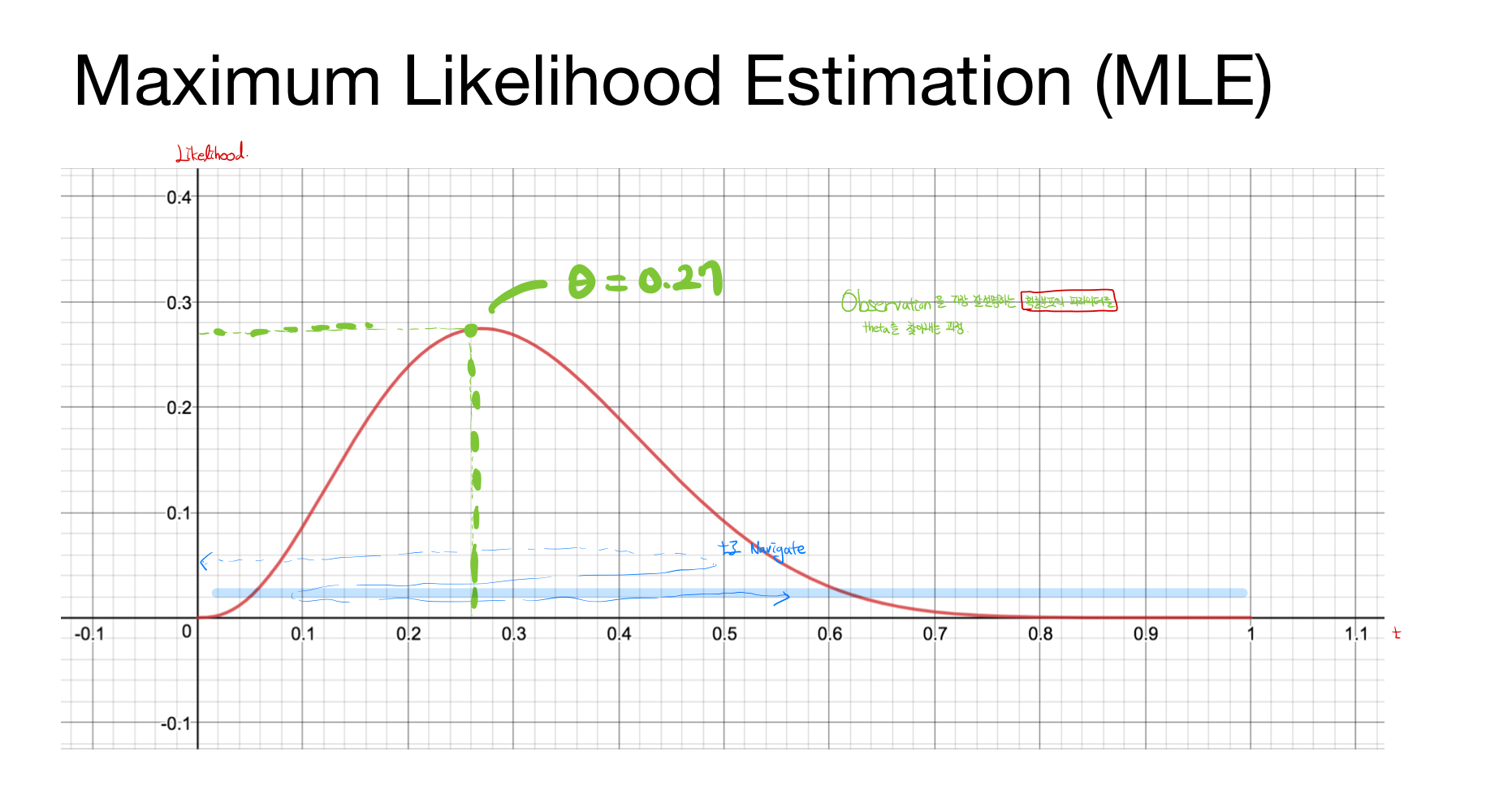
Maximum Likelihood Estimation
Maximum Liklihood Estimation ( MLE ) : 최대가능도 추정이라고 하며, 실제 Observation을 가장 잘 설명하는 파라미터(theta)를 찾아내는 과정을 말함. 즉, 가장 잘 설명하는 파라미터 값을 의미.
