본 Velog는 Stanford CS231n 강의와 강의자료를 통해 공부하고 정리를 한 내용입니다.
Stanford University CS231n
Lecture 1 : Introduction to Convolutional Neural Networks for Visual_Recognition
Professor : Fei, Fei
Computer Vision
- 이 강의에서의 CS231n은 Computer vision에 관한것이라고 볼 수 있음
Computer Vision : Study of Visual Data
- Visual Data 는 지난 몇년간 엄청난 속도로 증가하고 있음
Ex) Censor의 기하급수적인 증가로 엄청난 양의 시각적 데이터가 생산 중
Ex) 2015년 CISCO는 2017년의 데이터중 80퍼센트가 비디오가 될 것이라고 예측함
: 따라서 대부분의 인터넷의 비트 데이터는 시각데이터로 이 시각데이터를 활용하는게 중요함
Ex) Youtube 통계 자료에 따르면 1초에 5시간씩 동영상이 업로드 됨
: 직원이 모든 동영상을 분류하고 광고를 넣는 것을 불가능 -> 분류화하고 알맞은 광고를 추가하는 것이 필수적
하지만 분석을 하는데에는 문제점이 있음. 우주의 대부분이지만 암흑 물질에 대해서 제대로 분석하기 힘든것처럼알고리즘이 데이터를 이해하고 정확히 구성하고 있는것이 무엇인지 파악하기 힘듦
- Computer Vision은 다양한 학문의 지식에 영향을 받음
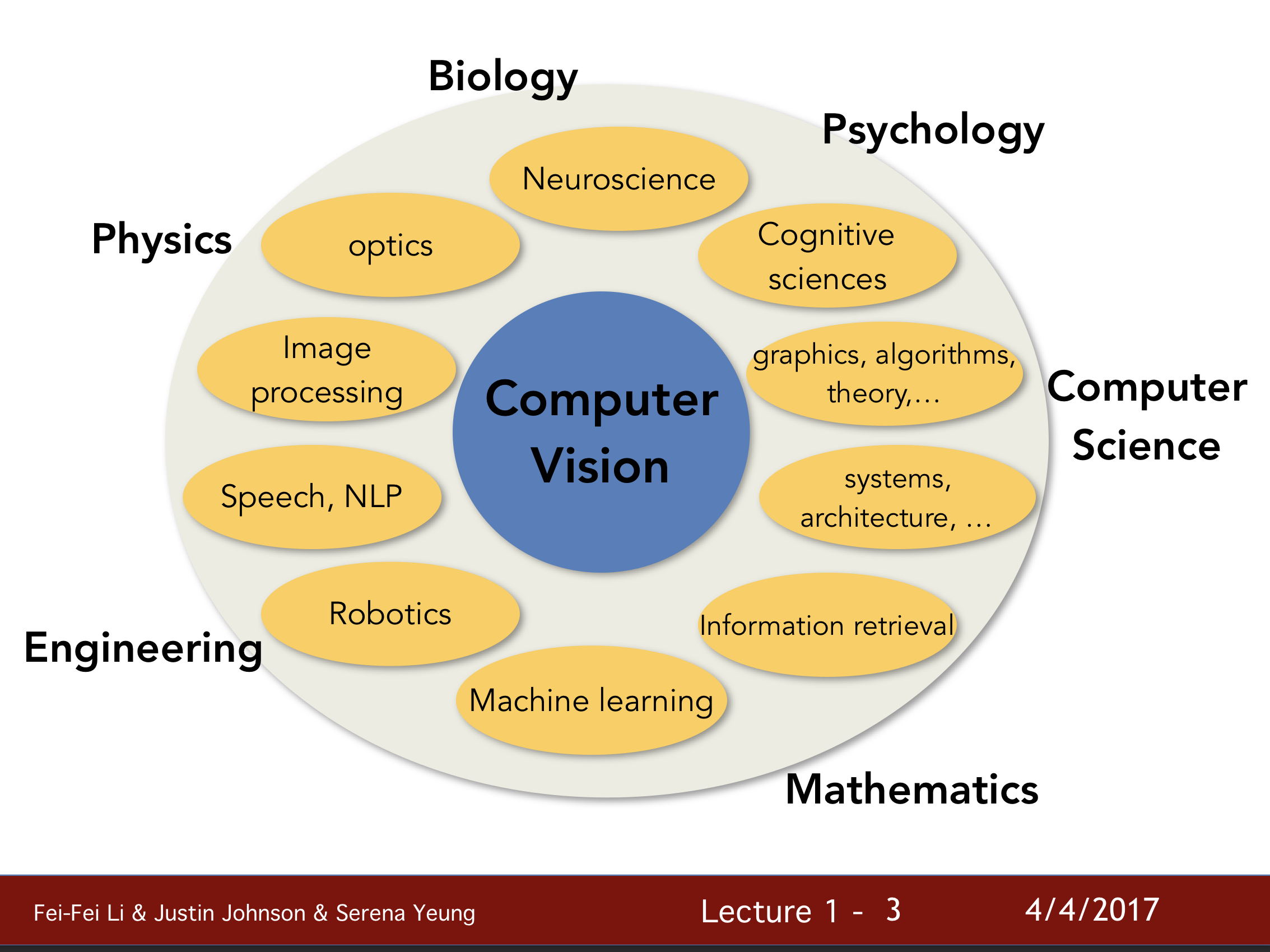
CS231n
CS231n의 강의 목적 : Algorithms of Neural Network( Especially Convolution Neaural Network ), Applications on Various Visual Recognitions on Tasks, Seminar
History Of Computer Vision
Professor Fei, Fei
- 발전과정을 아는 것이 앞으로 어떻게 발전을 할것인지에 대한 기초체력이 되기때문에 숙지 할 것
A brief history of computer vision
-
Vsion where, when it did started?
