논문 리뷰(2) - TurboQuant: Online Vector Quantization with Near-optimal Distortion Rate
원문 ➡️ https://arxiv.org/abs/2504.19874
Background
Llama-3 같은 LLM 은 긴 문서를 처리할 때 이전에 계산한 Key, Value vector 를 KV cache 에 저장해두고, 새로운 토큰이 올 때마다 저장된 모든 Key 와 해당 토큰의 inner product 를 계산하여 유사성을 판단한다. 그래서 LLM은 긴 문맥을 처리할수록, 누적하여 사용될수록 embedding 저장량이 폭발적으로 증가하여 KV cache로 인한 메모리 병목과 추론 속도가 급격하게 나빠지는 문제가 발생한다. 이런 문제를 해결하기 위해 연구되고 있는 기술이 Vector Quantization(벡터 양자화)이다. 하지만 고차원 벡터를 압축하는 VQ 알고리즘은 정보 손실인 distortion(왜곡)이 발생할 수밖에 없다. 그래서 최근 이 distortion 을 어떻게 줄일 수 있을지에 대한 연구가 활발히 이루어지고 있다. 이 논문에서는 distortion(왜곡)을 최소화하여 최적 성능을 달성한 Vector Quantization Algorithm "TurboQuant" 를 제안한다.
Vector Quantization(VQ)
벡터 양자화(Vector Quantization)란?
벡터 양자화는 딥러닝 모델의 weight vector 나 LLM 의 embedding vector 같은 고차원 벡터들을 압축하는 기술을 말한다. 벡터 양자화는 'Codebook'를 통해 주로 이루어진다.
Codebook
Codebook이란, 각 비트열에 맞는 대표 벡터 목록을 통해 원본 벡터를 치환하는 것이다. 예를 들어, 아래와 같은 4bits Codebook 이 있다고 해 보자.
00 -> [0.1, 0.9, 0.2]
01 -> [0.8, 0.1, 0.7]
10 -> [0.5, 0.5, 0.5]
11 -> [0.2, 0.3, 0.8]
input 으로 [0.79, 0.12, 0.69] 라는 벡터가 들어오면, 이 벡터는 Codebook에서 가장 유사한 벡터를 의미하는 bit 인 01 로 압축된다. 원래 3개의 float인 총 96bits 의 데이터가 2bits 로 압축된 것이다. 이후 해당 벡터가 복원될 때에는 '01' 비트열에 따라 [0.8, 0.1, 0.7] 로 복원된다. (여기서 원본과 차이가 생기는데, 이를 distortion(왜곡)이라고 한다.)
그럼 distortion 은 어떻게 줄일 수 있을까? 크게 두 가지 방법이 있다.
첫 번째로, Codebook 의 비트 수를 증가시키는 것이다. 2bit Codebook 은 대표 벡터 4개로 나타내지고, 4bit Codebook 은 16개, 8bit Codebook 은 256 개로 나타낼 수 있다. 이렇게 비트 수를 증가시키면 원본 벡터와의 오차를 줄일 수 있다.
두 번째는 Codebook을 데이터 분포에 맞게 배치하는 것이다. 대표 벡터들을 실제 데이터가 많이 몰리는 곳에 집중 배치하면 MSE(평균 오차)가 줄어든다. TurboQuant 가 집중한 것이 바로 이 부분이다. TurboQuant 는 Lloyd-Max 알고리즘을 이용하여 Gaussian 분포에 최적화된 Codebook 을 만든다.
+ 어느정도의 distortion 은 일어나도 되는 이유?
Transformer 같은 딥러닝 모델은 입력을 처리할 때 Key, Value vector의 단어 그 자체보다 새로 들어온 토큰이 원래 KV cache 에 있던 Key 들과 얼마나 유사한지(inner product 값)에 더 집중한다. 그렇기 때문에 MSE보다 inner product 의 보존이 더 중요하다.
TurboQuant
TurboQuant 는 다음과 같은 과정으로 이루어진다.
- MSE 측면에서 최적 distortion rate 를 갖는 Vector Quantizer 를 개발한다.
- 잔차에 1bit quantizer 를 적용하여 unbiased 와 low-distortion 을 갖는 inner product quantizer 를 얻는다.
- 잔차 : (실제값 - 예측값)
unbiased : (실제 매개변수 - 추정 매개변수)

