강화학습

안녕하세요~ Velog를 통해 공부하시는 여러분!
오늘은 여러분들에게 강화학습에 대해서 소개해드리려고 합니다~!
정의
여러분 알파고를 기억하시나요?! 알파고는 '이세돌'에게 유일하게 패배한 73승 1패의 전적을 가지고 있는 인공지능입니다.
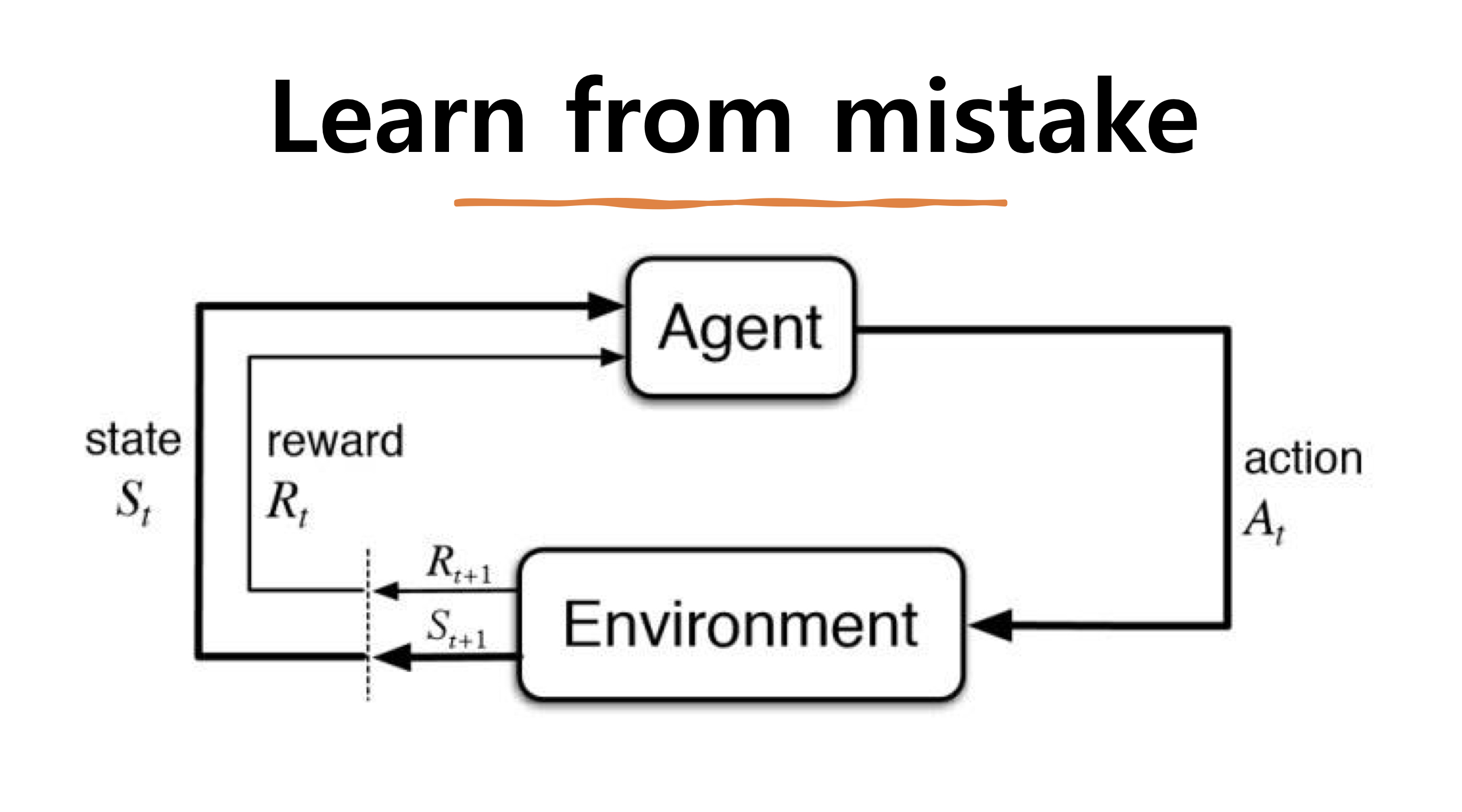
강화학습 : 강화 학습(Reinforcement learning)이란 기계 학습의 한 영역으로 행동심리학에서 영감을 받아 만들어 졌으며, 어떤 환경 안에서 정의된 에이전트가 현재의 상태를 인식하여, 선택 가능한 행동들 중 보상을 최대화하는 행동 혹은 행동 순서를 선택하는 방법을 말합니다.