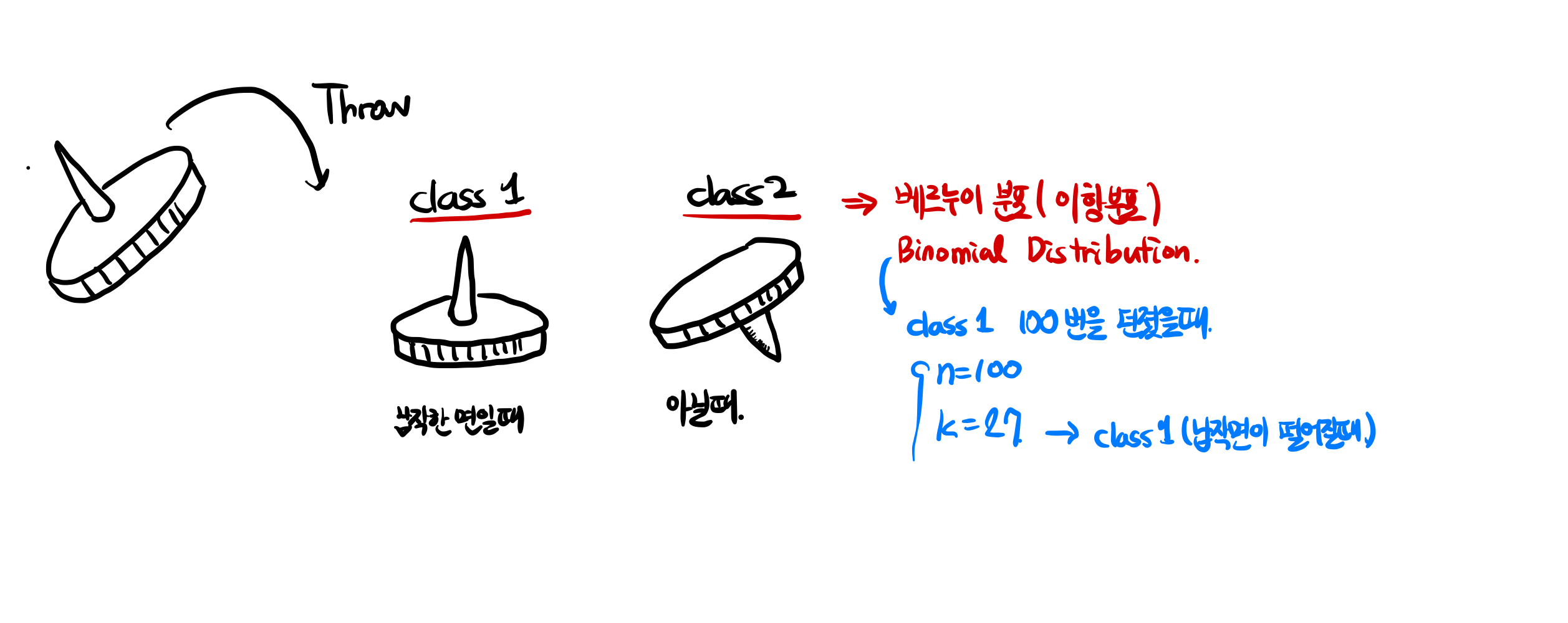
예) 압정이 떨어졌을 때, 뒷면으로 떨어질 경우를 class 1, 이외의 경우 class 2라고 하자. 이 때의 경우, 전체 n번을 던졌다고 가정을 하고, k번 class 1이 나와있다고 하자. 그럼 다음과 같은 확률 함수를 만들어 줄 수 있고, 이 때의 theta값(파라미터)를 구함으로서 최대 가능도를 구해 줄 수 있다.

