모두를 위한 Deep Learning- Pytorch
1.AI 딥러닝 시작:: 가상 환경 구현 ( Docker )
딥러닝 입문하기 위해서 Boostcourse 강의에 있는 '파이토치로 시작하는 딥러닝 기초'라는 강의를 수강하게 되었다. Tensorflow는 대학에서, Pytorch는 실무에서 많이 쓰인다는 학회장님의 권유로 pytorch강의를 수강을 하게 되었다. 이 강의는 홍콩
2.Pytorch Basic Tensor Manipulation

딥러닝은 기본적으로 vector, Matrix, Tensor 을 가지고 계산을 하게 된다. 엄밀이 설명하면 설명하면 벡터는 1차원 행렬, Matrix는 이차원 행렬, Tensor는 3차원 행렬을 의미한다. 하지만 벡터, 행렬은 텐서의 한 종류로 같은 연산을 따른다.te
3.선형 회귀( Linear-regression )

Simple Linear regression >선형회귀 : 두 변수의 사이의 관계를 선형 관계로 직선으로 모델링 하는 기법. 여러 데이터 set을 이용해서 y= Wx * b( W= weight, b=Bias의 꼴로 나타낼 수 있도록 데이터를 학습함. 이 함수를 Hy
4.Logistic Regression( 로지스틱 회귀 )
Logistic Regression이란? 일반화된 선형 모델(Generalized Linear Model)의 한 종류로 독립 변수의 선형 결합을 이용하여 사건의 발생 가능성을 예측하는 확률 모델을 의미한다. 로지스틱 회귀 모델 만드는 방법 살펴보기 여러 변수 x의 매
5.Softmax Regression
