이 전 포스팅의 연장입니다.
무엇이 문제인가
대부분의 어플리케이션 Pod들은 초기화 단계에서 높은 CPU를 요구하는데 반해, 그 이후 과정에서는 낮은 CPU를 요구합니다.
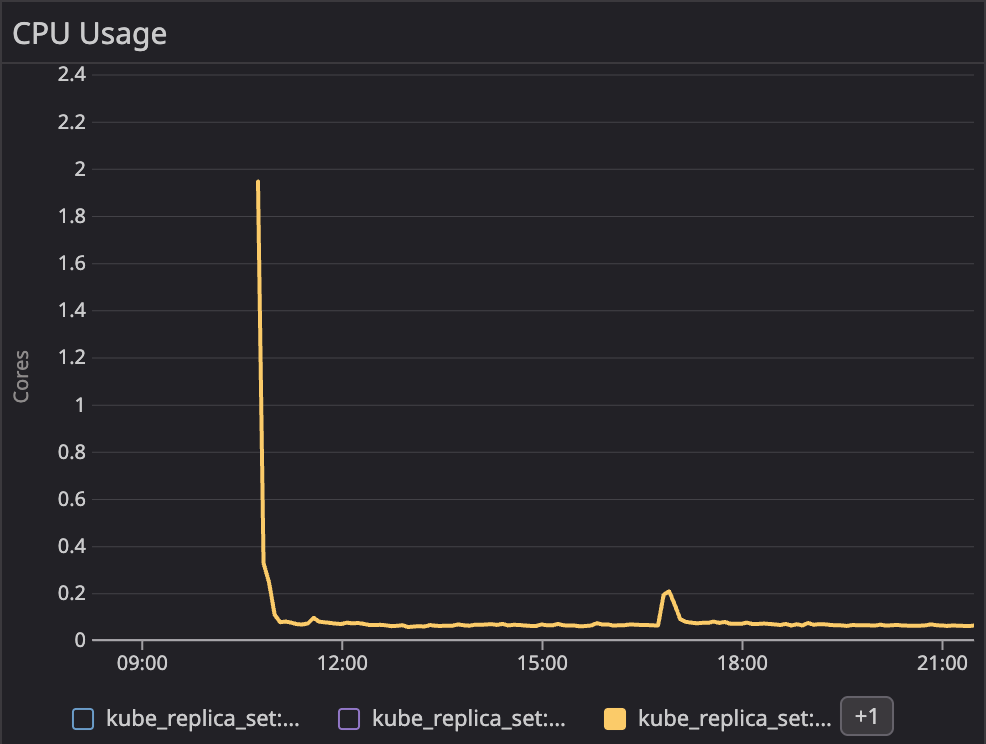
그렇다면 Pod의 requests를 어떻게 설정할 수 있을까요?
- 초기 높은 CPU를 기준으로 삼으면
-> over provisioning에 대한 효과로 불필요한 비용이 지출됩니다. - 운영 기준의 낮은 CPU를 기준으로 삼으면
-> 초기화 단계에서 너무 오랜 시간이 소요되고 워크로드에 따라 아예 실행되지 못하는 상황도 발생 가능합니다. - burstable QOS를 설정하여 운영기준으로 request, 초기화 기준으로 limit를 설정하면
-> node에 request 기준으로 꽉차게 pod가 스케쥴링 된 경우 guaranteed 같은 설정이 되어서 오히려 예상치 못한 (2)의 상황으로 전환되어 더욱 복잡해 질 수 있습니다.
심플 아이디어
간단한 해결법은 pod의 request를 스케쥴링 단계 및 초기화 단계 그리고 트래픽을 받기 전까지의 request는 높게, 그 이후에는 낮게 설정할 수 있다면 해결할 수 있겠습니다.
그런데 pod의 request는 수정이 불가능한 값입니다.
쿠버네티스 1.27버전 전까지는요!
이제 새로운 기능을 맛봅시다!
Pod resize policy
kubernetes pod의 resize policy는 1.27버전에서 알파로 추가된 기능입니다.
pod의 requests, limits를 재시작없이 또는 재시작을 동반한 업데이트를 할 수 있도록 지원합니다.