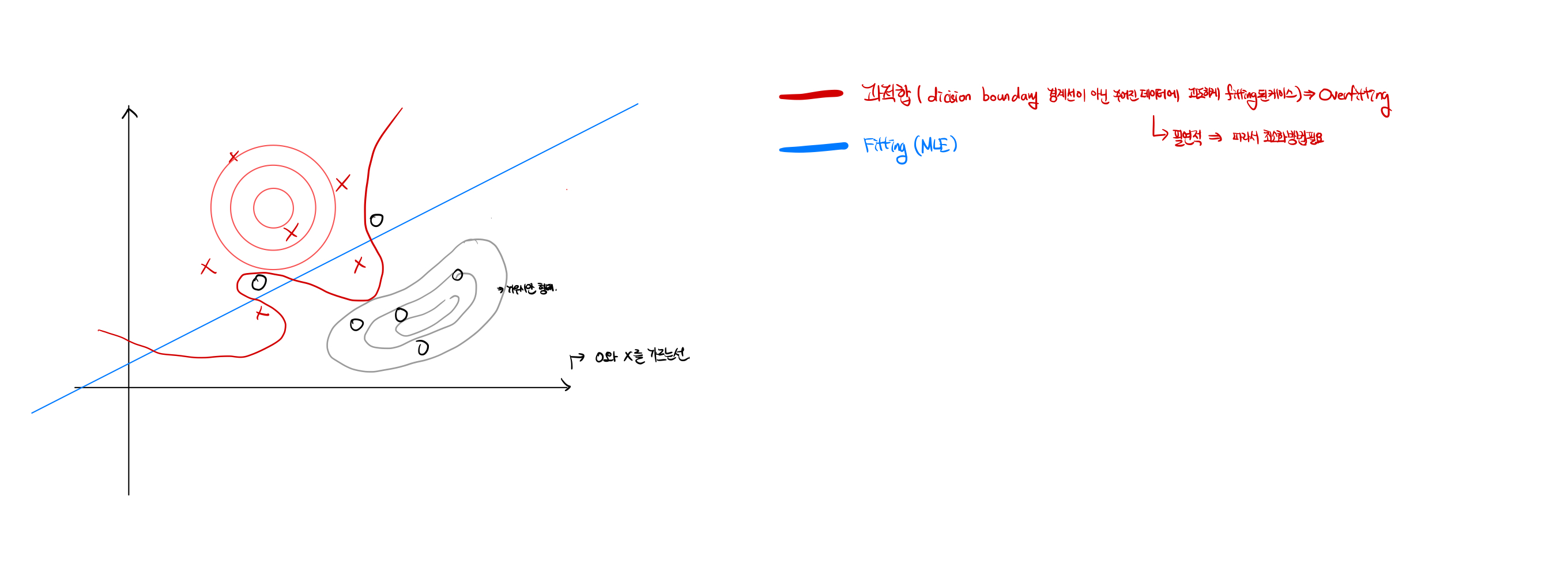
Overfitting
Overfitting: 과적합이라고 하며, 주어진 데이터에 과도하게 fitting된 또는 학습된 케이스를 의미한다. 대부분의 경우에서 필연적으로 일어나며, 이런 Overfitting을 최소화할 수 있는 방법이 필요하다.