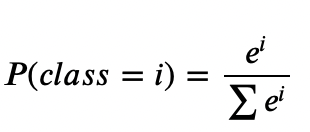
softmax regression이란 : 함수를 통해 분류해야 되는 정답지(클래스)의 총 개수를 k라고 할 때, k차원의 벡터를 입력 받아서, 각 클래스에 대한 확률을 추정하는 회귀방식. Softmax Regression를 활용할 수 있는 상황 _ 1. binary
6.Tips for DeepLearning

Maximum Liklihood Estimation ( MLE ) : 최대가능도 추정이라고 하며, 실제 Observation을 가장 잘 설명하는 파라미터(theta)를 찾아내는 과정을 말함. 즉, 가장 잘 설명하는 파라미터 값을 의미. 예) 압정이 떨어졌을 때, 뒷면으
7.Mnist DataSet
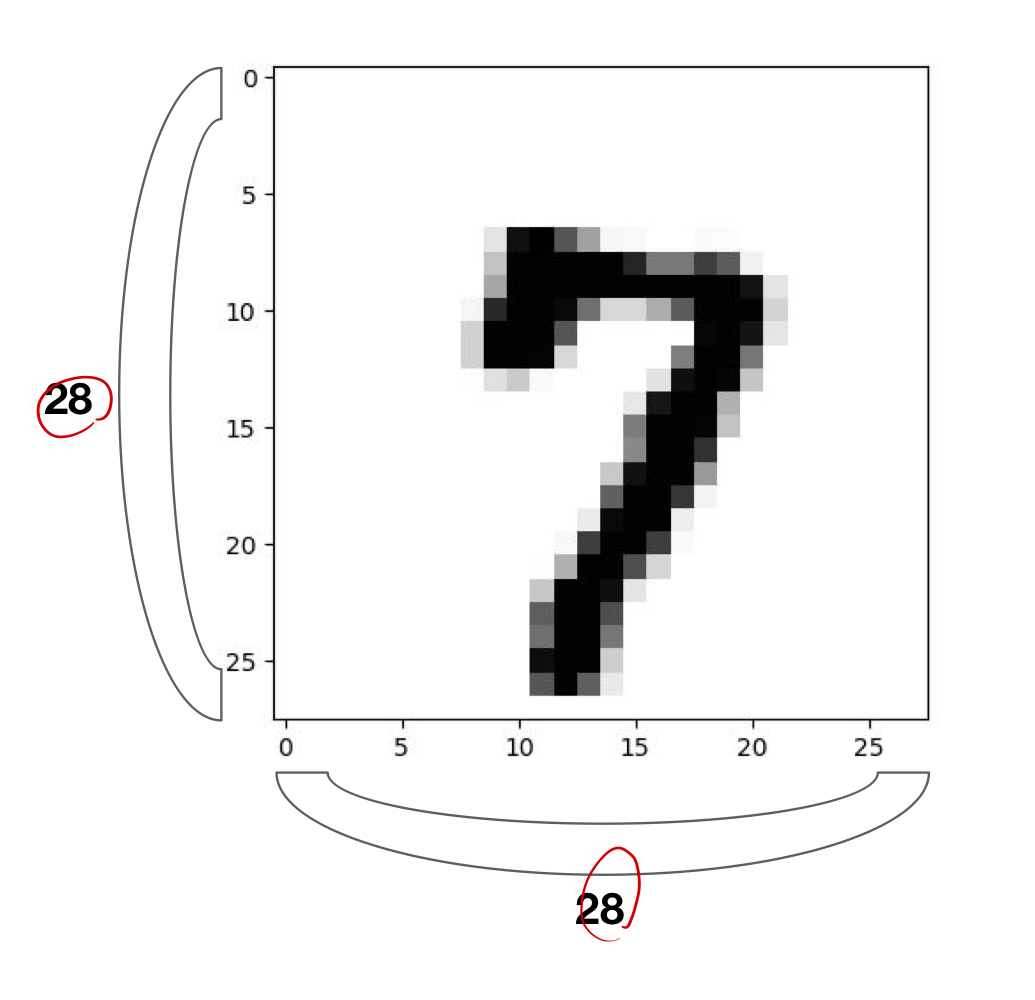
Mnist Dataset : Handwriteen digits dataset을 의미하고, 0~9까지 숫자 데이터가 입력되어 있다. 우편번호를 인식하고 싶어서 만들어진 데이터 셋이다.데이터 형태 : 28 \* 28 이미지로 되어있으며2.1개의 channel의 gray i
8.Perceptron
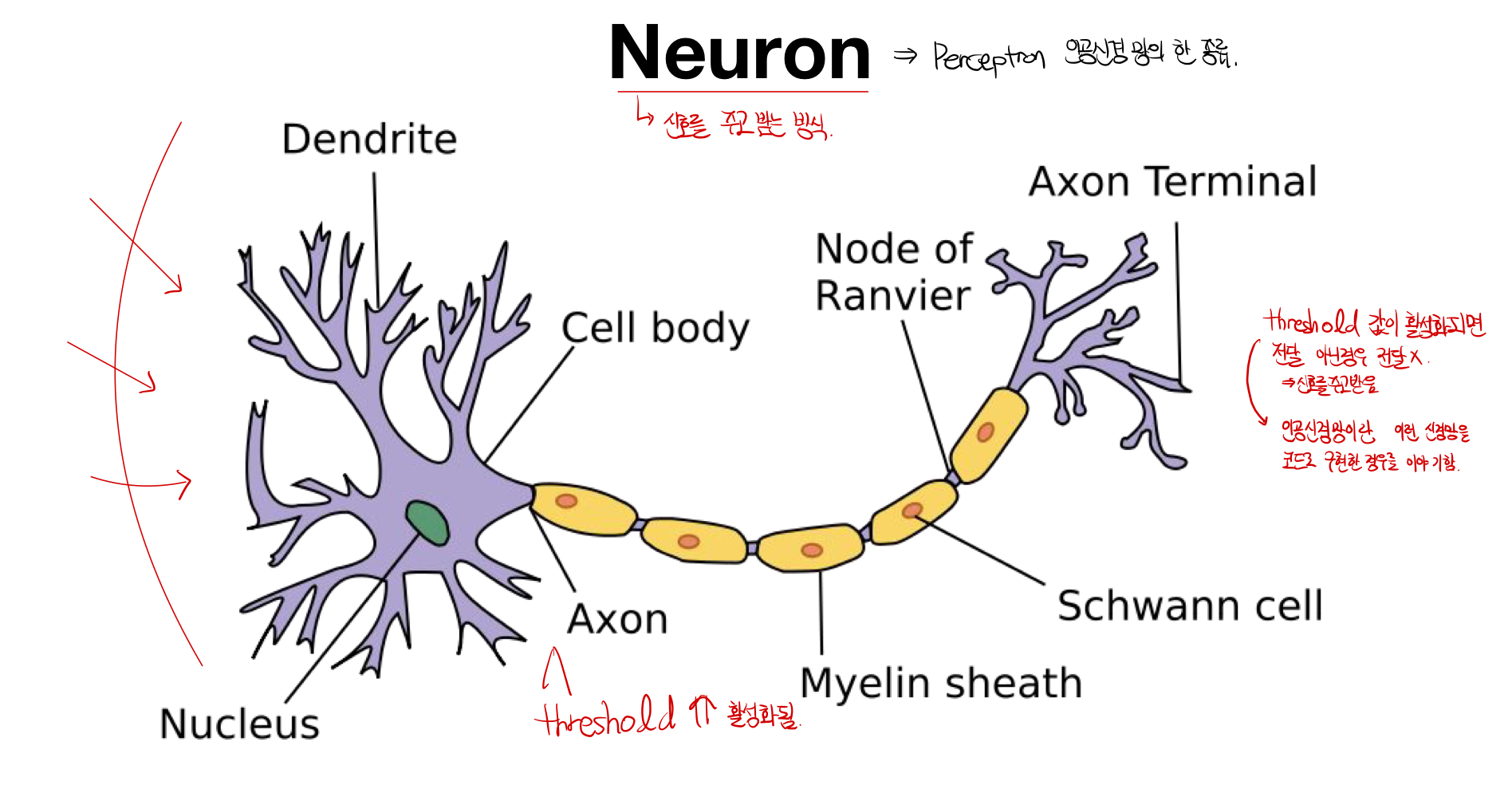
Neuron의 동작 원리: 신경망이라고 불리우며, threshold의 값이 일정 값 이상 전달되면 활성화되어 전달이 되고, 이외의 경우는 신호가 전달되지 않는다. 이러한 원리를 통해서 뉴런끼리 신호를 주고 받는다. Perception : Perception은 인공신경망
