논문 리뷰 (1) - Attention Is All You Need
원문 ➡️
https://arxiv.org/abs/1706.03762
기존의 딥러닝 모델
이전의 NLP 시퀀스 처리 모델은 주로 RNN 과 같은 순환 구조나 CNN 기반의 시퀀스 모델을 사용했다. 하지만 이러한 모델들은 앞 토큰을 처리한 후에 다음 토큰을 처리해야 하기 때문에 다음과 같은 한계들이 존재했다.
- 병렬화가 어려움
- 시퀀스가 길수록 학습이 느려지고 계산량이 많이 필요함
- 토큰을 처리한 정보들이 여러 step 을 거쳐서 전달되기 때문에 기울기 소실(vanishing gradient)가 발생해문장 간의 관계를 잡기가 어려움
이러한 한계를 해결하기 위해 제안된 것이 바로 해당 논문에서 소개하는 "Transformer"이다. 이 모델은 순환이나 합성곱 없이 Attention 만으로 시퀀스를 처리한다.
* 용어 정리
- Encoder(인코더) : 입력을 읽어 이해 가능한 내부 표현으로 바꿈
- Decoder (디코더) : 내부 표현을 바탕으로 원하는 출력을 생성
- Sequence(시퀀스) : 하나의 데이터가 아니라 순서가 있는 데이터의 나열 (Ex. 여러 단어로 이루어진 class)
Attention 이란?
Attention 메커니즘이란 기본적으로 디코더에서 출력을 만들 때 입력 전체 중에서 어디를 얼마나 참고할지 가중치를 두고 보는 방법을 말한다. 이전의 CNN과 같은 모델은 모든 토큰을 순차적으로 입력받기 때문에 문장 출력과 같이 멀리 떨어진 단어의 관계가 중요한 자연어 처리에서는 장거리 의존성이 좋지 않아 성능이 떨어진다.
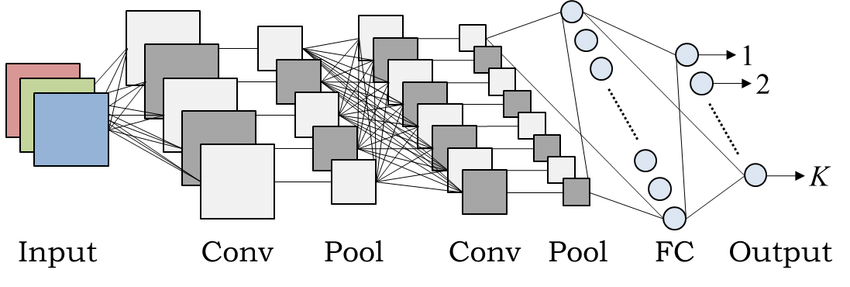
[⬆️ CNN의 구조 ]
위의 그림과 같이 CNN에서는 이전(t-1 시점)의 은닉 상태로부터 다음 시점(t)의 은닉 상태를 생성한다. 이를 CNN의 순차 계산이라고 하고, 이러한 제약 때문에 CNN을 자연어 처리에 적용했을 때 성능이 떨어진다.
하지만 Attention은 문장 전체를 한꺼번에 보고 중요한 단어에 가중치를 부과하여 선택적으로 참고한다. Self-attention(또는 intra-attention)은 하나의 시퀀스 내 서로 다른 위치들 간의 관계를 이용해 시퀀스 표현을 계산하는 메커니즘이다. 순차 계산을 배제한다는 점에서 해당 메커니즘은 독해, 추상적 요약, 텍스트 함의 등 다양한 자연어 과제에 높은 성능을 보인다.
Transformer Model Architecture
다음은 Transformer 의 전체 모델 구조이다.