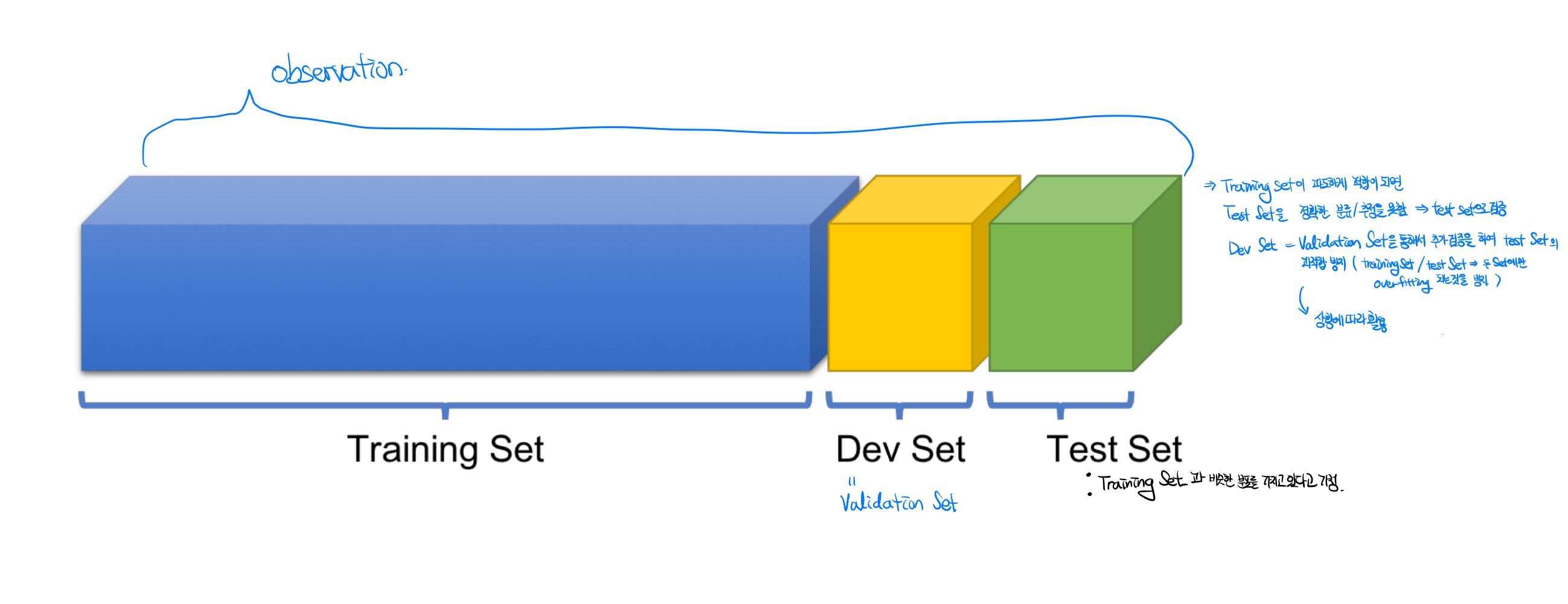
보통 데이터를 학습할때 다음과 같이 세가지로 분류하여 데이터 셋을 학습하고, 검증하는 과정을 거친다. 이 때의 데이터 셋은 비슷한 데이터 분포를 갖고 있다고 가정한다.
- Training Data : 기존 데이터셋의 80퍼센트를 할당하며, 과적합이 된경우 주로, 많은 epoch수를 통해 이 training data set에 과적합되어, test data나 Development Data를 통해 검증을 할 경우 전혀 추정 또는 분류 등을 할 수 없게 된다.
- Development Data(Validation Data) :기존 데이터 셋의 0~10퍼센트의 부분을 추출한 데이터 셋이다. test나 train 데이터 셋에 과적합이 될 경우, 사용하여 과적합을 방지해주는 데이터 셋이다.
- Test Data : 기존 데이터의 10~20퍼센트의 데이터셋을 추출한 데이터 셋으로, train set이 적절하게 적합이 됬는지 확인해주는 데이터 셋이다.
아래와 같이, train data set은 epoch이 증가될 수록 적합이 일어나지만, validation set을 보면 특정 시점을 기점으로 손실함수 값이 증가함을 확인 할 수 있다. 이 경우 overfitting이고, 이렇게 함수를 통해 구분해줄 수 있다.