현재 기준으로 아직 alpha 단계의 feature이므로 feature gate를 활성화 해줍니다. feature명은 InPlacePodVerticalScaling 으로 등록되어 있습니다
apiVersion: kubeadm.k8s.io/v1beta3
kind: ClusterConfiguration
apiServer:
extraArgs:
feature-gates: "InPlacePodVerticalScaling=true"이제 테스트용 nginx pod를 하나 실행하겠습니다.
apiVersion: v1
kind: Pod
metadata:
name: resizable-nginx
spec:
containers:
- name: nginx
image: nginx
resizePolicy:
- resourceName: cpu
restartPolicy: NotRequired
- resourceName: memory
restartPolicy: RestartContainer
resources:
limits:
memory: "200Mi"
cpu: "700m"
requests:
memory: "200Mi"
cpu: "700m"pod 상태를 확인해보면
$ k get po resizable-nginx -o jsonpath='{.spec.containers[0].resources}' | jq
{
"limits": {
"cpu": "700m",
"memory": "200Mi"
},
"requests": {
"cpu": "700m",
"memory": "200Mi"
}
}$ k describe po resizable-nginx
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 7m9s default-scheduler Successfully assigned default/resizable-nginx to worker1
Normal Pulling 7m9s kubelet Pulling image "nginx"
Normal Pulled 7m6s kubelet Successfully pulled image "nginx" in 2.149202326s (2.149223074s including waiting)
Normal Created 7m6s kubelet Created container nginx
Normal Started 7m6s kubelet Started container nginx
pod에서 설정한대로 원하는 수치로 생성된것이 확인 됩니다.
이제 patch를 통해 cpu를 조정해보겠습니다.
$ k patch pod resizable-nginx --patch '{"spec":{"containers":[{"name":"nginx", "resources":{"requests":{"cpu":"800m"}, "limits":{"cpu":"800m"}}}]}}'$ k get po resizable-nginx -o jsonpath='{.spec.containers[0].resources}' | jq
{
"limits": {
"cpu": "800m",
"memory": "200Mi"
},
"requests": {
"cpu": "800m",
"memory": "200Mi"
}
}$ k describe po resizable-nginx
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 9m19s default-scheduler Successfully assigned default/resizable-nginx to worker1
Normal Pulling 9m19s kubelet Pulling image "nginx"
Normal Pulled 9m16s kubelet Successfully pulled image "nginx" in 2.149202326s (2.149223074s including waiting)
Normal Created 9m16s kubelet Created container nginx
Normal Started 9m16s kubelet Started container nginxcpu의 restartPolicy는 NotRequired이기 때문에 재시작 없이 resource의 requests와 limits가 변경되었습니다!
이제 restartPolicy가 RestartContainer로 지정된 memory를 patch 해보겠습니다.
$ k patch pod resizable-nginx --patch '{"spec":{"containers":[{"name":"nginx", "resources":{"requests":{"memory":"400Mi"}, "limits":{"memory":"400Mi"}}}]}}'$ k get po resizable-nginx -o jsonpath='{.spec.containers[0].resources}' | jq
{
"limits": {
"cpu": "800m",
"memory": "400Mi"
},
"requests": {
"cpu": "800m",
"memory": "400Mi"
}
}Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Scheduled 10m default-scheduler Successfully assigned default/resizable-nginx to worker1
Normal Pulled 10m kubelet Successfully pulled image "nginx" in 2.149202326s (2.149223074s including waiting)
Normal Pulling 31s (x2 over 10m) kubelet Pulling image "nginx"
Normal Killing 31s kubelet Container nginx resize requires restart
Normal Created 29s (x2 over 10m) kubelet Created container nginxcpu와 동일하게 patch는 되지만 restart event가 발생하는것을 확인할 수 있습니다.
kyverno
resize policy를 이용하여 pod의 resource를 재시작 없이 수정할 수 있는것은 확인했습니다.
하지만 언제, 어떻게 수정하냐에 대한 문제가 남아있습니다.
직접 컨틀롤러, CRD 등을 개발해서 이 기능을 구현할 수도 있겠지만 더 쉬운 방법인 kyverno를 사용하겠습니다.
kyverno를 쿠버네티스 리소스의 유효성 검사, 변경, 생성 등을 제공하는 정책엔진 (policy engine)입니다.
(이 포스팅에서는 분량상의 문제로 kyverno를 자세하게 다루지는 않습니다.)
helm chart로 kyverno를 설치하겠습니다.
helm repo add kyverno https://kyverno.github.io/kyverno
이때 사용할 기본 values에서 excludeGroups을 수정합니다.
config:
excludeGroups: []기본값은 system:nodes를 제외하게 되어있습니다. 하지만 pod의 probe 등을 처리하는 컴포넌드는 node의 kubelet이고 kubelet은 system:nodes Group을 사용하게 되어있습니다. 저희는 kubelet event를 처리해야하기 때문에 excludeGroups 에서 system:nodes를 제외합니다.
이제 kyverno 설치를 마무리 합니다.
helm upgrade -install kyverno kyverno/kyverno -n kyverno --create-namespace -f values.yamlkyverno가 pod를 직접 수정하기 때문에 적절한 clusterrole이 필요합니다.
하지만 기본으로 생성된 clusterrole을 수정하는것은 이벤트 손실을 유발할 수 있으므로, 새롭게 clusterrole을 생성하는것이 권장됩니다.
pod resource를 수정하기 위한 권한을 추가합니다.
