강화학습
1.[HUFS RL] 강화학습 : Reinforcement Learning Introduction
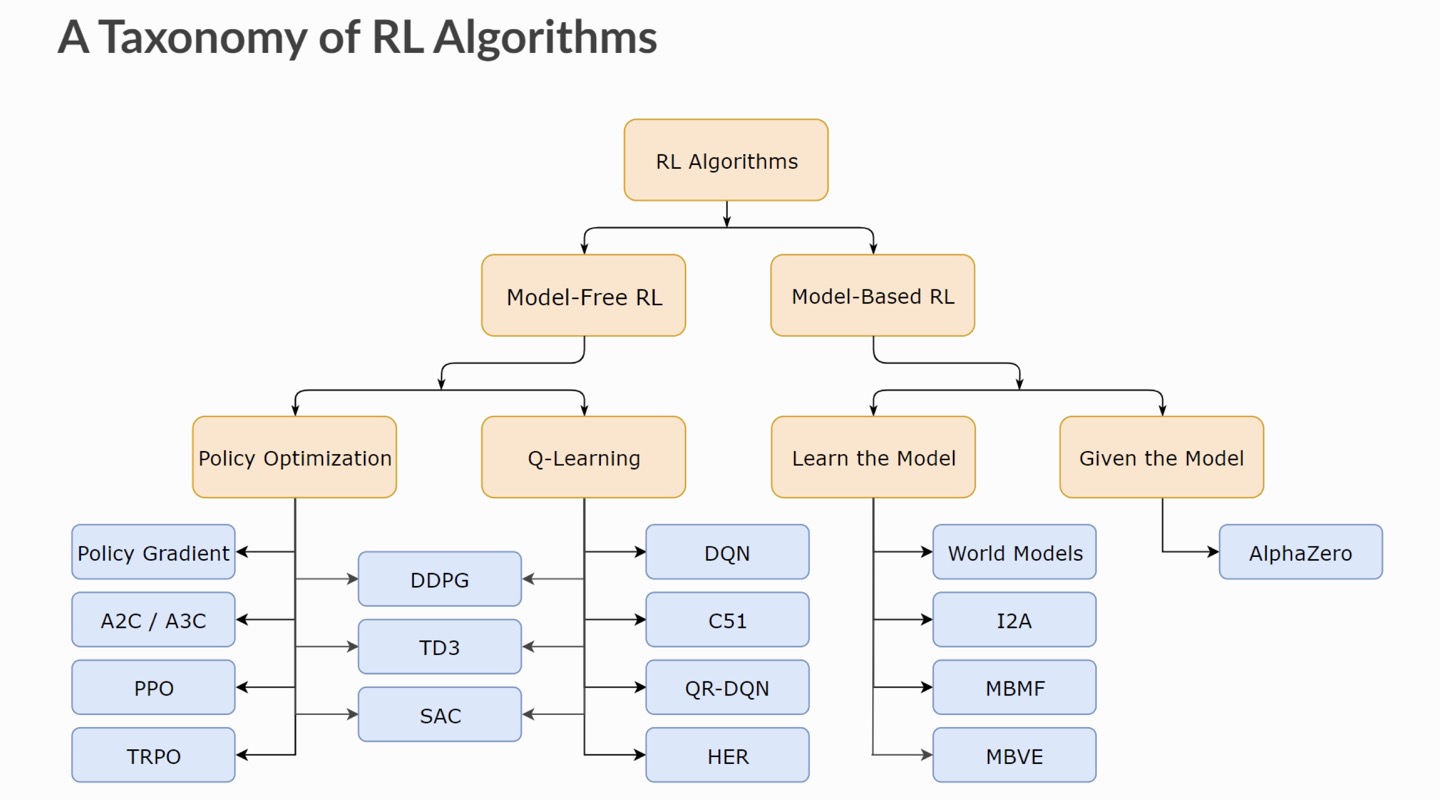
강화학습 안녕하세요~ Velog를 통해 공부하시는 여러분! 오늘은 여러분들에게 강화학습에 대해서 소개해드리려고 합니다~! 정의 여러분 알파고를 기억하시나요?! 알파고는 '이세돌'에게 유일하게 패배한 73승 1패의 전적을 가지고 있는 인공지능입니다. > 강화학습
2.[HUFS RL] 강화학습 : Reinforcement Learning: Q- Learning

Q-Learning Q learning이란 : Q -learning이란 벨만 방정식을 이용하여 미래가치를 예상하여 action을 정하는 방법으로 Model-Free Reinforcement Learning의 한 종류입니다. 벨만 방정식, Q-Table 그리고 Expl