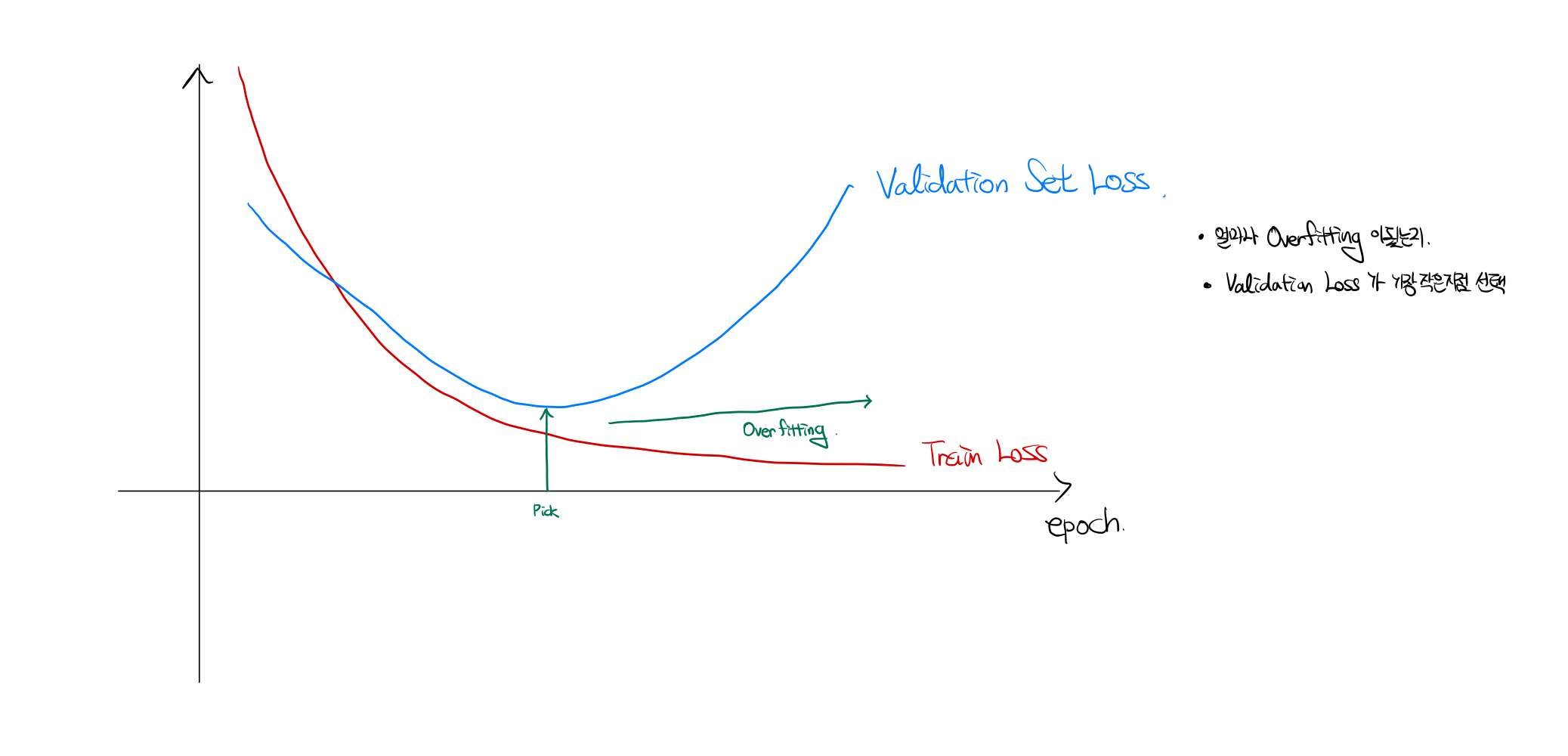
- Overfitting을 방지하는 방법
- 데이터 늘리기 : 편향된 데이터를 줄일 수 있다.
- 적은 특성 : 적은 데이터의 특성 값을 만들어준다.
