AWS Lambda의 provisioned concurrency에 대해 생길 수 있는 오해
Lambda의 Cold Start
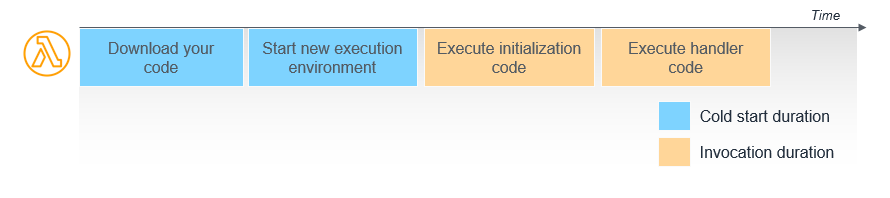
Lambda를 통해 workload를 운영할때 겪는 가장 첫번째 문제는 Cold Start입니다.
Lambda는 배포된 이후 처음 요청이 들어온 경우
- Download Code
- Start environment
- Execute Init Code
총 3단계의 초기화 단계를 거치며 이 과정이 끝난 이후에 handler 코드를 실행합니다.
이중에 수초 이상 걸리는 앞의 두 단계를 cold start 라고 부르며 초기 요청에 대한 latency를 느리게 만드는 요소로 작동합니다.
물론 한번 생성된 lambda 환경은 일반적으로 수분이내에 새로운 요청이 올 경우 기존의 환경은 앞의 두 단계를 재반복 할 필요가 없으며 cold start에 비해 빠르게 반환합니다. 이때의 lambda를 warm start라고 부릅니다
하지만 일반적으로 모든 lambda에 대해서 멈추지 않고 수분이내 계속해서 요청이 오는 경우는 흔치 않습니다. 요청 빈도가 적을때 흔히 사용하는것이 lambda의 특징이기도 하고요.
Functions Warmer
cold start를 방지하기 위한 하나의 방법은 기존의 warm 환경이 삭제되는것을 방지하기 위해 계속에서 lambda를 호출하는 것입니다. 이때 lambda를 호출하는 대상을 functions warmer라고 부릅니다.
아쉽지만 function warmer도 문제점이 있습니다. lambda는 env sticky하지 않습니다. 즉 주기적으로 람다를 호출한다고 해도 해당 호출은 동일한 환경에 대한 호출을 보장하지 않습니다.
이러한 특징으로 인해 warmer는 특정 warm lambda를 계속 호출하여 cold start를 방지할 수 있다고 보장할 수 없습니다.
그리고 이미 요청이 있을 경우 warmer로 인해 또 다른 환경이 생성되는 불필요한 동시성 유발됩니다.
Provisioned Concurrency
functions warmer의 문제를 극복하기 위한 도구로 provisioned concurrency가 있습니다.
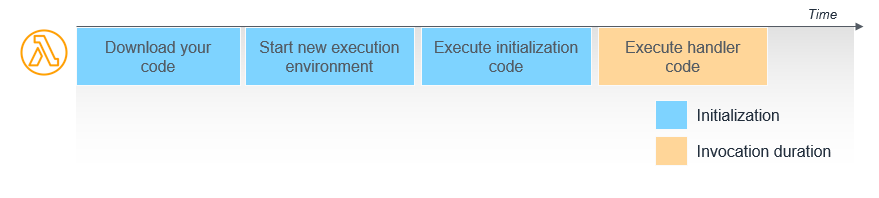
provisioned concurrency를 활용하면 lambda의 cold start를 예방할 수 있는것은 물론, init code하는 부분도 invocation단계에서 걷어내서 더욱 빠른 latency를 유지할 수 있게 됩니다.
하지만
재밌는 테스트를 위해 lambda의 provisioned concurrency를 1로 유지한채 5초 단위로 lambda를 호출하도록 코드를 구성해 보겠습니다
lambda의 코드는 간단하게 python으로 작성하였습니다
### --- init block ---
import json
import datetime
import time
print(datetime.datetime.now())
print("Lambda Started")
time.sleep(8)
### --- init block ---
def lambda_handler(event, context):
return {
'statusCode': 200,
'body': json.dumps('Hello from Lambda!')
}code init 단계를 확실히 확인할 수 있도록 8초 동안 sleep 하도록 구성하였습니다 (lambda의 초기화 timeout은 10초이기 때문에 이보다 짧아야 합니다)
lambda는 function URL을 통해서 간단하게 5초 단위로 무제한 호출하였습니다
import time
import requests
while True:
response = requests.get("LAMBDA FUNCTION URL!")
print(response.text)
time.sleep(5)Lambda의 cloudwatch logstream은 하나의 lambda 환경에 해당하는데, 초기에는 당연하게도 A환경에 대해서만 START, END, REPORT 로그가 반복해서 출력됩니다.
# 편의상 logstream 이름을 맨 앞에 붙여넣었습니다
A | START RequestId: ...
A | END RequestId: ...
A | REPORT RequestId: ...
...
...
...
A | START RequestId: ...
A | END RequestId: ...
A | REPORT RequestId: ...
...
...
...재밌는점은 2시간정도가 지나면 확인할 수 있습니다.
# 편의상 logstream 이름을 맨 앞에 붙여넣었습니다
A | START RequestId: ...
A | END RequestId: ...
A | REPORT RequestId: ...
B | INIT_START Runtime Version ...
B | 현재 시간
B | Lambda Started
A | START RequestId: ...
A | END RequestId: ...
A | REPORT RequestId: ...
갑자기 중간에 B Logstream이 생겨납니다.
A | START RequestId: ...
A | END RequestId: ...
A | REPORT RequestId: ...
B | START RequestId: ...
B | END RequestId: ...
B | REPORT RequestId: ...
...그러더니 갑자기 요청이 A환경에서 B환경으로 넘어갑니다. lambda 환경이 blue/green 방식으로 교체되는 것입니다
물론 이 코드에서 lambda 환경이 백그라운드 상에서 교체되는것 자체는 문제가 없습니다.
하지만 문제를 유발하는 코드를 고의적으로 작성해보겠습니다.
import json
import time
im_slow = None
def slow_generator():
time.sleep(10)
return "foo"
def lambda_handler(event, context):
global im_slow
if im_slow is None:
im_slow = slow_generator()
return {
'statusCode': 200,
'body': json.dumps(im_slow)
}lambda의 handler 블럭안에 있는 코드가 lazy하게 global variable인 im_slow를 생성하고 재활용하는 코드입니다.
이러한 코드는 init code 단계에서는 함수 선언만 하기 때문에 im_slow는 None로 초기화 된 상태입니다.
그리고 실제로 INIT_START가 끝난 이후 첫 요청에 대해서 im_slow를 생성하므로 (lazy initilalize) 10초의 시간이 걸리게 됩니다.
Conclusion
lambda의 handler 코드가 global varialbe을 handler 코드에서 lazy initilalize하는 경우 예상치 느린 latency가 발생하는것을 확인할 수 있습니다.
그리고 이 문제는 lambda를 concurrency를 설정한 경우 lambda의 blue/green update로 인해 더 잦게(경험적으로 2시간내외) 발생하는것을 확인할 수 있습니다.
이러한 람다의 실행 구조를 이해하고 lambda 함수를 작성하면 운영상 생길 수 있는 문제점을 예방할 수 있을것입니다.
