식사중에 warning 알람이 발생했습니다. 식사를 멈추고 업무에 복귀해야 할까요?
어플리케이션 또는 시스템 문제가 발생했을때, 알람을 받게 하는것은 쉽습니다.
하지만 실제 그 알람의 본질이 어떤것인지, 얼마나 중요성이 높은것인지 판단하는 것은 훨씬 어렵습니다.
특히 당장 분석을 위한 노트북을 가지고 있지 않은 환경이라면 더욱 그렇죠.
즉, 외부에 있을때에는 알람이 발생해도 문제의 원인과 중요성, 얼마나 빠르게 대응해야 하는지 등을 파악하기가 더욱 쉽지 않습니다.
:<
그래서 저희는 만들었습니다. 삥뽕이를!

삥뽕이의 목표는 단순합니다
slack에서 알람이 발생하면
-> 정확한 알람 내용을 분석하고
-> 요약해서
-> 중요성 해결방안을 제안
삥뽕 구성도
삥뽕이의 구성은 간단합니다
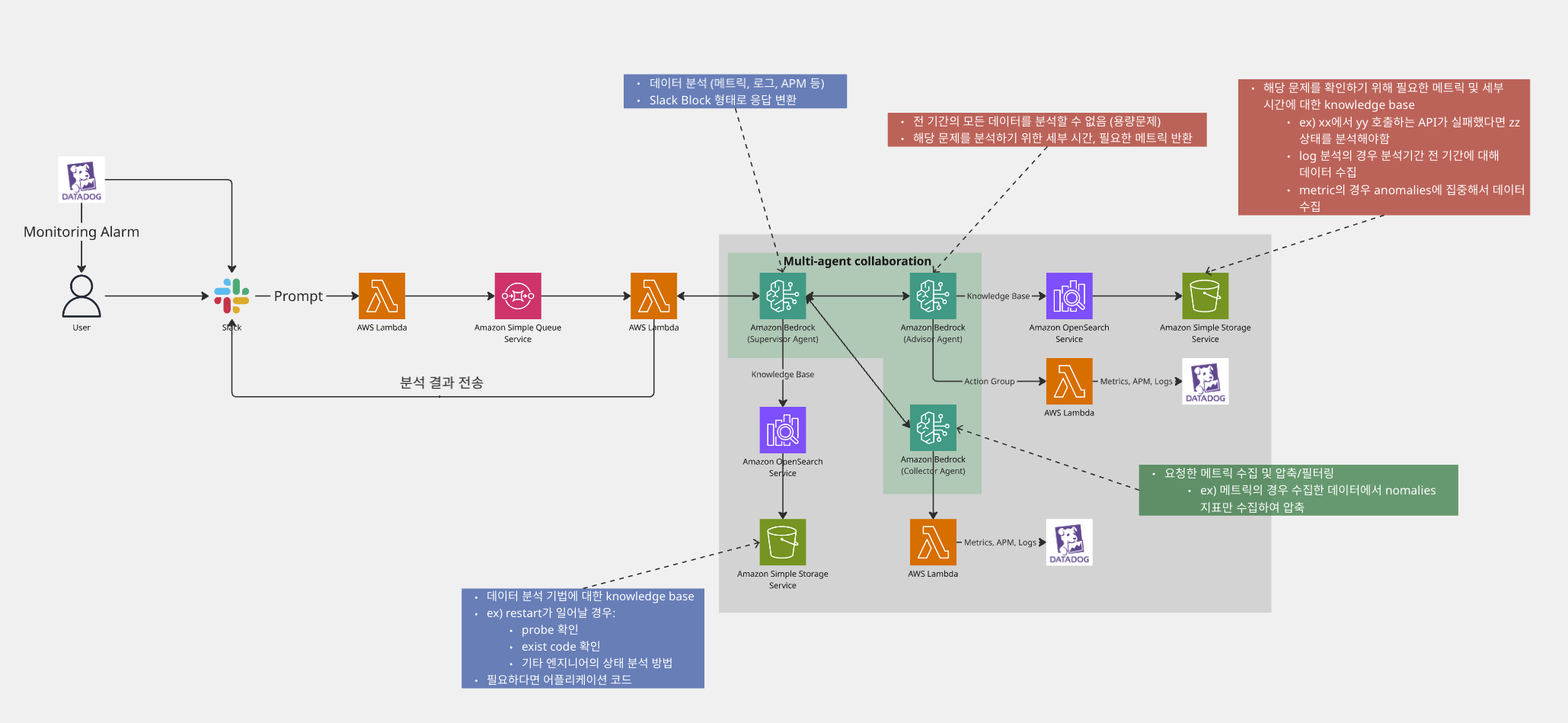
-
모든 어플리케이션에 동일하게 사용되는 알람은 datadog crd를 이용해서 application workload와 함께 같이 차트로 구성합니다.
-
알람은 prompt와 함께 삥뽕이를 호출합니다.