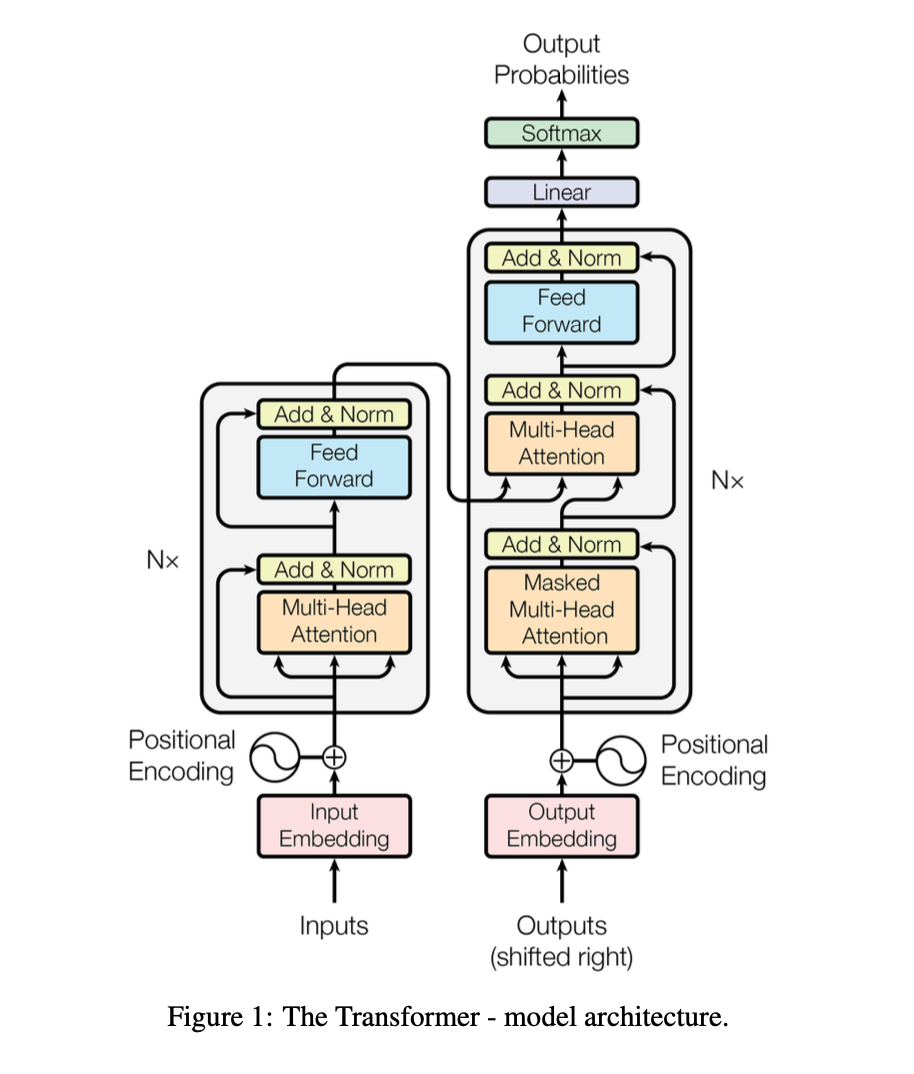
그림 왼쪽의 회색 블록은 Encoder, 오른쪽 회색 블록은 Decoder이다.
Encoder 는 총 6개(N=6)의 동일한 층을 쌓아 만든다. 한 층은 Multi-Head Self-Attention 하위 계층과, feed-forward network 하위 계층으로 이루어진다. Input Embedding 은 Multi-Head Self-Attention -> Add & Norm -> Reed Forward -> Add & Norm 구조를 6층 반복하며 통과한다. 모든 하위 계층과 임베딩 층의 출력 차원은 모두 512차원이다.
Decoder 또한 총 6개(N=6)의 동일한 층으로 구성된다. Decoder 의 한 층은 Encoder 층과 동일한 두 하위 계층에 Multi-Head Attention 이라는 새로운 하위 계층으로 구성된다.(각 계층 뒤에 역시 Add & Norm 이 붙는다.)
Decoder 는 기본적으로 출력 생성 시 현재까지 생성한 토큰들과 Encoder 출력에 대한 정보가 모두 필요하므로 두 종류의 Attention이 필요하다.(인코더보다 구조가 하나 더 복잡한 이유!)
또, Decoder 의 Self-Attention 하위 계층은 미래 위치를 보지 못하도록 마스킹한다.(Masked Self-Attention) 자세히 하자면, decoder 는 출력 문장을 만들 때 한 토큰(단어) 씩 생성한다. 현재 토큰을 예측할 때 미래 정답 토큰을 보면 안 되기 때문에 현재 토큰 이전만 참고하여 출력을 생성하도록 한다. 이 마스킹과 출력 임베딩을 한 칸 오른쪽으로 민 shifted right 구조를 결합함으로써, 위치 i에 대한 예측은 i보다 작은 위치의 알려진 출력에만 의존하도록 한다.