- 정규화 : 데이터의 특성 및 편향된 데이터를 줄여준다.
번외: fitting을 높이는 방법( feat. Learning Rate)
Learning rate 값이 너무 클경우, 손실 함수의 값이 발산 할 수 있으며, 작은 경우 손실 함수의 값이 적당한 값을 찾아가는데 너무 오랜시간이 걸림. 적당한 Learning rate을 찾는 것이 중요.
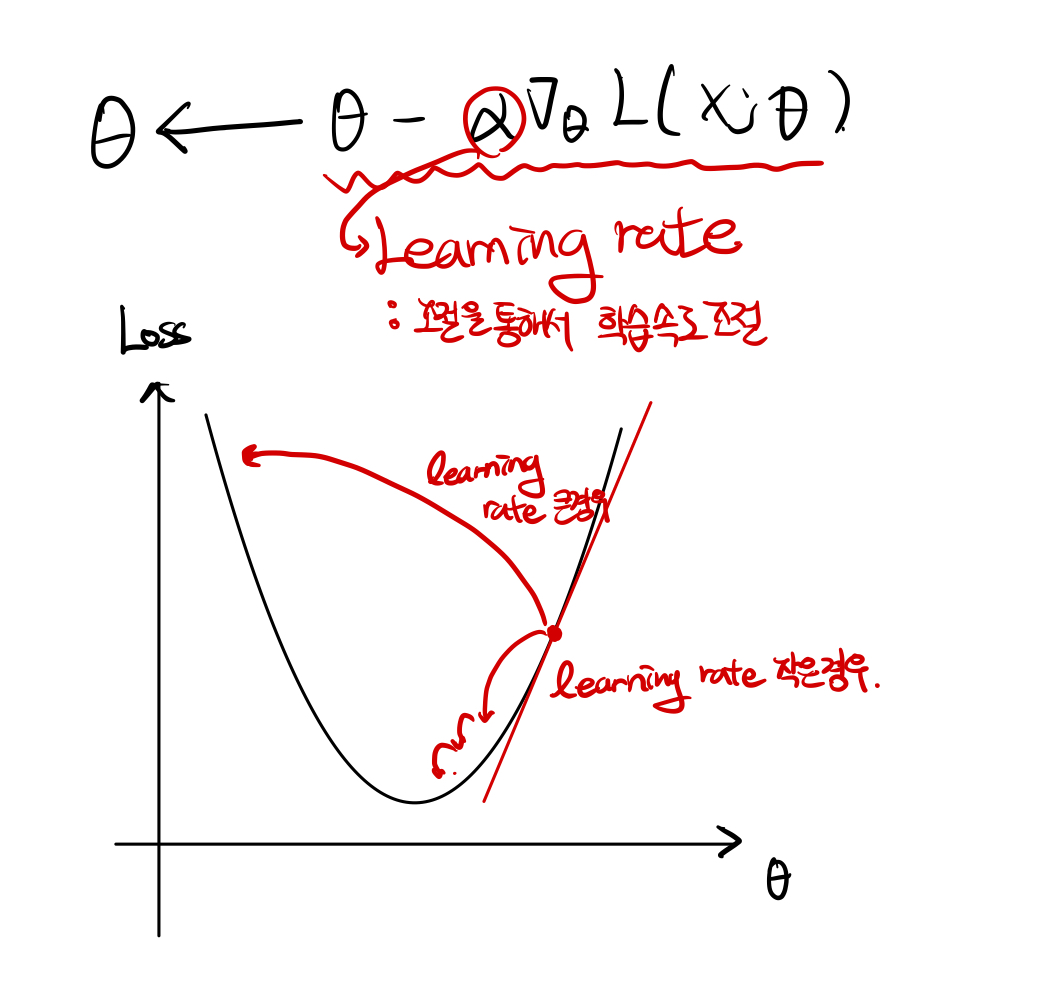
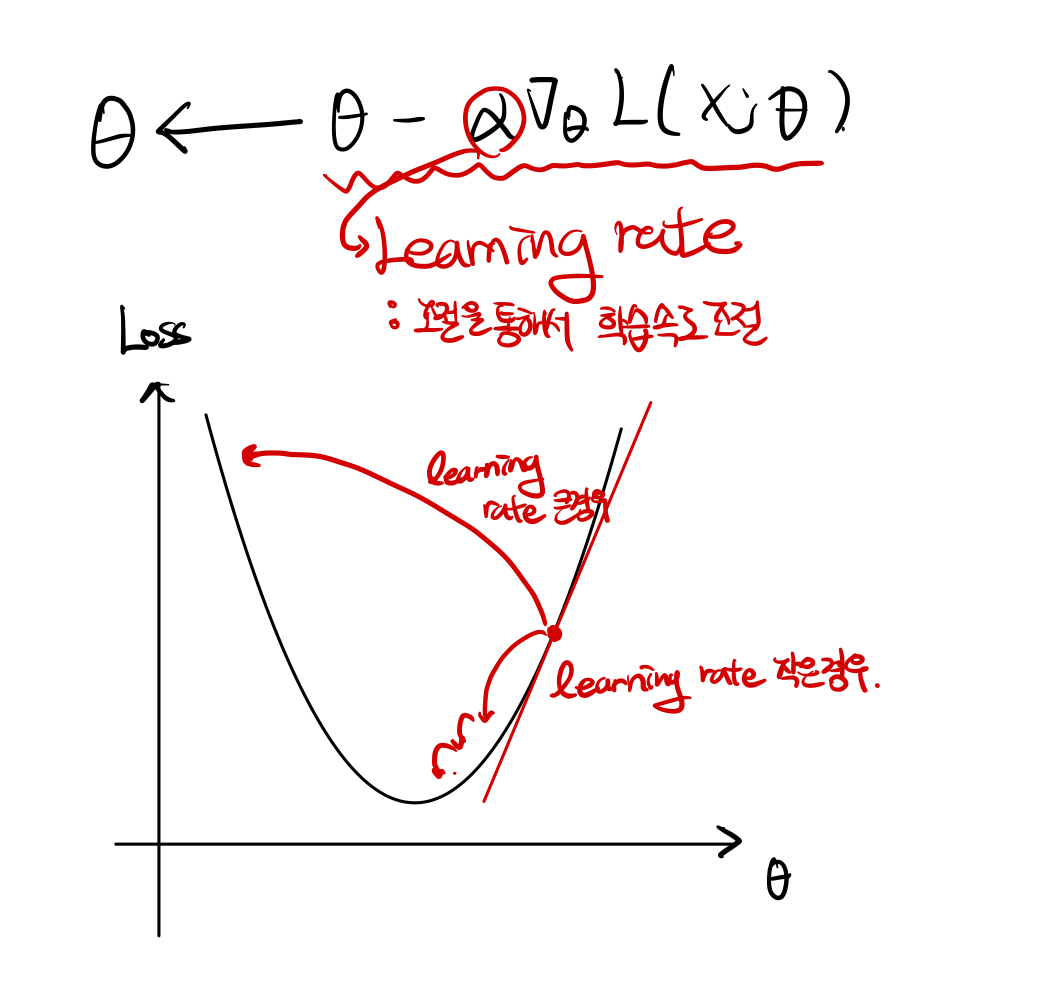
Regularization
- Early Stopping : Validation Loss 가 더이상 낮아지지 않을 때
- Reducing Network Size: Deep learning의 경우, 학습량을 줄임
- Weight Decay : Parameter 크기 줄임
- Drop Out : 필요없는 데이터 삭제
- Batch Normalization : 데이터 처리시 정규화
Data Processing
Data Processing: 데이터 전처리라고 부르며, 주로 데이터를 탐색, 분석을 하여, 데이터의 비중을 비슷하게 맞춰주는 방법을 의미한다. 주로 정규화가 이용된다.