9.RELU Function
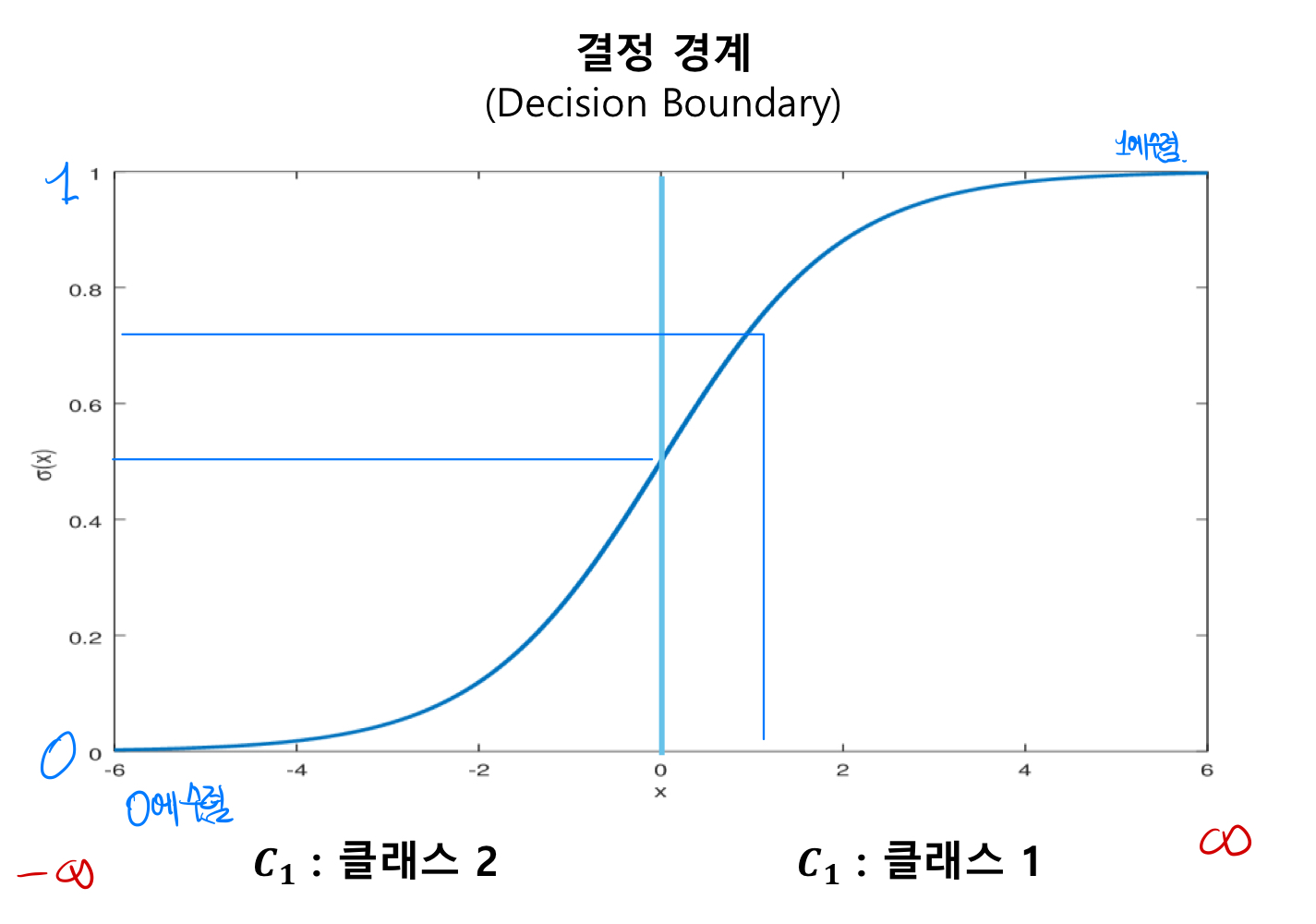
Sigmoid Function이란? 로지스틱 함수에서 선형예측 결과를 확률로 변환하는 함수로, 0과 1 사이의 값으로 값을 변환해준다.문제점: Sigmoid 함수를 사용하면 gradient 함수를 이용해서 back propagation을 진행할때, sigmoid함수를
10.Weight initialization
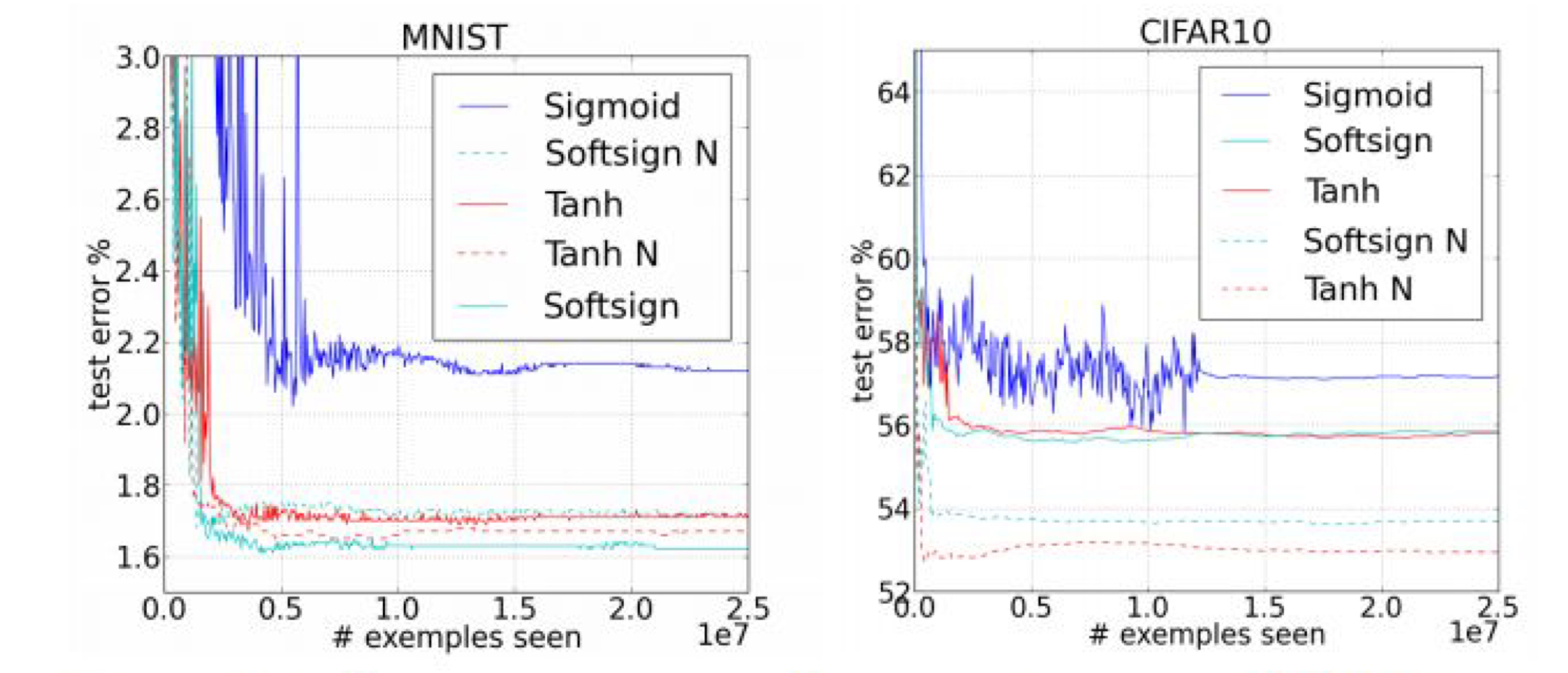
아래의 그래프와 같이 학습된 결과 값의 에러값을 비교해 봤을때, good initializaion이 일어났을 때, 더 좋은 예측 손실 값을 얻은 것을 알 수 있다. ( initializaion - 뒤에 N 표시)현명한 initialization 방법 : 0으로 초기화
11.Drop-Out :: Overfitting의 새로운 해결방안
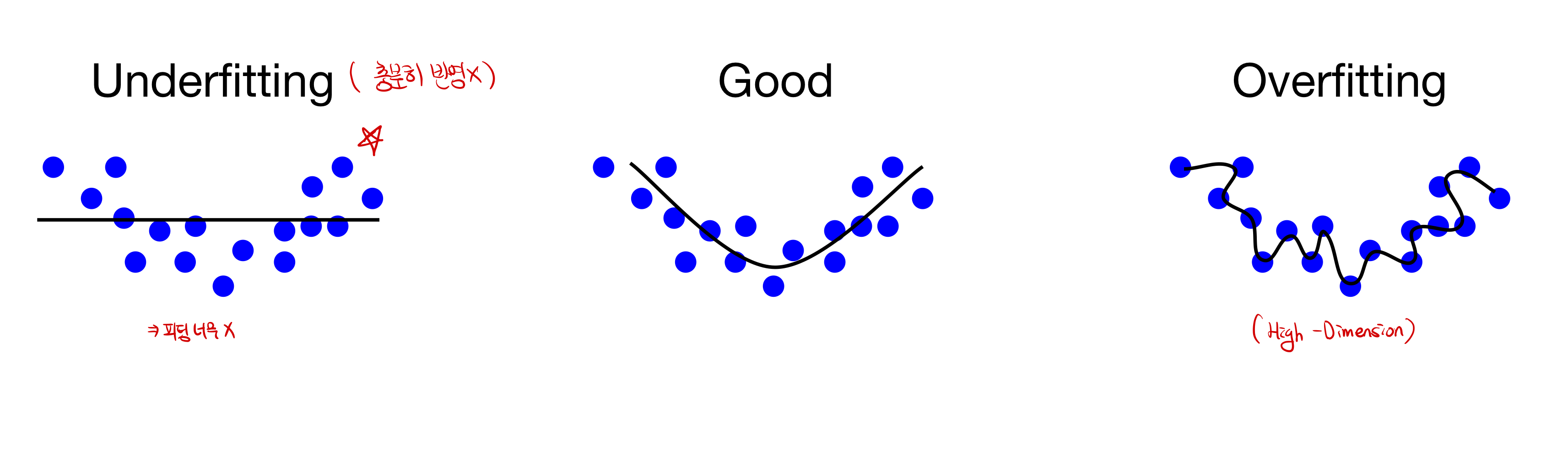
Fitting 이란? 모델의 학습 적합도를 의미한다. 충분한 학습이 되지 못해, 적합도가 떨어지는 모델을 Underfitting이 된 상태라고 의미하며, 너무 train dataset에 과적합되어있는 경우를 Overfitting이라고 한다.Overfitting의 문제
12.Batch -Normalization
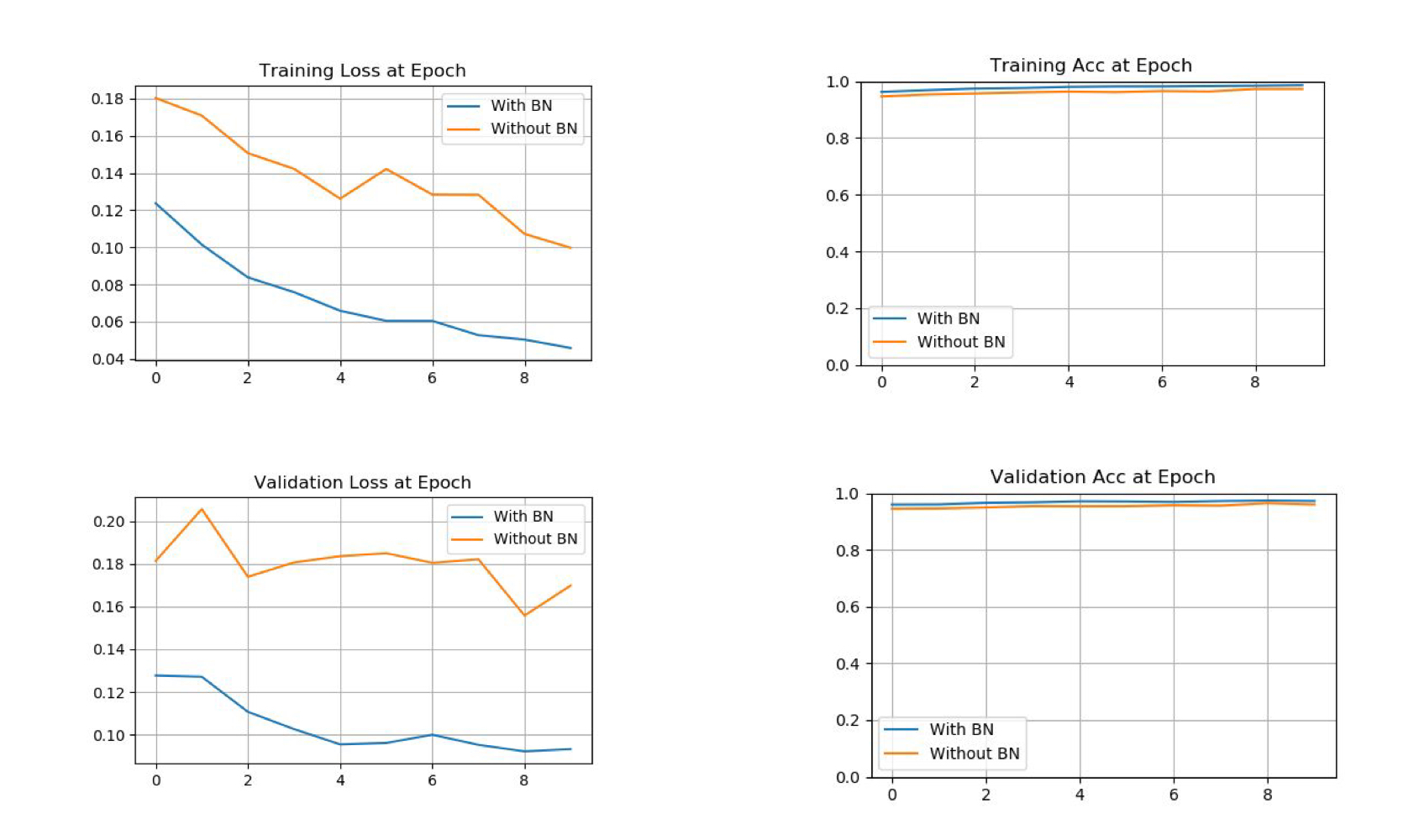