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
labels:
app.kubernetes.io/component: background-controller
app.kubernetes.io/instance: kyverno
app.kubernetes.io/part-of: kyverno
name: kyverno:resize-pods
rules:
- apiGroups:
- ''
resources:
- pods
verbs:
- patch
- updateresize policy는 resource를 수정할 수 있게 하는 feature입니다.
문제는 QOS는 resource와는 약간 별개의 값이기 때문에 guaranteed로 pod를 구성하였다면 request를 낮춰서 burstable로 바꾸는 행위는 할 수 없습니다.
이점에 유의하여 위에서 작성한 nginx pod manifest를 일부 수정합니다.
추가적으로 pod가 ready된 이후에 리소스 변경이 일어나는지 확인하기 위해 probe를 추가하였습니다.
resources:
limits:
memory: "200Mi"
cpu: "700m"
requests:
memory: "200Mi"
cpu: "500m"
readinessProbe:
httpGet:
path: /
port: 80
initialDelaySeconds: 60그리고 pod가 ready상태가 되면 container의 cpu requests를 200m로 수정하도록 kyverno의 ClusterPolicy를 구성합니다.
apiVersion: kyverno.io/v1
kind: ClusterPolicy
metadata:
name: resize-pods
spec:
rules:
- name: resize-pods
match:
any:
- resources:
kinds:
- Pod/status
preconditions:
all:
- key: "{{request.object.status.containerStatuses[0].ready}}"
operator: Equals
value: true
mutate:
targets:
- apiVersion: v1
kind: Pod
name: "{{request.object.metadata.name}}"
patchStrategicMerge:
spec:
containers:
- (name): nginx
resources:
requests:
cpu: "200m"pod를 생성한 직후 초기화 단계에서의 상태입니다.
$ k get po resizable-nginx -o jsonpath='{.spec.containers[0].resources}' | jq
{
"limits": {
"cpu": "700m",
"memory": "200Mi"
},
"requests": {
"cpu": "500m",
"memory": "200Mi"
}
}잠시 시간이 지난 이후 pod가 ready 상태가 된 이후 동일한 명령어를 입력해보면, pod의 리소스가 변한것을 확인할 수 있습니다.
$ k get po resizable-nginx -o jsonpath='{.spec.containers[0].resources}' | jq
{
"limits": {
"cpu": "700m",
"memory": "200Mi"
},
"requests": {
"cpu": "200m",
"memory": "200Mi"
}
}이제 이 메커니즘을 이용해서 저희는 초기화 단계에 필요로 하는 높은 cpu를 기준으로 하는 pod를 구성하고, 초기화 단계 이후 cpu를 resizing 해서 pod 운영을 최적화 하는 워크로드를 구성할 수 있습니다!
한계
꽤나 우아해 보이는 이러한 구성도 한계가 있습니다.
- EKS는 alpha 버전의 feature를 지원하지 않습니다.
- Which Kubernetes features are supported by Amazon EKS?
Amazon EKS supports all generally available (GA) features of the Kubernetes API. Starting with Kubernetes version 1.24, new beta APIs aren't enabled in clusters by default. However, previously existing beta APIs and new versions of existing beta APIs continue to be enabled by default. Alpha features aren't supported.
이로 인해 적어도 EKS에서는 당장 구현하기 힘듭니다. 시간이....필요합니다....
- karpenter의 이상 현상
karpenter의 consolidation policy를 WhenUnderutilized를 사용할 경우 이상현상이 발생할 수 있습니다. (테스트 할 수 없는 상황이기에 정확하진 않습니다)
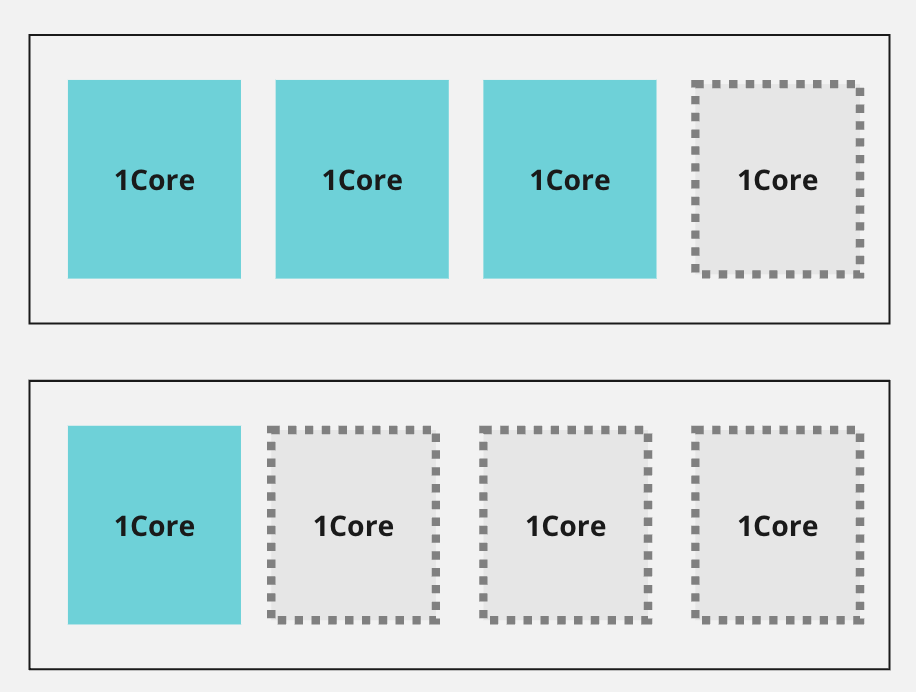
아래 그림처럼 4core 노드 2대에 각각 3core와 1core를 사용하고 있는 상황이라고 생각해 봅시다.