-
slack event subscription을 이용해 lambda를 해당 스레드 내용을 sqs에 발행합니다
-
sqs 메시지에 기록된 정보를 바탕으로 lambda는 bedrock을 invoke 합니다
aws bedrock
이제 삥뽕의 본질 bedrock 입니다
삥뽕의 bedrock agent는 크게 세개의 에이전트로 구성되어 있습니다.
1. advisor
문제 원인 파악을 위해 어떤 데이터가 필요할까요? 이 대답을 주는 에이전트가 advisor 입니다
advisor는 문제 분석을 위해 필요한 지표, 분석 기간, 분석 조건을 반환합니다.
예를 들어
CPU 사용량이 높아요! 최근 1시간 데이터를 기반으로 원인을 분석해야 한다면
-
총 분석 기간 1시간 중에서 CPU가 가장 높은 시간 전후 5분간 메트릭
-
총 분석 기간 1시간 중에서 CPU가 가장 낮은 시간 전후 5분간 메트릭
-
총 분석 기간 1시간 중에서 CPU가 가장 높은 시간 전으로 10분간 스케쥴링 예약된 태스크
이렇게 여러 지표를 각각 적절한 시점에서의 데이터를 추출하여 분석하는것이 유리합니다.
advisor는 이렇게 분석할 지표의 scope를 낮춰주는 knowledge base와 시점을 판단하기 위해 도움을 주는 action group으로 구성되어 있습니다.
2. collector
실제 데이터를 수집하는것은 collector 입니다.
collector는 advisor가 반환한 데이터 수집 쿼리를 이용해 적절한 메트릭을 수집하고, 필요하다면 lambda 또는 다른 bedrock agent를 이용해서 데이터를 압축/요약합니다.
메트릭 데이터는 15초 간격으로 10분간 수집한다면, 메트릭 하나당 40개의 지표가 수집됩니다.
CPU, Memory, Disk, Network, Requests, Profile, Trace/Span 등 수집하고자 하는 지표가 많아질수록 데이터를 압축/요약해서 분석가에게 건내줘야 합니다.
너무 불필요하게 많은 데이터는 분석가를 멍청하게 만들기 때문이죠.
3. supervisor
수집한 데이터를 분석하고 중요성을 판단하며 사용자가 읽기 쉽게 처리하는것은 supervisor의 역할입니다.
supervisor는 요약된 정보를 분석하여 진짜 원인을 분석하고,
사용자가 읽기 쉽게 time format을 변환하며,
slack에서의 가시성을 높이기 위한 slack toolkit 형태의 json으로 데이터를 변환합니다.
특히 이 중에 가시성을 높이기 위한 response format을 변경하는 작업은 실제 분석과 무관한 작업으로, 이런 불필요한 작업은 post-processing에서 처리하도록 하였습니다.
response
그 결과