(위 수식이 성립할 경우 해당 알고리즘은 Unbiased 를 보장한다고 한다.)
또한, TurboQuant Quantizer 는 다음 세 가지 목표를 가지고 설계되었다.
- d차원의 벡터를 바이너리로 변환(Quant)하는 map
- Quantization 된 이진 벡터를 다시 d차원의 벡터로 역변환(DeQuant)하는 inverse map
- 는 전단사가 아니므로, Dequant 시 distortion이 필연적으로 발생한다. 이를 최소화할 것.
그리고 앞에서 언급했던 Quantization 의 기본 조건인 MSE와 inner product 오차(quantization 전후 inner product 결과 비교)를 최소화해야 한다.
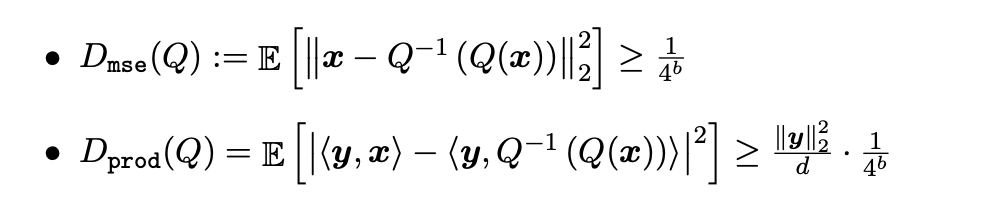
MSE 최적 Quantization
우선, TurboQuant는 MSE distortion 을 최소화하기 위해(1번 목적) 입력 벡터에 랜덤 회전을 적용하여 각 좌표에 Beta 분포를 유도한다. Quantization codebook 을 미리 만들어두려면 입력 벡터가 어떻게 분포되어있는지를 알아야 한다. 하지만 실제 입력을 Codebook 설계 단계에서 알 수는 없으므로, 최악의 케이스를 가정한다.
만약 [0.999, 0.001, 0.001, ...] 과 같이 특정 방향으로 에너지가 쏠린 입력 벡터가 들어오면, 해당 분포 경우를 가정하고 Codebook 을 설계하지 않은 이상 최악의 distortion 이 발생한다. 이런 문제를 해결하기 위해 입력 벡터가 들어오면 랜덤 회전 행렬(orthogonal matrix) 를 곱해 모든 방향에 대해 균일하게 분포하도록 조절한다.
(* orthogonal matrix 는 inner product 와 norm 을 보존하기 때문에 입력 벡터에 곱해줘도 큰 정보 손실이 일어나지 않는다.)

따라서 입력 벡터에 를 적용한 벡터 가 항상 Beta 분포를 따르기 때문에(위 수식 참조), 이 분포에 최적화된 codebook 하나로 모든 입력 벡터에 대응이 가능하다.
(d(dimensional)이 올라갈수록 Gaussian 분포 를 따른다.)
알고리즘을 정리하면 다음과 같다. - (1)

[Quant] Procedure 4~7
1. 입력 벡터에 orthogonal matrix 를 곱한 행렬을 만든다.
2. 각 좌표를 가장 가까운 Codebook의 centroid 로 mapping한다.
[DeQuant] Procedure 8~11
3. mapping 된 centroid를 통해 원래의 로 복원한다.
4. 를 곱해 역회전시킨다.
Lloyd-Max 알고리즘
Lloyd-Max 알고리즘은 특정 분포를 따르는 실수값(ex. [0.9, 0.5, 0.1 ...] 입력 벡터)를 (b는 비트 수)개의 centroid(대표값)으로 quantization 할 때 MSE 를 최소화하는 최적 Codebook을 찾는 알고리즘이다. 이 알고리즘은 다음 순서를 따른다.
초기화: centroid c₁, c₂, ..., 를 임의로 배치
반복:
Step 1 [Partition] 각 구역의 경계를 인접 centroid의 중간점으로 설정
Step 2 [Update] 각 centroid를 자기 구역 내 분포의 평균으로 업데이트
= (구역_i 범위)
수렴할 때까지 반복 → MSE가 더 이상 줄지 않으면 종료(Gaussian 최적해)
(/1차원 연속 k-means)
Inner-product 최적 Quantization
현재까지는 MSE만을 최적시키는 Quantization 방식이었다. 하지만 MSE 최적 Quantization 방식은 unbiased를 보장하지 않는다.(논문에서는 TurboQuant MSE가 bias=0.637, 즉 실제 inner product 값의 63.7%만 추정함을 밝혔다.) 이를 해결하기 위해서 해당 논문은 잔차에 QJL(Quantized Johnson-Lindenstrauss) 변환을 적용한다.
QJL을 적용한 알고리즘은 다음과 같다. - (2)

