이 글을 적고싶지 않았습니다. 이런 일을 겪고 싶지 않았습니다
이 글에서는 고통을 겪은 히스토리만 나옵니다. 해결법에 대한 아이디어는 다음 포스팅에 작성되어 있습니다.
문제의 시작
Karpenter를 도입한 이후 어느날 이벤트가 발생했습니다. 개발자들에게 별도로 공지는 없는 작은 이벤트였고 자연스럽게 컴퓨팅 리소스들은 스케일아웃되고 자동으로 대응되고 있었습니다.
그런데 배치성 업무를 담당하는 어플리케이션이 갑자기 실행되지 못하는것을 발견했습니다.
이벤트가 종료된 이후에도 마찬가지였고 문제 발생 전후 짧은 기간동안 바뀐 구성은 karpenter의 사용 유무 뿐이였습니다.
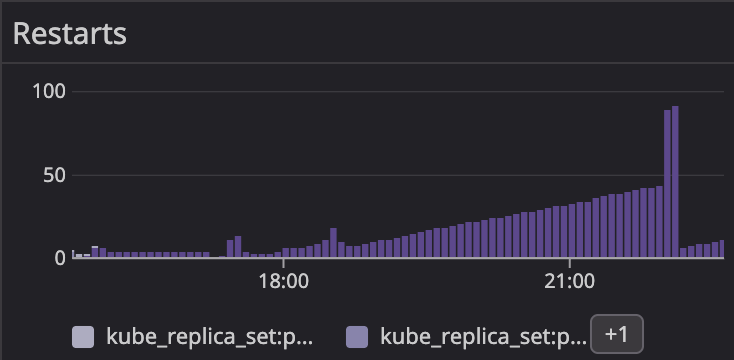
다행히 다른 replica는 정상적으로 실행되어 서비스가 중단되는 현상까지는 발생하지 않았습니다.
문제 분석
해당 컨테이너는 spring boot로 구성되어 있습니다. 실행시 DB에 접속을 시도하며 DB 접속을 실패하기 때문에 서비스 실행 자체가 안되서 restart 하고 있었습니다.
이런식의 에러입니다
The last packet sent successfully to the server was 0 milliseconds ago. The driver has not received any packets from the server.
...
...
Caused by: software.aws.rds.jdbc.mysql.shading.com.mysql.cj.exceptions.CJCommunicationsException: Communications link failure
...
...
Caused by: java.net.SocketException: Connection attempt exceeded defined timeout.우선 확실해 보이는건 어떤 종류의 네트워크...뭔가 뭔가 라고 생각했습니다.
문제 재현
재현을 하고자 했으나... 뭔가 이상합니다. 아래에 있는 설정을 켰다가 껏다가 했을때 모두 재현이 되다가 안되다가 멋대로입니다
-
노드 타입 변경 (c5a <-> c5n ...)
-
노드 유형 변경 (karpenter node가 아닌 managed node)
-
coredns를 fargate로 분리
- fargate에서 실행되는 coredns를 datadog으로 모니터링 하는 방법은 나중에 게시하겠습니다
-
동일한 노드의 여러 파드중에서도 일부 파드에서만 문제 발생
-
동일한 노드에서도 발생 하기도하고 안하기도 하고...
-
클러스터 변경 (운영에서는 발생, 다른곳에서는 발생하지 않음[?])
-
특정 데몬셋(datadog agent)를 제외
-
istio 등 잡다한 네트워크 레이어 제거
문제는 이 모든것들이 어떨때는 재현이 되고, 어떨때는 안되는 재현이 안되는... 재현 신뢰성이 낮은 상황이 발생했습니다.
이 때문에 정확하게 예측가능한 재현이 가능한 상황을 찾아내기 위해 거의 2주(!) 에 가까운 시간을 소모했습니다.
사실 결과를 알고보면 왜 재현이 됬다가 안됬다가... 전혀 상관 없는 다른 pod 때문에도 왜 됬다가 안됬다가 하는지 알 수 있습니다 8_8
문제의 이유
해당 서비스의 QOS는 burstable입니다. cpu limit가 cpu request가 높은 상황으로 구성되어 있습니다.
대부분의 어플리케이션은 실행시 필요한 리소스의 양이 실행 후 안정된 리소스의 요구치보다 아주 높습니다.