3.[HUFS RL] 강화학습 : Reinforcement Learning: Policy Gradient (REINFORCEMENT)

강화학습 정의 : 주어진 환경(environment)에서 에이전트(Agent)가 최대 보상(Reward)를 받을 수 있는 활동(Action)을 할 수 있도록 Policy를 학습하는 것! 환경(Environemt) : 에이전트가 액션을 취하는 환경을 말합니다. 슈퍼마리
4.[HUFS RL] 강화학습 : Reinforcement Learning: TRPO (Trust Region Policy Algorithm )
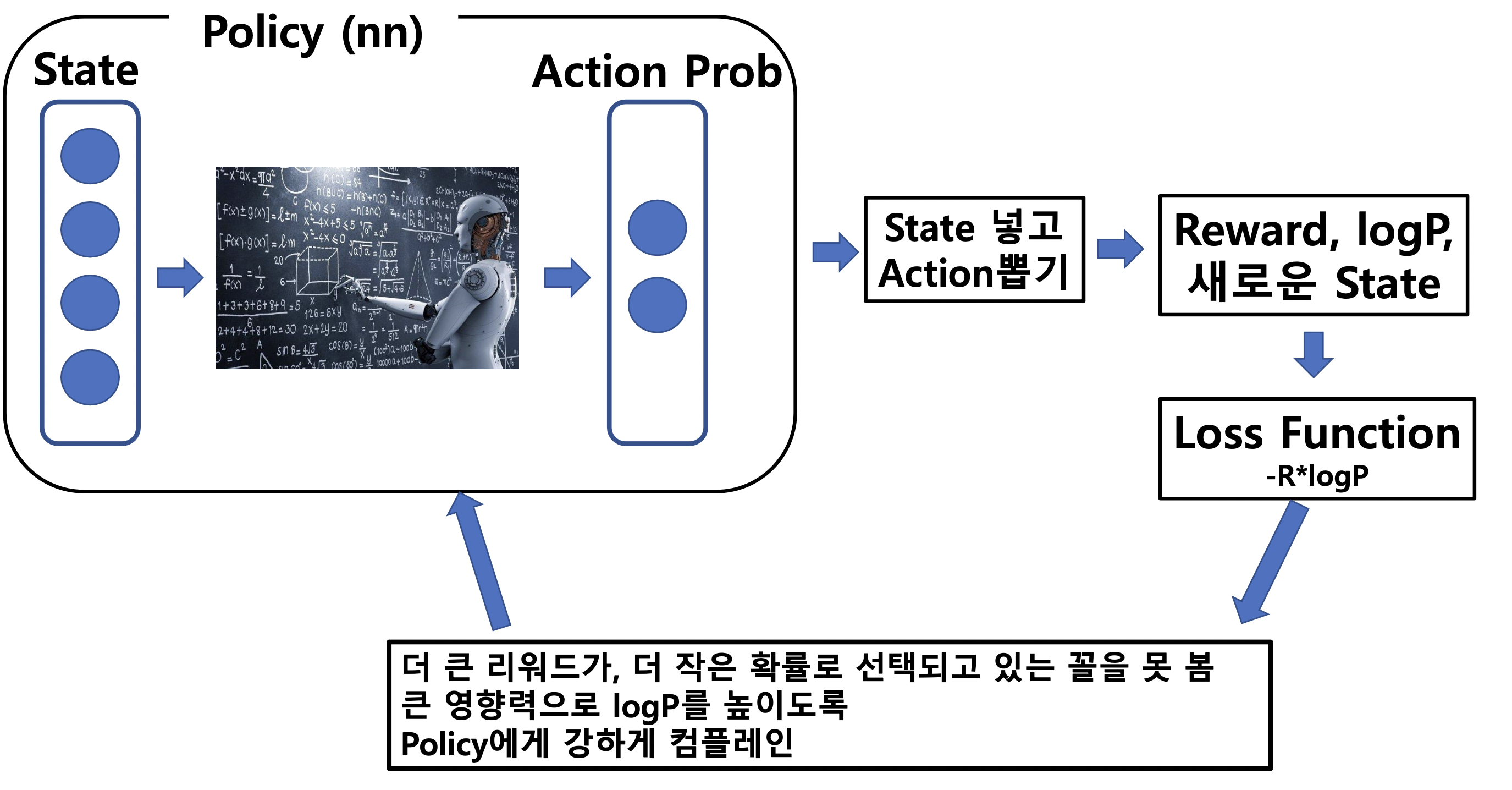
강화학습 정의 : 주어진 환경(environment)에서 에이전트(Agent)가 최대 보상(Reward)를 받을 수 있는 활동(Action)을 할 수 있도록 Policy를 학습하는 것! 환경(Environemt) : 에이전트가 액션을 취하는 환경을 말합니다. 슈퍼마리