이 경우 WhenUnderutilized policy를 사용하고 있을 경우 karpenter는 아래에 있는 노드를 버리고 윗쪽의 노드 하나만을 사용하고자 할껍니다.
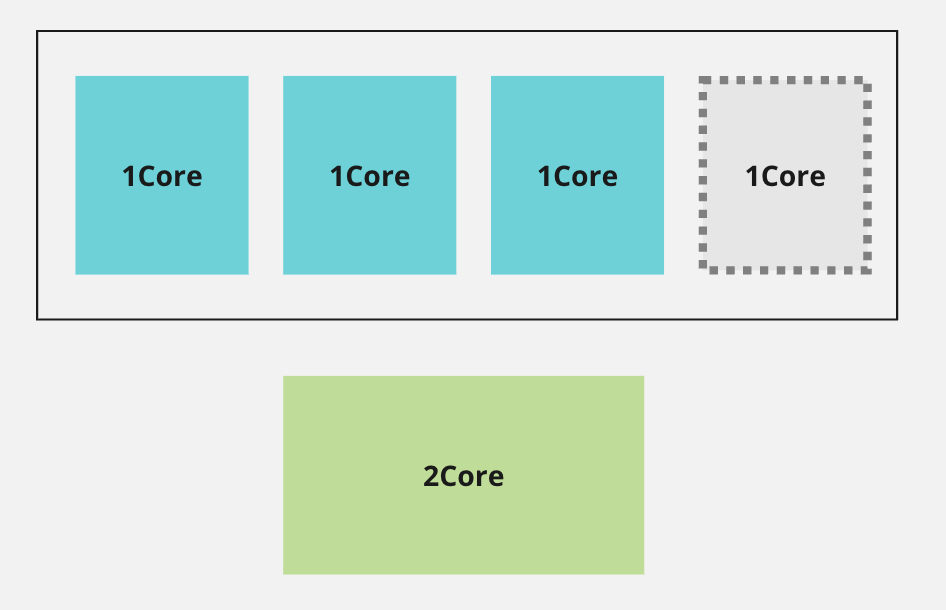
하지만 아랫쪽에 있던 1core pod가 사실 resize 되기 전에는 2core pod였다면 무슨 현상이 발생할까요? 아마 새로운 노드를 다시 요청하게 될것입니다. 그런데 또다시 안정화 단계에서 CPU 사용량이 낮아지고... 이 무한 반복이 발생할 수 있습니다.
그래도 아직 추측하건데 이 현상은 WhenUnderutilized가 아닌 WhenEmpty를 사용하면 발생하지 않지 않을까...하는 기대는 하고 있습니다.
🥸
우선 이 내용의 힌트는 karpenter contributor인 Jason Deal에게서 얻었습니다.
이 전 포스팅의 문제를 해결하기 위해 일부 예약된 자원을 통해 node를 필요한 스펙보다 더 큰 요청을 하게 하는 방식을 고려했고 그 기능을 Feature Request로 올렸습니다. [참고]
여기서 resizable resources에 대한 힌트를 얻었고 그 아이디어로 여기까지 발전할 수 있었습니다.
그리고 재밌는것은 k8s blog의 InPlacePodVerticalScaling에 대한 블로그에 example use cases로 Java processes initialization CPU requirements 를 직접적으로 언급하기도 합니다 [참고]
물론 위에 작성한 내용이 이런 현상을 모두 해결해주는 방법은 절대 아닙니다. 하지만 이런 선택지와 아이디어를 통해 더 나은 쿠버네티스 운영을 고려하는 기회가 되시길 바랍니다.
감삼당
추가
구글이 https://github.com/google/kube-startup-cpu-boost 요런걸 만드는 중입니다.
기본적으로 유사한 메커니즘입니다. 그러기에 당연히 InPlacePodVerticalScaling 를 필요로 하는것도 동일합니다.
reference