- 5억 4300만년전 부터 시작되었음. 동물들은 발전하지 못했고, 그저 돌아다니다 그저 음식을 먹기만 했음. 1000만사이에 몇 종에서 수십만종의 동물들이 탄생했음. 생물학자들은 진화론의 빅뱅이라고 불리고 어려운 문제였음. Andrew Parker이 내놓은 가설은눈이 발달되면서 종분화 단계가 만들어지고 훨씬 더 능동적으로 변함. 포식자들은 더 먹이를 잘 사냥하기 위해, 몇몇은 포식자들로부터 도망가기 위해 생존을 위해서 진화를 하는데 시각이 가장 큰 역할을 하였다고 말함.
-
Vision Now?
- 현재 Vision(시각)은 생존하고, 움직이고, 조작할 수 있게 하는 일을 하고, 먹고, 의사 소통, 즐기는 것들에 대해 핵심적인 기능을 하는 기관으로 발달되어있다. 뉴런의 50퍼센트는 이와 관련된 일을 하도록 되어있다. 특히 지능이 뛰어난 동물들은 이 기관이 중요하게 되었음
-
Camera
- 초기 Camera obscura는 핀홀 카메라 이론에 기초한 카메라. 동물과 초기 눈과 유사함
-
Study of the Animal Vision
- 사람들은 시각에대해서 연구를 시작함, 그 중 Hubel / Wisel의 연구결과가 computer sicence그리고 생명의 Vision연구에 큰 영향을 끼침
- Hubel / Wisel : 사람들의 시각을 연구하기 위해 인간의 뇌와 비슷한 고양이 뇌에 일차 시각 피질을 붙이고 뉴런에 어떤 자극을 줘서 작동하게 하는가 파악하려고 함. 특정 방향으로 움직일때는 간단한 세포가 사용되는 것을 보는 등 뉴런에 대해서 연구를 하게 되었음. 그들이 시각 처리에 알아냈던 내용방향성있는 모서리부터 시작해서 경로를 따라 이동하면서 축적하는 방식으로 인식을 하게 됨.
-
Block World
- Computer Vision을 기하학적으로 단순화 시킨 것.
-
Summer Vision Project
- Goal : Sumer vison Project is an attemp to use our summer workers effectively in the construction of significant part of a visual system => 여름에 visual system에 대한 대부분의 내용을 해결하는 것이 그들의 목표였음 .
하지만 여전히 Computer Science에서도 그것에 관해서 연구를 계속해서 진행중임
그런 중에도 인공지능에 많은 사람들이 연구를 했으며, 이 연구 분야를 꽃 피웠음
- Goal : Sumer vison Project is an attemp to use our summer workers effectively in the construction of significant part of a visual system => 여름에 visual system에 대한 대부분의 내용을 해결하는 것이 그들의 목표였음 .
-
Davic Marr
- 1970년대, MIT VISION SCIENCTIST, 자신이 생각하는 비전과 어떻게 연구해야되는지 저술함 . 이미지를 찍고 최종적으로 3d에 찍는 것이 목표인데, Primary Sketch부터 시작해야했음. 많은 신경학자들에게 영감을 주었음.
Primary Sketch : 직선, 곡선, 가장자기, 경계가 표현되는 곳, 가장 단순한 선부터 표현하는 스케치
- 1970년대, MIT VISION SCIENCTIST, 자신이 생각하는 비전과 어떻게 연구해야되는지 저술함 . 이미지를 찍고 최종적으로 3d에 찍는 것이 목표인데, Primary Sketch부터 시작해야했음. 많은 신경학자들에게 영감을 주었음.
-
2.5d sketch : 깊이, 표면, 레이어, 불연속성 이런것들을 저장
-
마지막 단계 3d로 넘어가서 계층적으로 정보를 가지고 있는 하나의 데이터가 됨
-
이 방식은 어떻게 시각적인 것들을 분해해서 봐야되는지 원시적인 접근 방법을 알려줌
-
1970년대
- 어떻게 실제 객체를 인식할까? 원통형 모양과 같은 단순한 기하학적 모델 로부터 인식을 한다는 것을 깨달았음
- 1980년
- David Lowe : 직선과 모서리의 조합으로 면도기를 인식함.