Gradient Vanishing / Exploding Gradient Vanishing : Sigmoid Activation Function과 같이, Gradient값이 Back propagation이 되면서 소멸하는 문제를 말한다. _ Gradient Explod
13.Lab 10 Convolutional Neural Network - Convolution
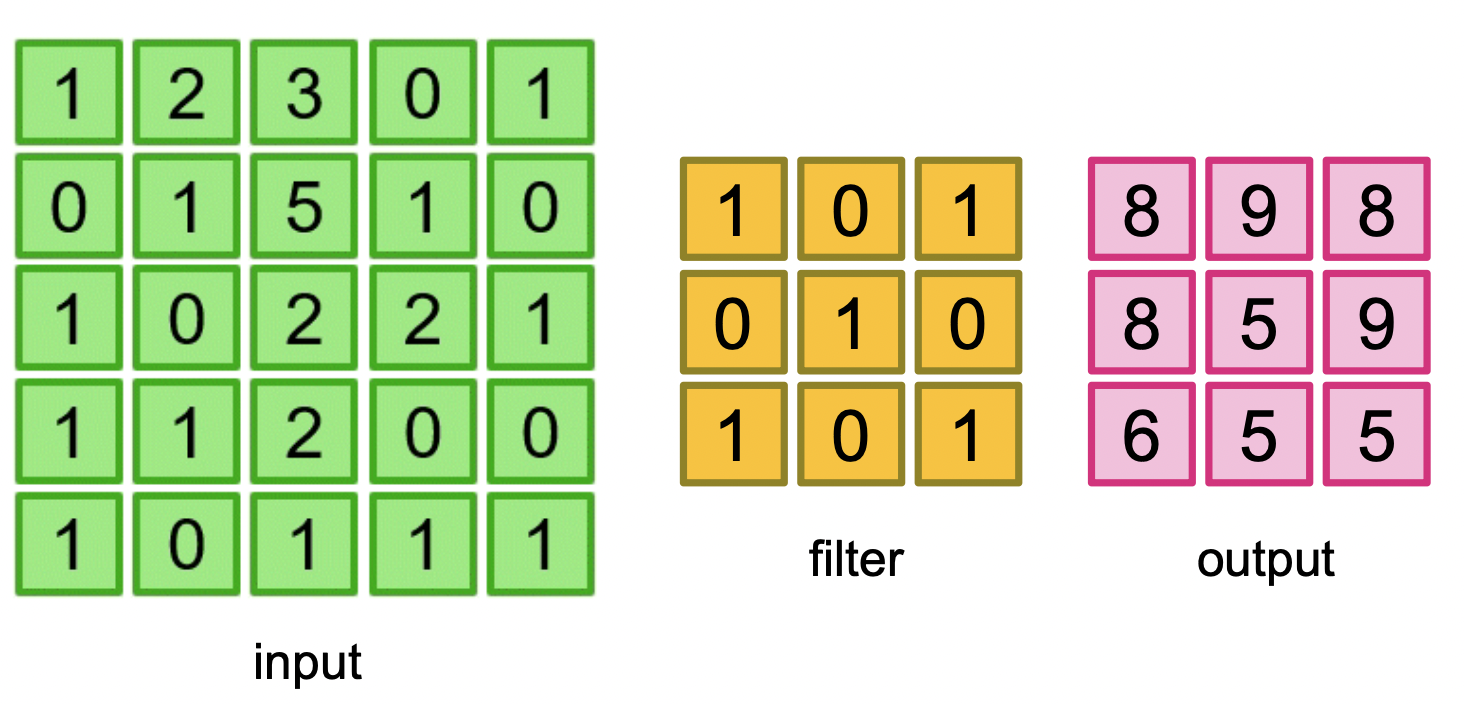
앞으로 다룰 내용:Convolutional Neural Network 가 무엇인지MNIST로 Convolutional Network 만들기Pytorch VisdomPytorch Visdom Dataset & Custom Dataset ( 데이터를 어떻게 분류할 수 있을
14.Lab 10 Convolutional Neural Network - Mnist CNN Model

라이브러리 가져오고 (torch, torchvision, matplotlib 같은것들)GPU 사용 설정 하고 random value를 위한 seed 설정!학습에 사용되는 parameter 설정!(learning_rate, training_epochs, batch_siz
15.Lab 11 Convolutional Neural Network :: Visdom
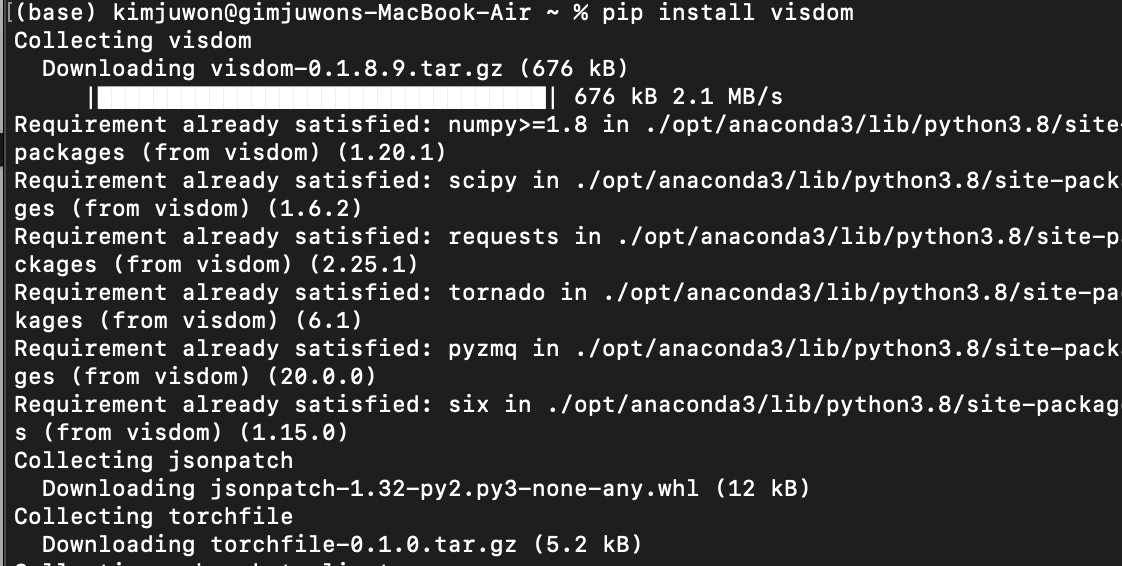
Visdom 설치 방법 1\. pip install visdom2\. python –m visdom.servervisdom 사용시 주의 사항 : 사용할 동안 켜놔야 함 line함수에서 X값을 설정을 안해줄 경우, 0~1 사이의 임의의 값이 설정됨.