따라서 강화학습은 머신러닝의 지도학습처럼 일정한 라벨링 없이 학습이 진행됩니다. 또한 이미 정해진 데이터를 통해 학습하는 것도 아닙니다. 오직 주어진 환경안에서 에이전트(Agent)가 행동(act)을 하고 보상(Reward)이 최대가 되는 방식으로 학습을 합니다.
용어 정리
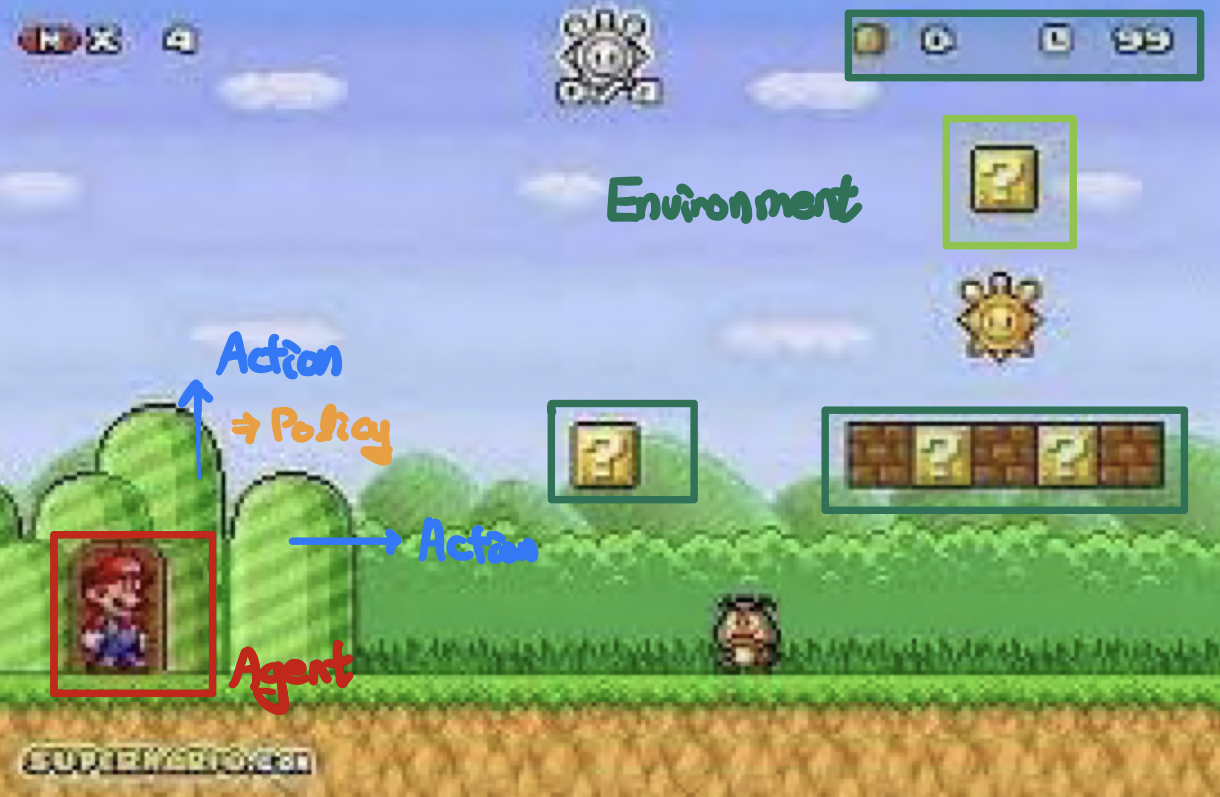
- 환경(Environemt) : 에이전트가 액션을 취하는 환경을 말합니다. 슈퍼마리오 게임을 예를 든다면 버섯, 현재 마리오의 위치, 아이템, 구조물, 점수 등등 모든 것들이 환경이 됩니다.