5.[HUFS RL] 강화학습 : Reinforcement Learning: PPO (Proximal Policy Optimization)

강화학습 정의 : 주어진 환경(environment)에서 에이전트(Agent)가 최대 보상(Reward)를 받을 수 있는 활동(Action)을 할 수 있도록 Policy를 학습하는 것! 환경(Environemt) : 에이전트가 액션을 취하는 환경을 말합니다. 슈퍼마리
6.[HUFS RL] 강화학습 : Reinforcement Learning: DDPG (Deep Deterministic Policy Gradient)
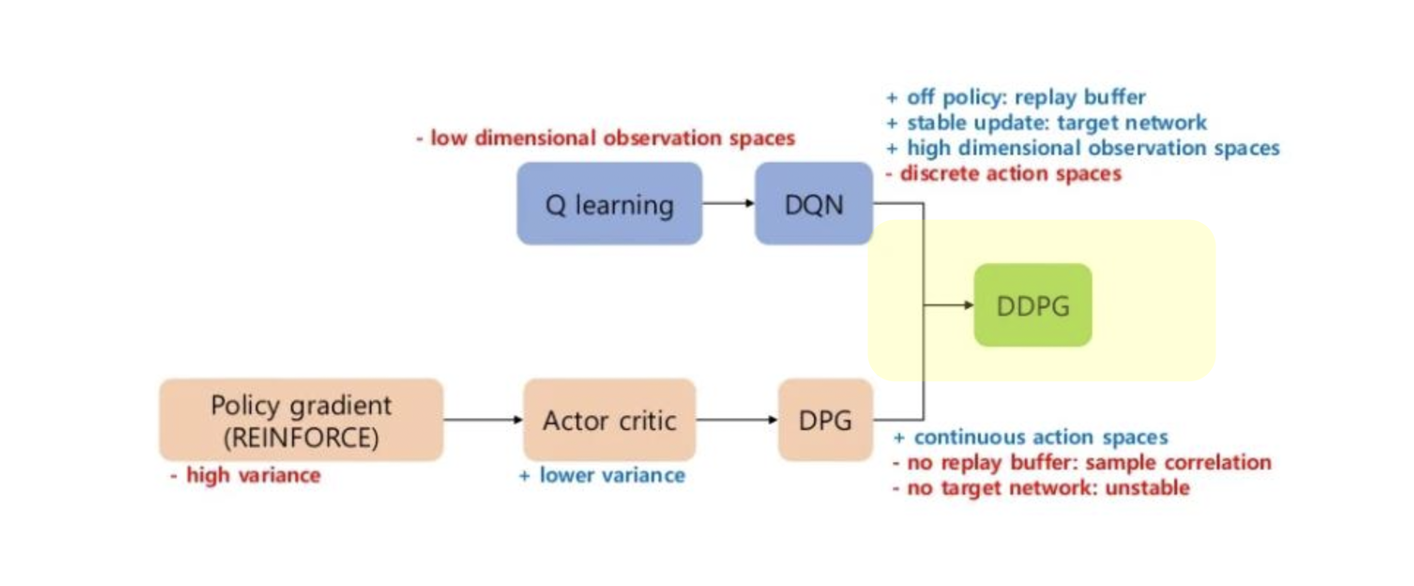
\-) 논문 살펴 보기 기존 Q-learning을 신경망을 이용해서 개선한 모델단점 : Discrete한 경우 밖에 적용이 되지 않음 => 보안한 방식이 DDPG(Deep Deterministic Policy Gradient\+) 네이쳐지 참고하기Actor와 Criti