1960년~1980년대 계속해서 컴퓨터 비전과 관련된것이 무엇인지 알아내려고 노력했었음, 하지만 현실세계에서 작동할 수 있는 것들을 제공하는 측면에서 많은 것을 제공하지 않았음
- 이미지 분할
- 물체 인식이 어려우면 픽셀을 의미있는 것들로 다시 이미지 분할을 해야함
- 1999~2000년
- 마침내 다양한 그래픽 기술 그리고 기초과학의 발전으로 비약적인 발전을 하기 시작함.
- AdaBoost Algorithm : 얼굴감지가 가능하게 해줌
- Fuji Film : 디지털 카메라를 만들어냄
- 1990년대 ~ 2000년대
- David Lowe: Feature Based Recognition
- Ex) 정지판 같은것들은 각도에 따라서 다르게 보이고, 날씨, 명암등에 영향을 받기 때문에 인식이 힘들었음 => 특징과 패턴을 알아내서 같은것으로 인식할 수 있도록 도와줌
- Spatial Pyramid Matching :
- 이미지의 특징이 어떤 이미지인지 힌트를 줄 수 있다라는 것에서 출발
- 다른 부분에서 특징을 가져와 벡터 머신 알고리즘과 같은 방식으로 파악하기 시작했음
- Histogram of Gradients, Deformable Part Model
- 2000년대 1가지 확실하게 변하고 있는 것은 데이터의 Quality인데 인터넷, 화질 등이 연구를 위한 좋은 데이터를 제공함
- 2000년대 중요한 발전:해결해야할 매우 중요한 빌딩 블록 문제를 정의했다는 것(객체 인식이라는 것을 해결하기 위한 중요한 과제 중 하나임 )
- Pascal Visual Data Set : Bench mark Data set => can measure progress of recognition
- 20가지의 객체 카테고리임(비행기, 강아지 등 ) : 각 객체는 만여개의 이미지로 되어있음
- 인식률을 측정하면서 성능의 발전을 체크하였음
- 모든 물체 혹은 대부분의 물체를 인식할 준비가 되었는가?
- 아직. 과적합, 너무 High Dimension input, 복잡한 이미지 소스들이 있었음
- ImageNet을 구현하기 위해서 1500만 ~ 4000만개의 이미지을 학습하여 22000개의 이미지 카테고리로 된 데이터 셋을 만들었음
- Benchmark 방식 : The Image Classification Challenge를 열어 인식 결과를 테스트 하는 대회를 만들었음. 상위 5개의 레이블을 제출하여 오류를 체크함. 사람의 오류 보다 이제는 보다 정확하게 되었음.
- 2012년 : 드라마틱한 발전이 있었음 ( 10% 감소 )
: Convolutional Neural Network Model
CS231n Overview
- Image Classification Problem 에 집중한 강의임.
알고리즘이 이미지를 보고 범주에서 이미지를 분류하는 것임
다양한 것을 인식하는 곳에 응용됨 .
- Object detection:전체 이미지를 분류하기 보다는, 사진에서 박스를 그려 이 이미지가 어디에 있는지 알려줌.
-
image captionaing: System이 그 이미지를 설명하는 문구를 스스로 생성함
-
CNN( Convolutional Neural Network ) : image recognition 에서 가장 중요한 도구. AlexNet 7 layer, VGG 19 layers, 갈수록 layer가 깊게 내려가고 있음. 이런 Neural Model은 image classification에서 중요하게 사용됨
- 사실 이전에도 Mnist set을 학습할 때도 비슷한 방식으로 처리했었음. 픽셀을 나누고 비슷한 방식으로 처리. 사실상 90년대부터 시작되었다고 봐도 됨
- 그럼 왜 지금에서야 CNN은 폭발적인 인기를 누리게 된 것인가?
- 계산속도의 증가: 빨라진 컴퓨터, 많은 트랜지스터 활용, GPU사용은 계산속도의 증가를 가져옴
- 데이터양의 증가 : Internet의 발전은 데이터양을 엄청나게 발전하게 되는 결과를 가져왔음
여전히 많은 문제를 가지고 있으므로 알고리즘을 지속적으로 발전시키고 도전해나가야함 Ex) 3D 구현, 증강 현실, 0.5초동안 이미지를 보여주고 묘사하기 등
Architecture & Neural Network & 어떻게 학습되는지 등에 대해서 올바르게 알고 있어야함
참고 : 1.[유튜브]Stanford University CS231n - Lecture 1 : : Introduction to Convolutional Neural Networks for Visual Recognition
2. http://cs231n.stanford.edu