- 에이전트(Agent) : 에이전트는 학습 대상을 말합니다. 환경안에서 학습을 하는 주체로 보상을 최대로 받는 방식으로 학습을 합니다
- 보상(Reward) : 에이전트가 한 번 학습했을 때 주어지는 값입니다. 사용자가 설정한 결과를 만들어냈을때(최고점 획득,최소경로 학습, 최적경로 학습 등) 높은 값의 보상값을 얻을 수 있습니다.
- 행동(Act) : Agent가 취하는 행동으로 환경에 따라 다른 action 집합을 가지고 있습니다. 주로 앞으로가기, 뒤로가기와 같은 것들을 벡터형태 혹은 매트릭스 형태로 표현합니다. 행동의 유한성에 따라 유한할 경우 Discrete Action set을 갖고, 무한한 경우 continuous Action Set을 갖고 있습니다.
- Ex) Discrete Action Set 예시 : 마리오게임에서 점프, 앞으로 가기
- Ex) Continuous Action Set 예시 : 자율주행 자동차에서 회전각도
- 정책(Policy) : 궁극적으로 학습을 통해 구하려는 것으로 특정 상황에서의 action 혹은 action의 확률을 정의합니다.
- Exploitation : 학습을 한 결과를 바탕으로 탐색을 하는 방법
- Exploration : 새로운 학습을 위해 학습이 제시한 가이드라인 밖을 벗어난 방법으로 탐색을 하는 방법
강화학습의 종류 :
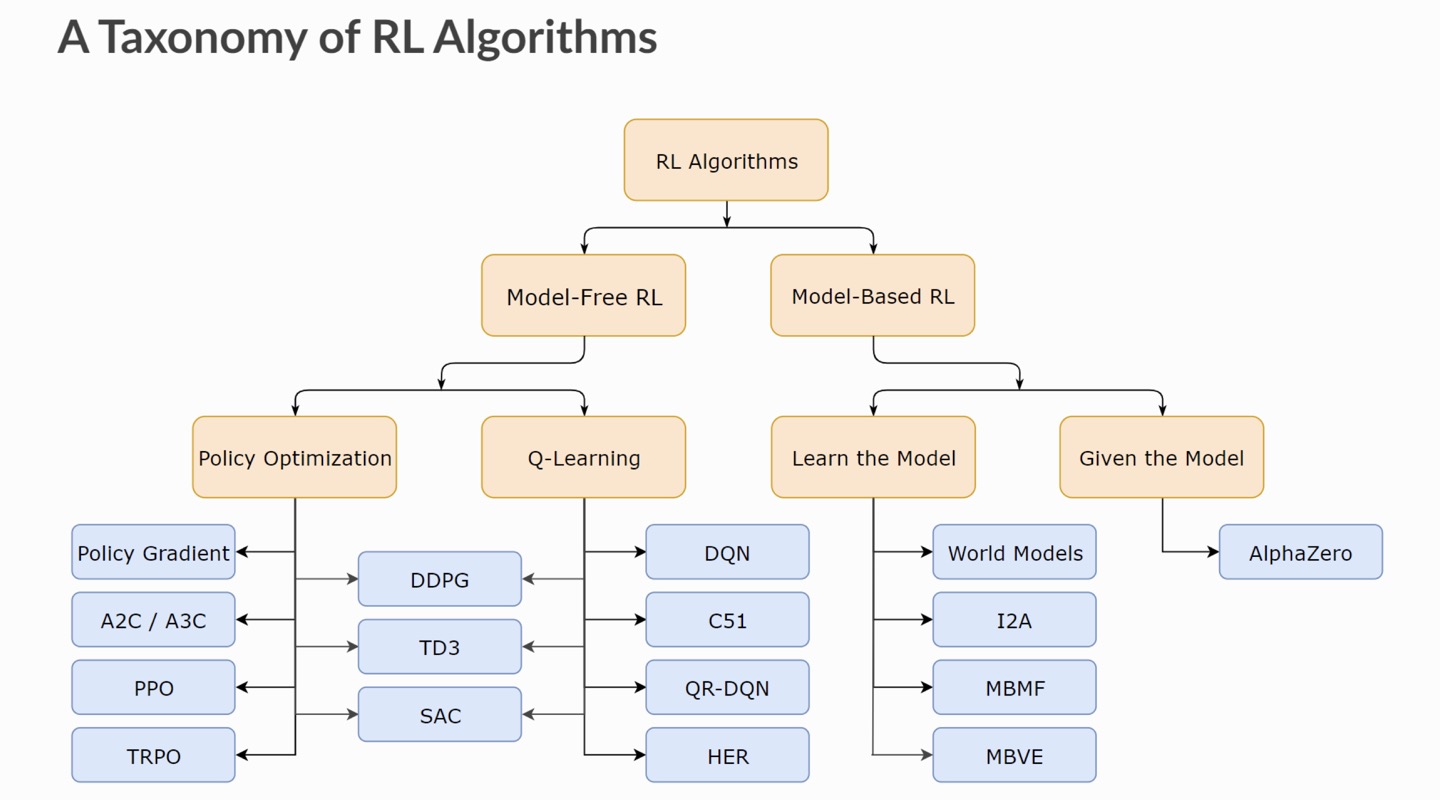
- 강화학습은 크게 Model-Free RL 그리고 Model Based RL로 나뉩니다.
- Model Free RL : Model Free RL은 모델이 없는 강화학습 방법으로 주로 확률이나 매트릭스를 활용하여 Policy를 결정합니다. 어떤 환경에서도 적용가능한 방법이기에 범용성이 크지만, 동시에 환경에 따라 성능이 달라지고 Model Based RL에 비해 성능이나 학습속도가 떨어집니다. ( 상대적 기준)
- Q-Learning
- Vanilla Policy Gradient (VPG)