16.모두를 위한 딥러닝 2 : 10-4 Image Folder
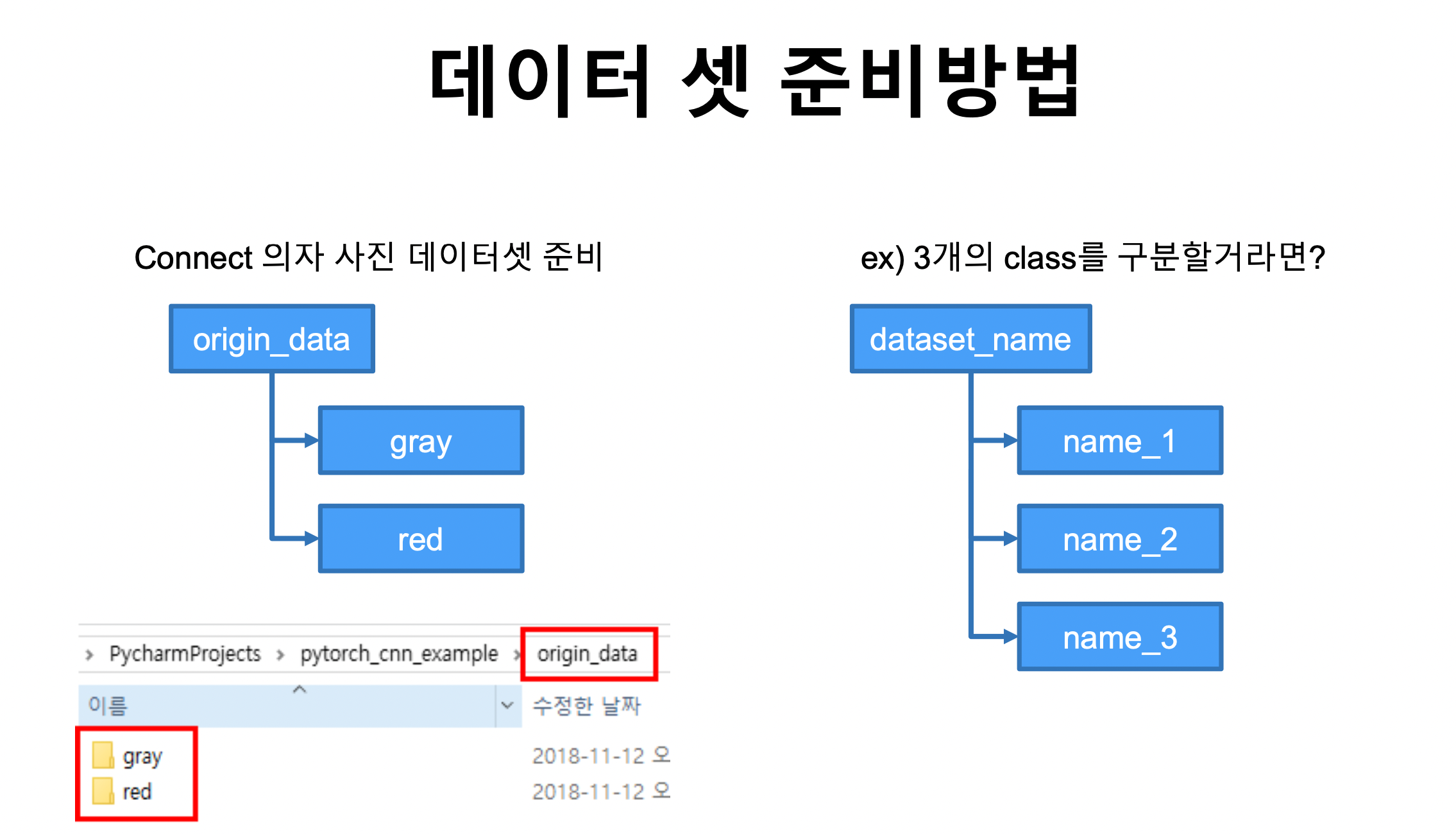
나만의 데이터 셋 준비하기torchvision.datasets.ImageFolder으로 불러오기transforms 적용하여 저장 하기 origin_data -> train_data이번 예제의 모델 : 의자 origin_data > gray & red 에 데이터 저장 (
17.모두를 위한 딥러닝 2 :: 10-5 Advanced CNN ( VGG )
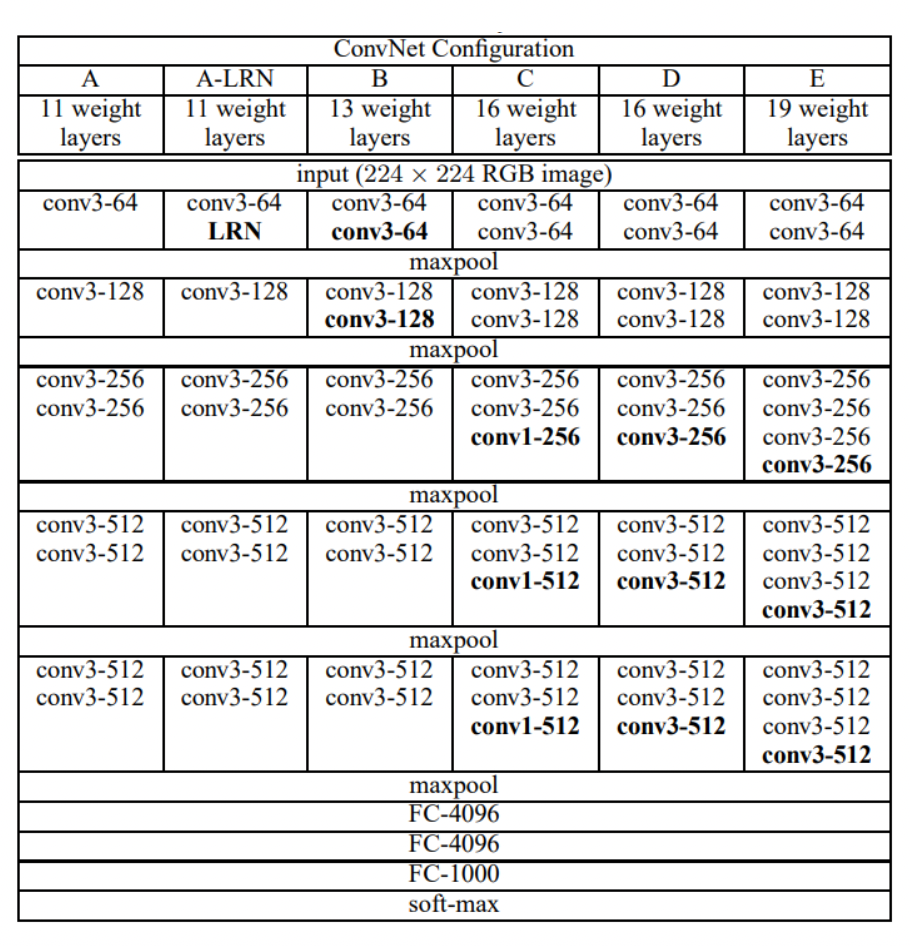
VGG-Net Oxford VGG(Visual Geometry Group) 에서 만든 Network 전부다 3X3 Convolution, stride =1, padding =1 VGG 16 torch.vision.vgg karming_normalizaion : activation function 초기화를 잘 해주기 위해서 사용 in_channels 에...