[Quant] Procedure 4~8
1. 입력 벡터를 (b-1) bits로 MSE 최적 Quantization(알고리즘(1)) 한다.
2. 잔차 를 계산한다. ()
3. 잔차 에 1bit QJL을 적용한다.
[DeQuant] Procedure 9~12
3. 앞의 알고리즘 (1)에서 언급한 를 적용한다.
4. 를 적용하여 를 복원한다.
5. (b-1) bit 의 에 1 bit 를 더해 최종 출력 를 만든다.
QJL 이란?
QJL은 해당 논문에서 제안하는 TurboQuant 알고리즘의 구현을 위해 Google Research가 공개한 기술이다.
QJL은 다음과 같이 정의한다:

성능 증명
[수식1]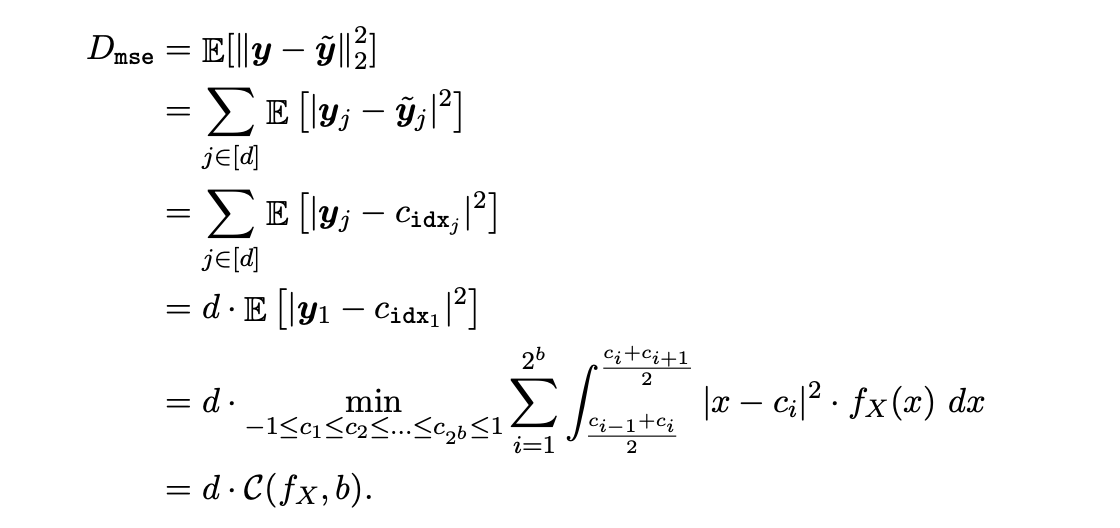
[수식2]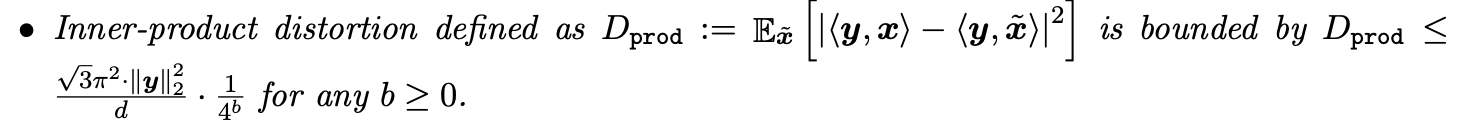
해당 알고리즘을 적용했을 때의 MSE와 inner product의 오차 상한을 구해보면 위와 같다. 따라서,
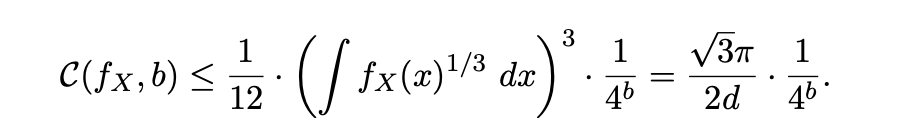
이는 Codebook의 비트폭이 1 증가할 때마다 distortion이 4배씩 감소한다는 것이다.