라이브러리를 로드하고, 쓰레드를 생성하고, 초기 DB 연결을 구성하거나 하는 초기화 작업이 꽤 높은 리소스를 요구하기 때문입니다.
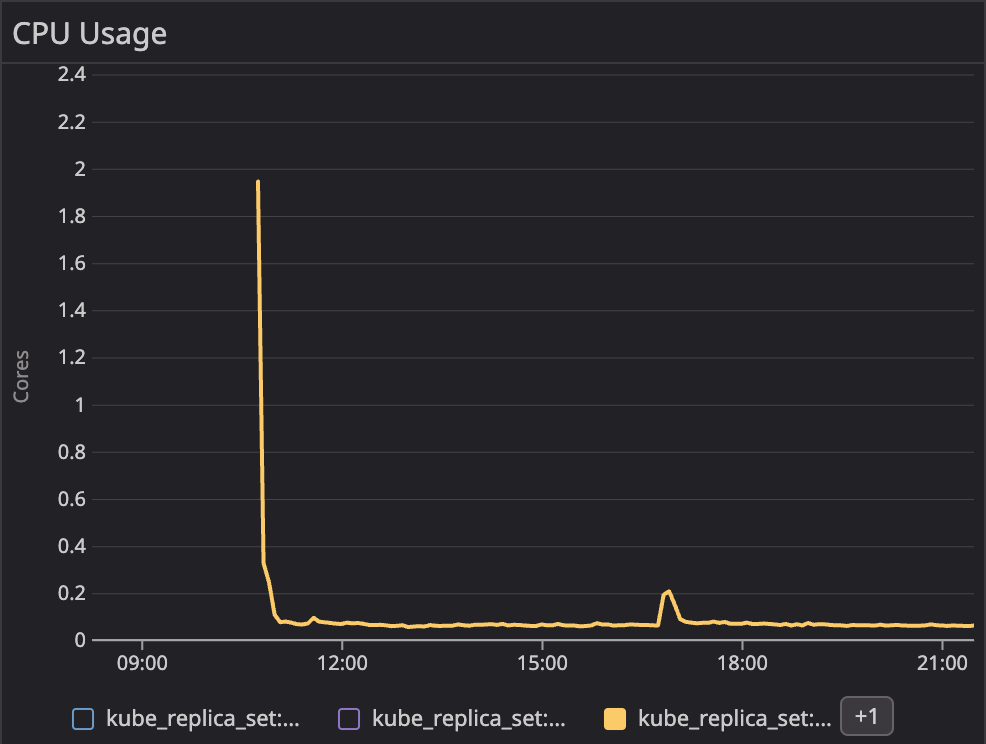
서비스의 QOS를 burstable로 할것이냐 guaranteed로 할것이냐는 늘 논쟁 가능한 부분입니다.
하지만 저런 CPU 사용량을 보인다면 burstable로 구성하고 싶어집니다. 그리고 저희 문제가 되는 그 워크로드가 바로 burstable 이였습니다.
이러한 설정에는 전혀 문제가 없습니다. 하지만 karpenter는 bin-packing을 잘 계산해줍니다.
karpenter는 필요한 리소스에 맞는 가장 가격 합리적인 노드를 선택합니다. 그러다보니 이 선택이 가장 빈패킹 잘하는, 즉 노드의 사용량을 100%로 맞추는 행위를 유발하기도 합니다.
이러면 Pod들은 burstable이라고 하더라도 남는 리소스가 없기 때문에 guaranteed 처럼 작동합니다.
이로 인해 예상보다 낮은 CPU 할당과 그로 유발되는 throttling이 발생했습니다.
결국 네트워크 문제가 아니라 성능 문제였던 것입니다. 그러면 위에 있었던 재현 의문증이 모두 해소됩니다.
-
해당 노드에 실행된 워크로드의 cpu limit 비율에 따라
-
데몬셋 등을 삭제하면 노드 자체의 여유 CPU가 생김
문제가 해소되는지 테스트하기 위해 DB connection timeout을 10초로 늘리고 다시 재현되는지 테스트 해봤는데... 재현되지 않습니다!
문제를 해결했습니다.
burstable 이였던 pod의 CPU를 높여서 guaranteed로 변경하였고 모든 문제는 해결되었습니다.
왜 이렇게 문제 해결이 오래걸렸는가에 대한 변론
데브옵스 엔지니어로서 저도 지표는 미친듯이 봅니다.
온갖 네트워크 지표, 어플리케이션 지표, 노드 및 파드 지표 등등 별의 별 지표는 다 봤습니다.
하지만 슬프게도 초기화 작업에서 커넥션이 몇초나 걸리는지는 정확하게 볼 수 있는 지표가 없었습니다.
쓰로틀링도 원래 초기에 약간 발생하는 상황이였습니다.
어플리케이션의 connection timeout에 설정된 시간보다 살짝 빠르게 connection이 맺어지는 아슬아슬한 상황으로 서비스가 지속되고 있었던겁니다.
그 아슬아슬한 상황에서 약간의 CPU 마저 빼앗아 가버렸으니 실행이 성공하기도/실패하기도 하는거였습니다.
그렇다면

이런 상황을 방지할 순 없을까요?
고양이와 박스처럼, 미배치된 파드들이 딱 맞는 노드에 배치됨으로 생기는 burstable이 guaranteed 처럼 작동하는 현상 그리고 그로 인해 생기는 성능저하는 막을 수 없을까요?
request를 limit만큼 올려서 비용을 일부 포기하고 워크로드의 안정성을 갖는것만이 방법일까요?
효과적인 방법을 다음글에서 소개드립니다.

4개의 댓글

Hoxy... Admission Controller를 이용해 노드 프로비저닝 초반에 혼자 자원을 다 쓰면! 해결이 가능할까요? 다음편이 기대되네요. 이제는 링크드인이 제일 재밌는거같아요 ㅋㅋㅋ
저도 블로그 글 쓸때마다 올려봐야겠어요
ㅎㅎ 글 재밌게 봤습니다. 어떻게 해결하셨는지 궁금하네요~ 2편 꼭 써주세요!
저는 cpu,memory 과부하 걸리면 hpa로 Pod 개수 늘려서 node 개수 늘리는 방법을 사용할 것 같네요!
리소스 낭비 없이 사용하려면 여러 조치를 취해야겠지만..ㅋㅋㅋ