18.모두를 위한 딥러닝 시즌 2: ResNet
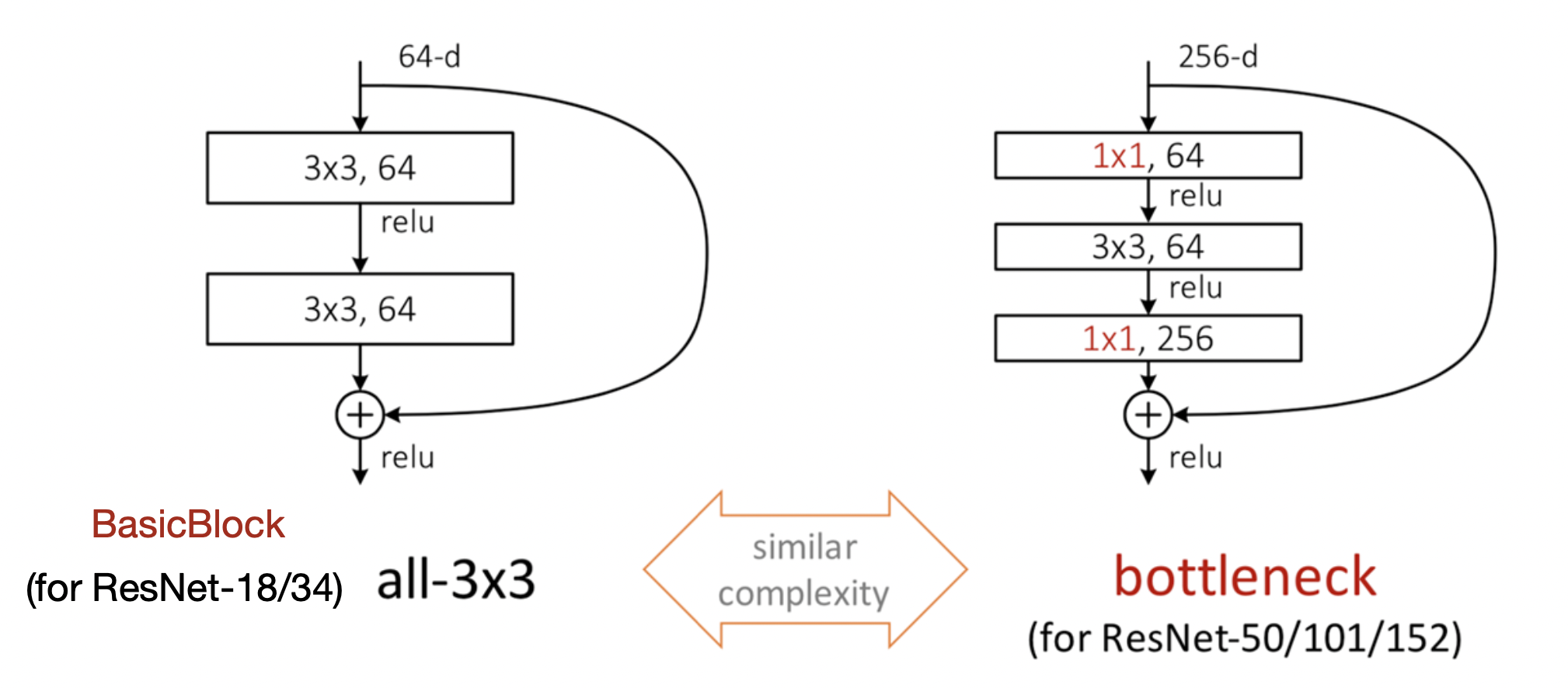
resnet (18,34,50,101,152)를 만들 수 있도록 되어있음3x224x224 입력을 기준으로 만들도록 되어 있음downsample을 이용해서 연산이 이뤄질 수 잇도록 사이즈를 맞춰줌downsample이 없다면 pooling 과 stride로 shpae이 변
19.모두를 위한 딥러닝 시즌 2 :: ResNet (CIFAR10)
loss와 accuracy를 함께 넣기 위해서
20.모두를 위한 딥러닝 시즌 2 :: Object Detection , Tracking, Segmentation
지금까지 해왔던 학습 방법 ( 회귀를 확률함수를 통해 변형시켜서 분류하기 주어진 사진이 주어지면 그 사진이 어떤 사진인지 분류(예측)해내는 것종류 : DenseNet, SENet, MobileNet, SqueezeNet, AutoML(NAS, NASNet) 사진이 주어
21.모두를 위한 딥러닝 2 :: RNN intro
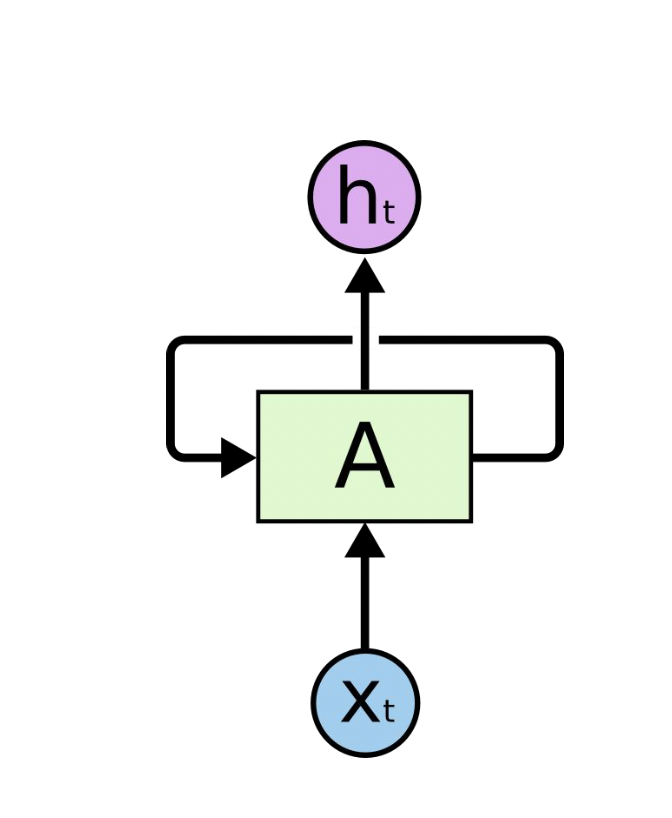
Sequential Data를 처리하기 위해 도입됨. 기존에는 Position index를 이용해서 순서를 분류해서 NN을 만들어서 데이터를 학습했었음. 하지만 사람의 언어와 같이 모델을 파악하는데에는 쉽지 않은 모델이었음. 하지만 RNN은 사람의 언어, 자연어와 같은
