multiset <데이터 형식> 객체 이름;으로 선언
+)erase함수 사용할 때 중복값이 있다면 모두 제거
- map: 키-값 쌍으로 저장
<map>헤더에 정의
std:: map <std:: 키 형식, 값 형식> 객체 이름;으로 선언
각 키는 고유해야하며, 키를 기준으로 정렬된 순서로 저장
특정 키에 연관된 값 검색하고 값을 추가, 제거, 수정할 때 사용
키-값 쌍 관리시에도 유용
- 키-값 쌍 삽입시
insert함수 이용, 키와 값 묶어std::pair객체로 만들어주는std::make_pair함수 사용 가능 (데이터 형식 지정 필요없음)
(ex)scores.insert(std::make_pair ("Bob", 85));)
find,erase등 사용 가능
- multimap: 기본적으로 map과 같지만 중복된 값 저장 가능
- 중복된 키 저장 가능
- 자동정렬 (기본 오름차순, 정렬기준 정의 가능)
- 이진 탐색 트리: 검색, 삽입, 삭제 효율적 수행 가능
=> 같은 키로 여러 값 관리해야하는 다중 매핑이나 정렬된 키-값 쌍을 유지해야할 때 활용 가능
equal_range함수로 특정 키를 가진 원소의 범위 구하기 가능 (범위는 (first, last)형태의 반복자 쌍으로 표현됨 (둘 다 반복자))
auto range = scores.equal_range ("Bob");= 키에 해당하는 원소의 범위 구하기
+) set는 고유한 원소들을 정렬된 상태로 유지해야 할 때,
map은 키-값 쌍을 저장하고 고유한 키를 기준으로 정렬된 상태를 유지해야할 때 사용
- 컨테이너 어댑터: 다른 컨테이너를 기반으로 새로운 기능을 제공하는 컨테이너, 특별한 자료구조 표현
- stack: 자료구조 구현시 사용, Last In First Out (LIFO)
데이터를 임시로 저장하거나 역순으로 처리할 때 이용
<stack>헤더에 정의,
std:: stack <데이터 형식> 객체 이름;으로 선언
데이터를 넣을 땐push를 사용해 맨 위에 쌓고,
데이터를 꺼낼 땐pop을 사용해 맨 위의 데이터 제거
(맨 위의 값:top으로 확인 가능)
- 스택에서의 주요 기능
: 함수 호출 관리, 데이터 임시 저장, 역순 처리, 재귀 알고리즘, 컴퓨터 아키텍쳐, 컴파일러와 언어 구현
- queue: 자료구조 구현시 사용, First In First Out (FIFO)
선입 선출의 특성으로 데이터의 순서를 보장하고 먼저 들어온 데이터가 먼저 처리되어야 할 때 유용
<queue>헤더에 정의,
std:: queue <데이터 형식> 객체 이름;으로 선언
데이터를 넣을 땐push를 사용해 맨 아래에 쌓고,
데이터를 꺼낼 땐pop을 사용해 맨 위의 데이터 제거
- 큐에서의 주요 기능
: 작업 대기열, 이벤트 처리, 멀티스레딩 환경에서 동기화, 너비 우선 탐색, 캐시 구현
2) 알고리즘
- 정렬: 컨테이너에 저장된 원소들을 기준에 따라 차례대로 재배열하는 것
처리 속도를 올리기 위해서, 데이터를 저장하고 저장된 데이터를 빨리 찾기 위해서
- 퀵 정렬:
sort함수 이용
<algorithm>헤더에 정의되어있으며,sort함수는 매개변수로 전달받은 first부터 last 이전까지 모든 원소를 오름차순으로 정렬
단, array나 vector처럼 임의 접근 반복자를 지원하는 컨테이너만을 대상으로 사용할 수 있으며, list처럼 원소에 차례로 접근해야하는 컨테이너에는 사용할 수 없음
/정렬순서를 지정하고 싶을 땐 오버로딩된sort함수를 호출하며 세번째 매개변수로 정렬 순서를 지정하는 비교함수나 함수 객체를 전달 (비교함수는 2개의 값을 받아 첫번째 값과 두번째 값을 비교한 후 true나 false를 반환하도록 만들면 됨)
- 안정 정렬 (stable_sort): 같은 원소가 정렬 후에도 원본의 순서와 일치,
stable_sort함수 이용, 사용법은sort함수와 같음
- 부분 정렬: 컨테이너의 모든 원소가 아닌 일정 구간만 정렬
partial_sort함수 사용,<algorithm>헤더에 정의
partial_sort (first, middle, last)형식으로 사용
first: 정렬 시작할 범위
middle: 정렬 원하는 범위 끝 (정렬 후에 이 반복자가 가리키는 이후의 원소들은 순서가 보장되지 않음)
last: 정렬 종료할 범위의 끝
=> first 부터 middle 이전까지 정렬된 이후 middle부터 last까지 원소들은 정렬되지 않음
- 찾기와 이진탐색
find: 순차 컨테이너에서 원하는 값 찾는 함수, 선형검색 기반<algorithm>헤더에 정의, first부터 last까지의 범위에서 value와 일치하는 첫번째 원소를 가리키는 반복자를 반환 (찾지 못하면 last반환)
찾고자하는 값과 컨테이너 내의 두 값이 같은지 판단할 때는 operate== 사용 (사용자 정의 타입의 객체 비교하려면 해당 객체에 == 연산자 오버로딩)distance: 두 반복자 사이의 거리 (원소 개수) 계산
first부터 last까지 원소개수를 반환binary_search: 이진탐색으로 특정 값 찾기
<algorithm>헤더에 정의, first부터 last까지의 범위에서 value가 있는지 이진탐색으로 확인 => 컨테이너를 정렬한 뒤 사용
기본적으로find와 매개변수 구성, 사용법 같음
- 모던 C++에 추가된 기능
1) C++ 버전별 주요 특징
- C++ 03 주요 변경 사항
- STL이 표준 라이브러리로 편입
- C++11/ 14 주요 변경 사항
- 범위기반 for문
- 람다 표현식: 소스코드 간결, 함수 흐름 파악 쉽게 도와줌
- override, final 키워드 사용
- 스마트 포인터: 메모리 자동 관리
- 튜플기능 구현
- C++ 17 주요 변경 사항
- 파일 시스템 라이브러리
- 병렬 처리 라이브러리
- if문, switch문 초기화
- 폴드 표현식: 매개변수 팩으로 입력받은 값을 반복해서 처리할 때 재귀함수를 사용하지 않고 처리
- 구조적 바인딩
- C++ 20 주요 변경 사항
- 컨셉: 함수 템플릿 매개변수의 종류나 속성에 대한 제약 명시
- 코루틴: 함수를 멈췄다가 다시 호출할 수 있는 루틴 (함수를 한꺼번에 실행하지 않고 루틴을 조절해가며 필요한 기능을 그때그때 실행. 코루틴이 종료되기 전까지 지역변수가 유지되어 전역변수를 사용하지 않아도 여러 호출부에서 값 공유 가능)
- 모듈
- 3방향 비교 연산자
- 수학 상수 (e, pi, 루트, ln 등)
- C++ 23 주요 변경 사항
- 연역 this 포인터: 클래스나 구조체의 멤버에 접근해 값을 변경할 수 없게 하거나 제약사항을 추가하고 싶을 때 사용
- 가변 인자 출력 print: cout사용하지 않고도 출력 가능
2) 현대적 관점의 C++
- char* 대신 string 사용
- [ ]array 대신 vector < >사용
- 포인터 대신 레퍼런스 사용
- 메모리 직접 관리 대신 RAII 사용