이제 예시를 통해 Transformer 구조를 이해해보자.
'나는 학교에 간다' 라는 문장을 'I go to school' 이라는 문장으로 번역하고자 한다. 우선 Encoder에서 문장이 토큰 단위로 쪼개져 숫자 벡터로 변환된다. Decoder에서도 현재까지 출력했던 토큰들(여기서는 I, go 까지 출력했다고 가정하자.)을 숫자 벡터로 변환한다.
이후 이 벡터들은 Positinal Encoding 을 통과한다. 이 층에서는 Embedding에 토큰 순서 정보를 더해준다. Transformer 에서는 RNN처럼 토큰들을 순서대로 읽지 않기 때문에, 각 토큰이 문장에서 몇 번째 위치인지, 앞뒤 순서가 어떤지에 대한 정보가 필요하다.
그 다음으로 Encoder 쪽의 Self-Attention 하위 계층을 통과한다. 이 층에서는 "간다" 라는 토큰이 "나는", "학교에" 를 참고하여 각 토큰을 문맥 반영 표현으로 바꾼다(각 토큰이 다른 입력 토큰을 서로 참조함) Decoder의 Multi-Head Attention(2번째 블럭) 쪽에서는 번역 토큰를 생성하기 위해 Encoder 의 현재 출력을 참고한다.
Decoder 의 맨 아래에 있는 Masked Multi-Head Attention 에서는 미래 위치를 가리는 mask 를 씌운다. I 를 예측할 때 go, to, school 을 미리 보면 안 되기 때문이다.
그럼 Attention의 연산 과정은 어떻게 될까? 해당 논문에서는 attention 을 query, key, value 라는 세 벡터 개념으로 나누어 설명한다. 자세한 개념은 아래와 같다.
- Query : 찾고 싶은 정보
- Key : 각 토큰이 가지고 있는 특징
- Value : 실제 토큰이 갖고 있는 정보
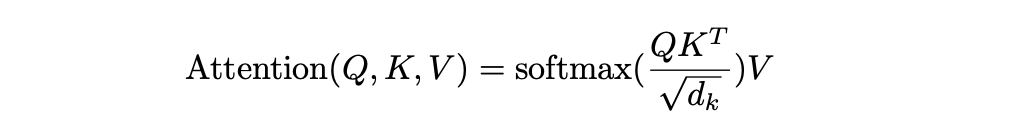
각 토큰의 embedding 벡터들은 positional encoding 을 거친 후 Self-Attention 층을 통과할 때 선형 변환을 통해 Q, K, V 행렬로 만들어진다.(각 행렬은 query 벡터, key 벡터, value 벡터로 구성) 즉, 각 토큰마다 Query 행렬, Key 행렬, Value 행렬이 생긴다. 이후 각 토큰은 자신의 query 를 다른 토큰의 key 와 비교한 후 √dk 로 나누는 scaling 을 한다. 마지막으로 해당 값을 softmax 함수에 입력하여 각 토큰을 문장 전체 토큰 정보가 섞인 벡터로 변환한다.
이러한 과정들이 6층에 걸쳐 반복되며 표현이 가공되고 Decoder 가 이전 출력 토큰과 Encoder 출력을 참고하여 다음에 출력할 단어 중 가장 확률이 높은 것을 선택한다.
결론
본 논문에서는 Encoder-Decoder 구조는 유지하되, CNN이나 RNN 에서 사용되던 순환 층을 제거하고 Multi-Head Self-Attention 으로 대체한다. 해당 모델(Transformer)는 기계 번역 과제에서 기존의 순환 또는 합성곱 층 기반 구조의 모델보다 훨씬 빠른 학습 속도와 성능을 보였으며, 다른 경쟁 모델들보다 낮은 학습 비용을 사용했다. 저자는 텍스트 외의 이미지, 비디오, 오디오처럼 큰 입력과 출력을 효율적으로 다룰 수 있는 local/restricted attention 메커니즘이 중요한 후속 연구 목표가 될 것이라고 밝혔다.