22.모두를 위한 딥러닝 2 :: RNN 11 -1 Basics
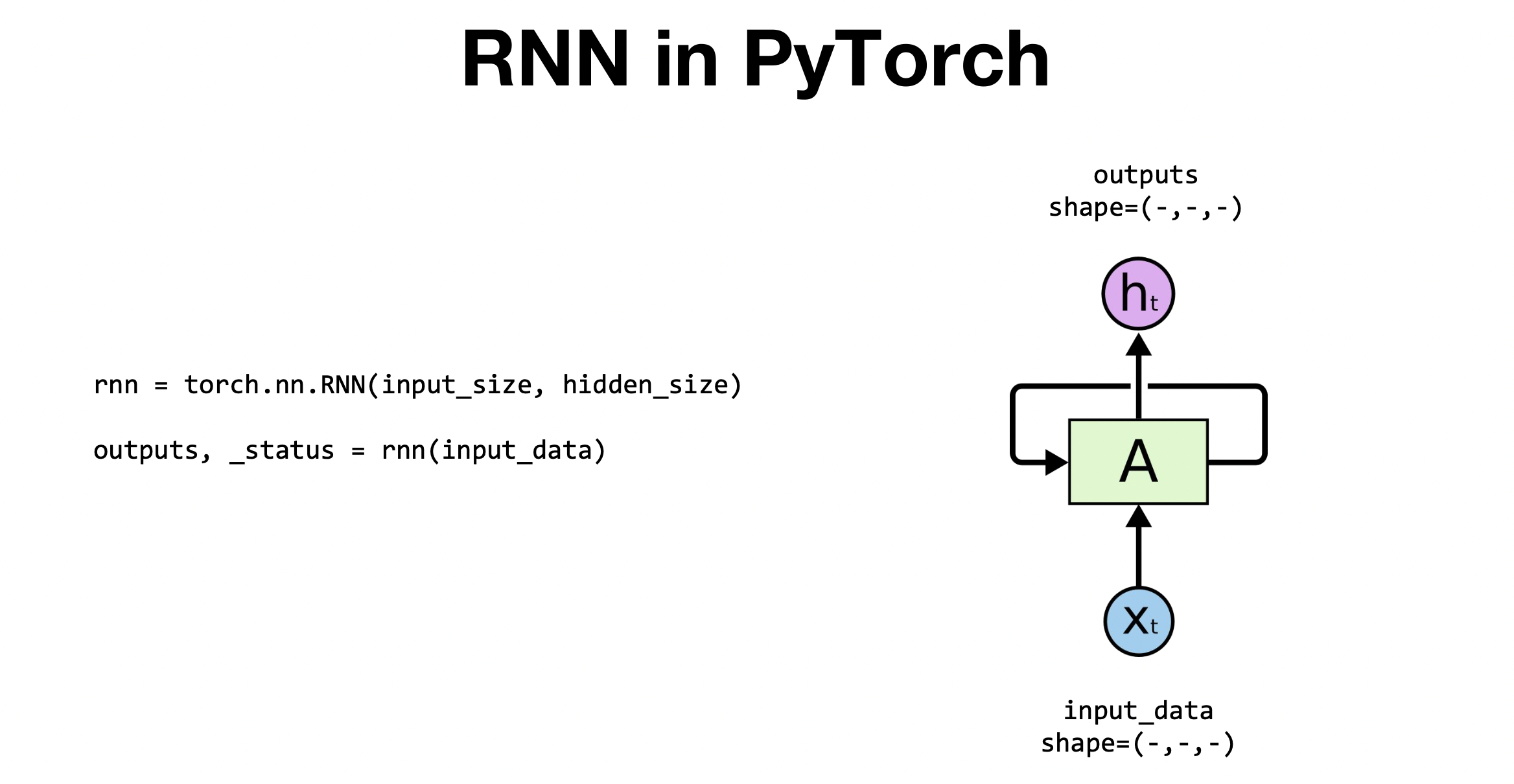
PyTorch에서 RNN은 크게 두줄을 통해 한셀을 정의해줄 수 있음.첫번째 줄 = torch.nn.RNN() 을 이용해서 inputsize와 hiddensize을 선언해줌. cell을 정의 해주는 문장이라고 생각하면됨. 두번째 줄 = A라는 function에 inpu
23.모두를 위한 딥러닝 2 :: Lab-11-2 RNN hihello and charseq

hihello를 예측하는 모델을 만들려고 함. 하나의 알파벳이 주어질 때 다음 문자를 예측할 수 있도록 하는 RNN 모델을 만들려고 함.벡터의 하나의 축에서만 1로 표현되고 나머지부분은 0으로 표현되는 방식으로 벡터의 차원의 수는 알파벳의 종류이다. 입력할때는 출력될
24.모두를 위한 딥러닝 2:: Long Sequence

hihello/charseq과 다른점 : input문장이 길어 특정 size로 잘라서 사용함. 조각조각 데이터를 만드는 것이다. Ex) 한칸씩(character씩) 움직이면서 10칸씩 잘라냄
25.모두를 위한 딥러닝 2:: Lab-11-4 RNN timeseries