- Trust Region Policy Optimization (TRPO)
- Proximal Policy Optimization (PPO)
- Deep Deterministic Policy Gradient (DDPG)
- Twin Delayed DDPG (TD3)
- Soft Actor-Critic (SAC)
- Model Based RL : Model Based RL은 특정상황에 대한 모델을 정해놓고 학습하는 방법입니다. 학습효율과 성능이 좋으나 특정 환경에만 확습이 가능하기 때문에 범용성이 낮다는 문제점이 있습니다.
OpenAI
2015년에 일론머스크가 미국의 10억달러 지원을 받고 설립된 회사로 오픈AI(OpenAI)는 프렌들리 AI를 제고하고 개발함으로써 전적으로 인류에게 이익을 주는 것을 목표로 하는 인공지능 연구소입니다. 이윤을 목적으로 하는 기업 OpenAI LP와 그 모체 조직인 비영리 단체 OpenAI Inc로 구성되어 있다. 이 단체의 목적은 특허와 연구를 대중에 공개함으로써 다른 기관들 및 연구원들과 자유로이 협업하는 것이다.설립자들(특히 일론 머스크, Sam Altman)은 인공 지능의 존재 문제의 염려에 부분적으로 동기를 받았다
출처 : 위키피디아
따라서 OpenAI에서는 현재 AI와 관련된 다양한 알고리즘을 제공해주는데요. 특히나, OpenAI중 Gym에서는 다양한 강화학습을 게임을 적용할 수 있도록 하는 학습 Environment를 제공합니다. 또한 Pytorch를 이용하여 다양한 강화학습을 해줄 수 있도록 여러 Model Free Algorithm 또한 확인하실 수 있습니다.
SpinningUp Algorithm : https://spinningup.openai.com/en/latest/user/algorithms.html
Open AI : https://gym.openai.com/
Open AI Gym사용 방법 : https://gym.openai.com/docs/
강의자 : 구태훈
프로그램 : HUFS AI RL 캠프