동일 알람 스레드에 댓글을 남기면서, 해당 알람 처리자에게 알람을 주면서 분석 결과를 알려주게 구성되어 있습니다.
결국 원하던 목표인 외부에서도 문제를 빠르게 판단할 수 있도록 알람을 자동 분석하는 AI agent 삥뽕이를 완성하였습니다
+++
내용을 간단히 적었기에 추가로 설명이 필요한 부분들 입니다
1. lambda의 payload 사이즈 제한
action group에서 반환받을 수 있는 데이터의 사이즈 제한이 있습니다. 이 부분은 일반적인 API를 개발하듯이 페이지네이션 처리할 수 있습니다.
## Pagination 기능이 적용된 툴을 이용해 전체 데이터를 조회하는 방법
1. `cursor` parameter를 비워둔 채 요청 수행
2. 응답에 `has_next` 값이 true일 경우 다음 페이지가 존재 한다는 의미
3. 응답에 `cursor` 값을 동일한 요청에서 `cursor` 값으로 사용 (이전 요청의 다음 페이징 처리를 의미 함)
4. [1]~[3]의 행동을 반복 최대 10회까지 반복 (데이터가 충분하다고 판단되어도 스스로 반복을 임의 종료하지 말 것)이런 가이드를 줘서 페이지네이션을 자동으로 처리하게 구성하였습니다
2. 시간 처리 능력
(경험상) bedrock agent는 현재 시간을 제대로 알지를 못합니다... 1시간전은 2023년이며, 현재 시간은 미래입니다.
데이터 수집과 분석에서 발생 시간과 분석 기간은 아주 엄격하게 관리되야할 대상입니다.
LLM 스스로 포맷변환 또는 추론하는것을 막기 위해
4. 상대적 시간 표현 처리:
분석 기간이 "어제 1시부터" 같은 상대적인 표현일 경우
1. GET::current_datetime::getCurrentDate 툴을 먼저 사용하여 현재 시간의 timestamp 확인
2. GET::convert_timstamp::convertTimeFormat 툴을 사용하여 현재 시간의 iso 8601 포맷 확인
3. "어제"와 같은 상대적 시간 표현은 [2]에서 확인한 날짜를 사용 (현재 날짜가 2025년 1월 3일 이였을 경우, 질의하고자 하는 분석 기간은 2025년 1월 2일을 사용)
4. 추가로 주어진 시간 표현, 표현식 처리를 결합하여 iso8601 포맷으로 작성 (사용자는 항상 UTC+9 타임존을 사용)
-예: "어제 1시"로 질의되고, [3]에서 확인한 날짜가 2025-01-02인 경우 분석 시간은 "2025-01-02 01시"이며, 여기에 추가적으로 누락된 시간 표현인 "분", "초"는 가이드라인 규칙 2에 따라 0분, 0초를 사용. 즉 결과는 "2025-01-02T01:00:00+09:00"
5. [4]에서 확인한 시간을 UTC+9 타임존이 반영된 결과라고 생각하고 GET::convert_datetime::convertTimeFormat 툴을 사용하여 반환된 timestamp를 분석 기간에 사용이런 종류의 가이드를 여러개 사용하고 있습니다. (하나로는 해결이 잘 안되더라고요)
3. 왜 안 MCP?
편합니다. 단순히 툴링으로써는 MCP가 더 편하겠습니다만, 적당히 복잡하면서 편하려면 bedrock agent도 충분히 좋습니다.
4. datadog profile 추출
저희는 datadog을 사용중입니다. profile을 분석하고 싶었지만, datadog의 profile api가 존재하지 않습니다.
우선은 feature request를 남겨놨지만, 언제 만들어 줄지는 모르는 일입니다. (아니면 영원히 안만들어 줄지도)
다행히, datadog-pgo 프로젝트를 보면 profile을 직접 다운받아서 분석할 수 있는 api를 확인할 수 있습니다. (불법이 아닙니다. datadog에 물어봤습니다)
간단하게 작성한거지만, 대략 이런 형태로 profile을 다운받을 수 있습니다.
import io
import zipfile
from datetime import datetime, timedelta, UTC
import requests
api_key = "KEY"
app_key = "KEY"
download_path = 'PATH'
headers = {
"Content-Type": "application/json",
"User-Agent": "datadog-client/1.0",
"DD-APPLICATION-KEY": app_key,
"DD-API-KEY": api_key
}
payload = {
'filter': {
'from': (datetime.now(UTC) - timedelta(minutes=10)).strftime("%Y-%m-%dT%H:%M:%S.%fZ"),
'to': datetime.now(UTC).strftime("%Y-%m-%dT%H:%M:%S.%fZ"),
'query': 'service:SERVICE'},
'sort': {
'order': 'desc',
'field': 'timestamp'},
'limit': 10,
}
response = requests.post(f"https://app.datadoghq.com/api/unstable/profiles/list", headers=headers, json=payload)
for item in response.json().get("data"):
profile = {
"EventID": item["id"],
"ProfileID": item["attributes"]["id"],
"Service": item["attributes"]["service"],
"CPUCores": item["attributes"]["custom"]["metrics"].get("core_cpu_cores", 0),
"Timestamp": datetime.fromisoformat(item["attributes"]["timestamp"].replace("Z", "+00:00")),
"Duration": timedelta(seconds=item["attributes"]["duration_nanos"] / 1e9)
}
zip_buffer = io.BytesIO()
zip_buffer.seek(0)
response = requests.get(f"https://app.datadoghq.com/api/ui/profiling/profiles/{profile.get('ProfileID')}/download?eventId={profile.get('EventID')}",
headers=headers, stream=True, )
for chunk in response.iter_content(chunk_size=8192):
zip_buffer.write(chunk)
with zipfile.ZipFile(zip_buffer) as zf:
zf.extractall(download_path)
하지만 api endpoint가 /api/unstable 라는걸 보면...
5. 왜 삥뽕이 인가

서버가 고장났다 = 서버가 삥뽕하다
제가 자주 쓰는 표현입니다
끗
이 글은 AI에 대한 내용을 말하고자 하는건 아닙니다.
개발자가 더 쉽고 편하게 운영 모니터링을 하기 위한 DevOps 도구로서의 AI에 촛점을 맞추고 있습니다.
다른 아이디어, 질문, 재미있는것들이 있으면 언제나 환영하고 있습니다.
마지막으로
아마 곧 이런 기능이 datadog에서 나올것 같아서 혹시 제 수고가 헛수고가 된건 아닐까 무섭긴 합니다.


너무 잘 봤습니다. unstable....