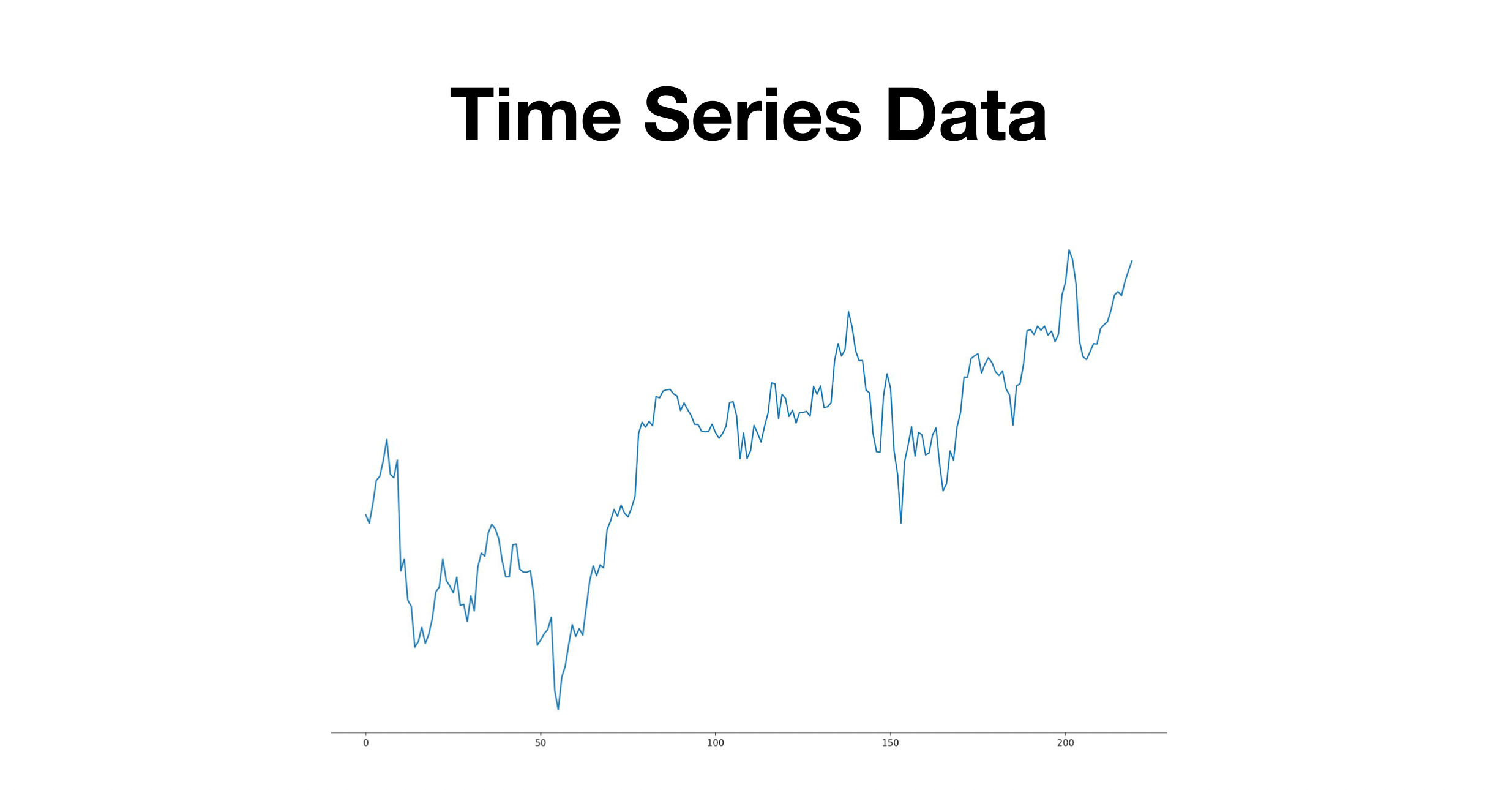
Time Series Data란? 시계열 데이터라고 불리며, 일정한 시간 간격으로 배치된 데이터를 말한다. 대표적인 예로는 주가 데이터를 예로 들 수 있다.사용할 데이터 : 구글 주가 데이터이 모델은 7일간의 주가데이터를 이용해 8일차의 주가데이터를 예측하는 모델을 전
26.모두를 위한 딥러닝 시즌 2:: Lab-11-5 RNN seq2seq
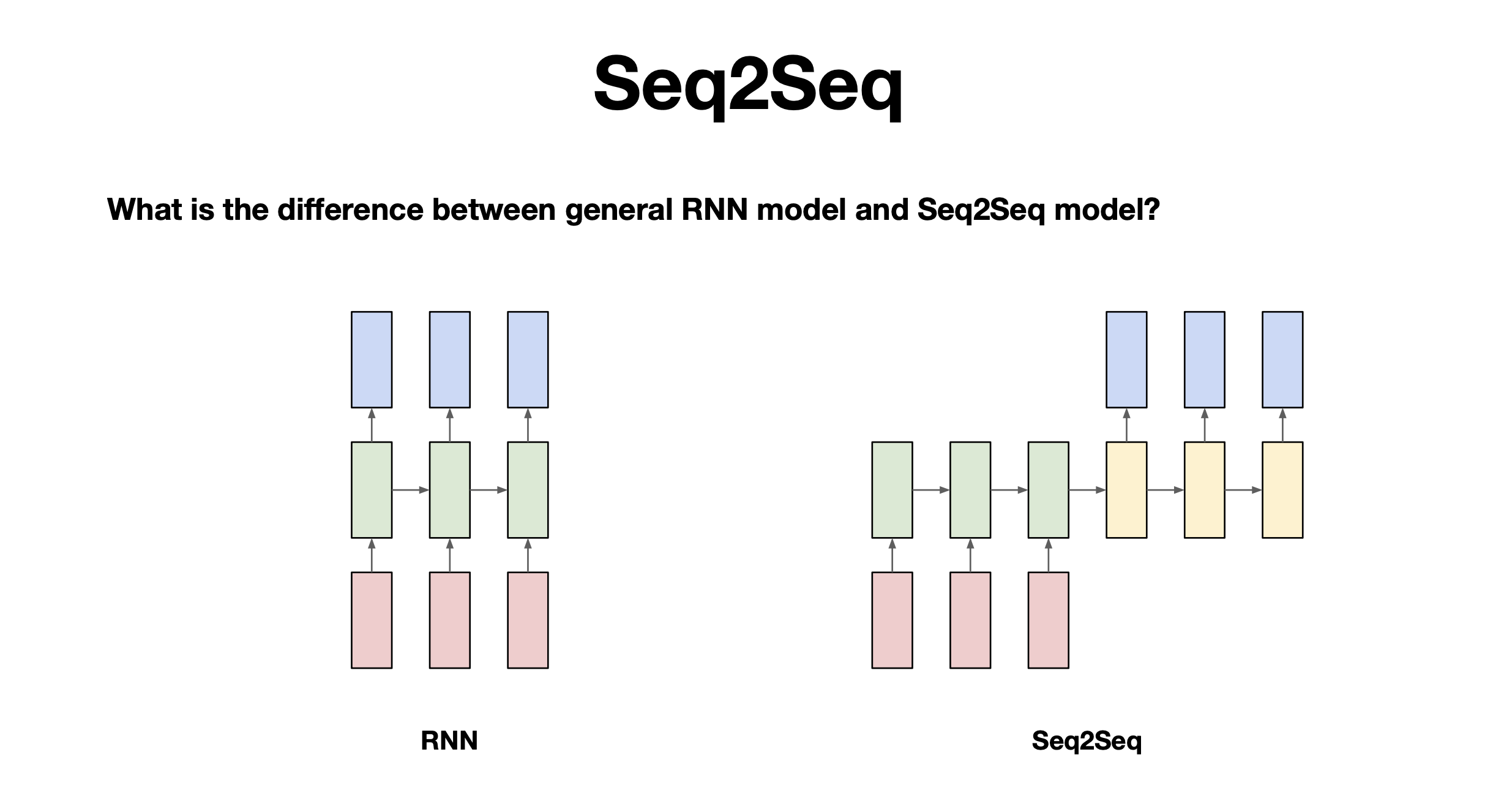
Seq2Seq가 잘 적용되는 예 : chatbot, 번역다음과 같은 상황에서는 잘 대답할 수 있을까? 대부분의 모델은 단어가 입력됨에 동시에 다음단어를 예측해서 출력됨으로 긍정-부정으로 이어지는 문장같은 경우 예측해서 대답하기가 쉽지 않음. 이러한 경우 seq2seq모
27.모두를 위한 딥러닝 2:: 11-6 PackedSequence
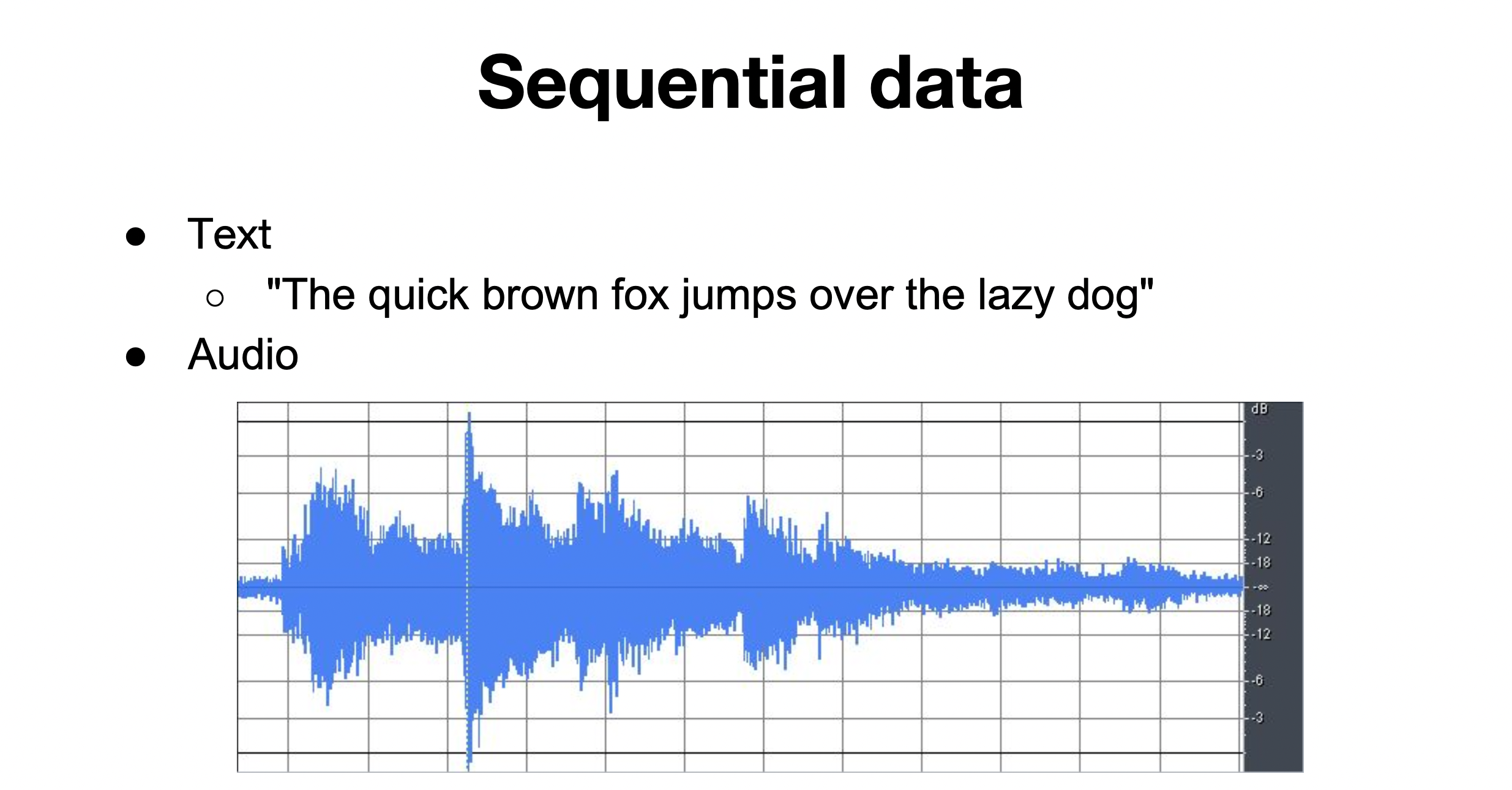
예시 : 자연어처리, NLP에 쓰이는 텍스트 data, audio data, video data emd길이가 미정인 데이터가 많음, 가장 긴 서킷 즉, short circuit이라는 문장의 길이에 맞춰 나머지 data의 뒷부분을 pad라는 token으로 채워넣는 방법장