2024.02.20
오늘 학습한 내용 : sql 기초
1. 데이터베이스
- 데이터의 집합
- 여러명의 사용자나 응용프로그램이 공유하는 데이터들
- 동시에 접근 가능해야한다
- 데이터의 저장 공간 자체
2. DBMS(Database management system)
- 데이터베이스를 관리 운영하는 역할
특징>
-
무결성(integrity)
- 데이터베이스안의 데이터는 오류가 없어야함
- 제약 조건(constrain)이라는 특성 가짐 -
데이터의 독립성
- 데이터베이스 크기 변경하거나 데이터 파일의 저장소 변경시 기존에 작성 된 응용프로그램은 전혀 영향 받지 않아야한다. -
보안
- 데이터베이스 안의 데이터를 소유한 사람이나 데이터에 접근이 허가된 사람만 접근할 수 있어야 한다.
- 접근할 때도 사용자의 계정에 따라서 다른 권한 가짐 -
데이터 중복의 최소화
-
응용프로그램 제작 및 수정이 쉬워짐
- 통일된 방식으로 응용프로그램 작성 가능
- 유지보수 또한 쉬워짐 -
데이터의 안전성 향상
- 대부분의 DBMS가 제공하는 백업,복원 기능 이용
- 데이터가 깨지는 문제가 발생할 경우 원상으로 복원, 복구하는 방법이 명확해짐
3. 데이터베이스의 발전
-
파일시스템 사용
- 컴퓨터 파일에 기록/저장 - 메모장,엑셀
- 컴퓨터에 저장된 파일의 내용은 읽고, 쓰기가 편한 약속된 형태의 구조
-
데이터베이스 관리시스템 (DBMS)
- 파일시스템의 단점 보안
- SQL
4. 정보시스템 구축 절차 요약
-
분석, 설계, 구현, 시험, 유지보수의 5단계
-
분석
- 구현하고자 하는 첫 번째 단계
- 시스템 분석 , 요구사항 분석이라고함
5. 데이터 모델링 필수용어
- 데이터
- 테이블
- 데이터베이스
- 열
- 열 이름
- 데이터 형식
- 행(=로우=레코드)
- 기본키(primary key)열
- 외래 키(foreign key)필드
- SQL (Structed Query Language)
6. 실습 (데이터베이스, 테이블 생성)
1. 데이터베이스 생성
-
'쇼핑몰'(shopDB)데이터 베이스 생성하기
- MySQL Workbench 실행
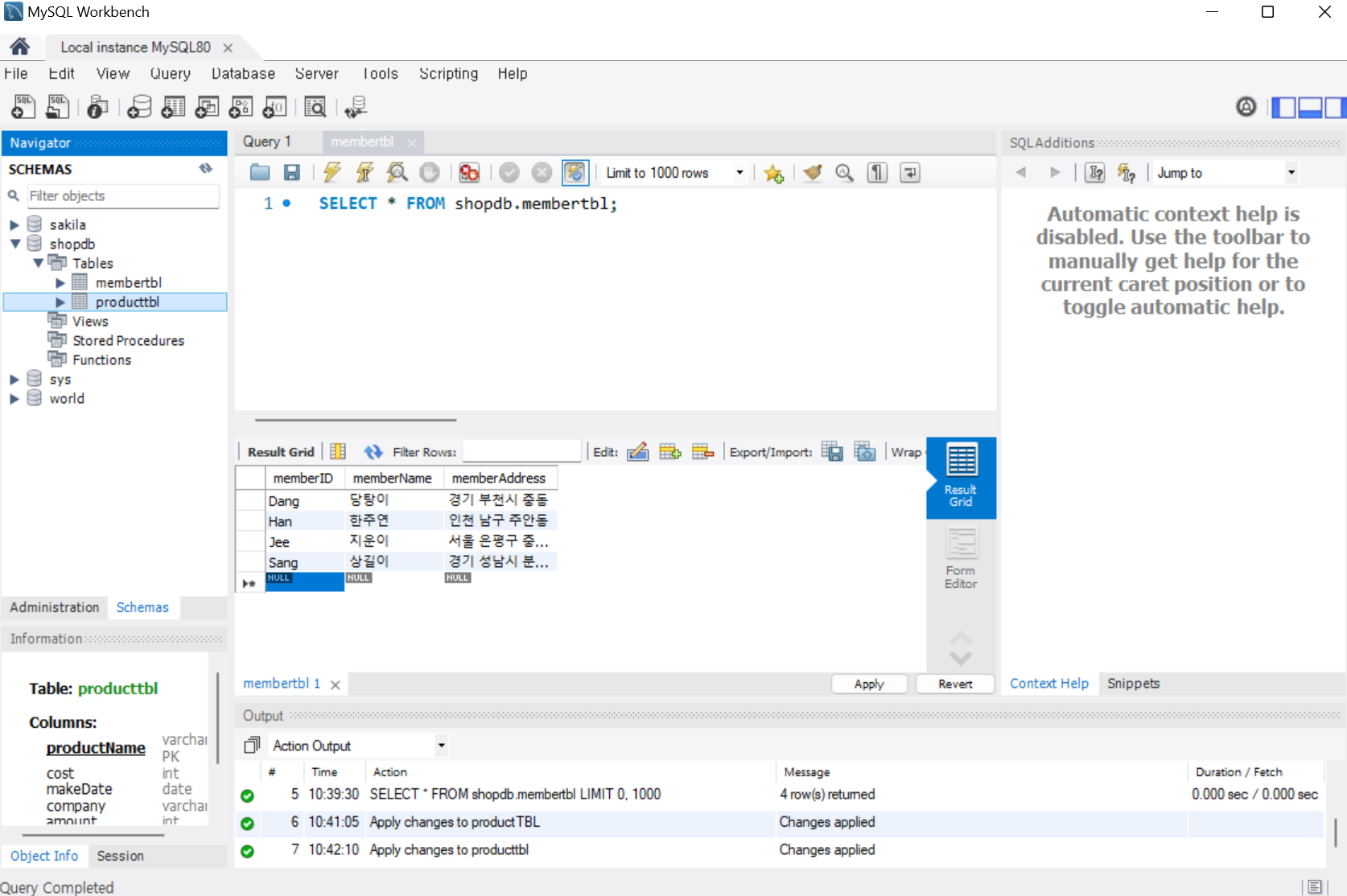
- workbench의 [SCHEMAS]의 빈 부분에서 마우스 우 클릭 후 [Create Schema](=Create Database)를 선택

- 새 스키마 창에서 Name을 shopdb로 입력하고 Apply를 클릭하면 SHEMAS에 shopdb가 생성된 것을 알 수 있고 데이터 베이스가 생성된 것이다.

- MySQL Workbench 실행
2. 테이블 생성(memberTBL, productTBL)
-
생성된 [shopdb]를 확장하고 [Tables]를 선택하고 마우스 우 클릭 후 [Create Table] 선택
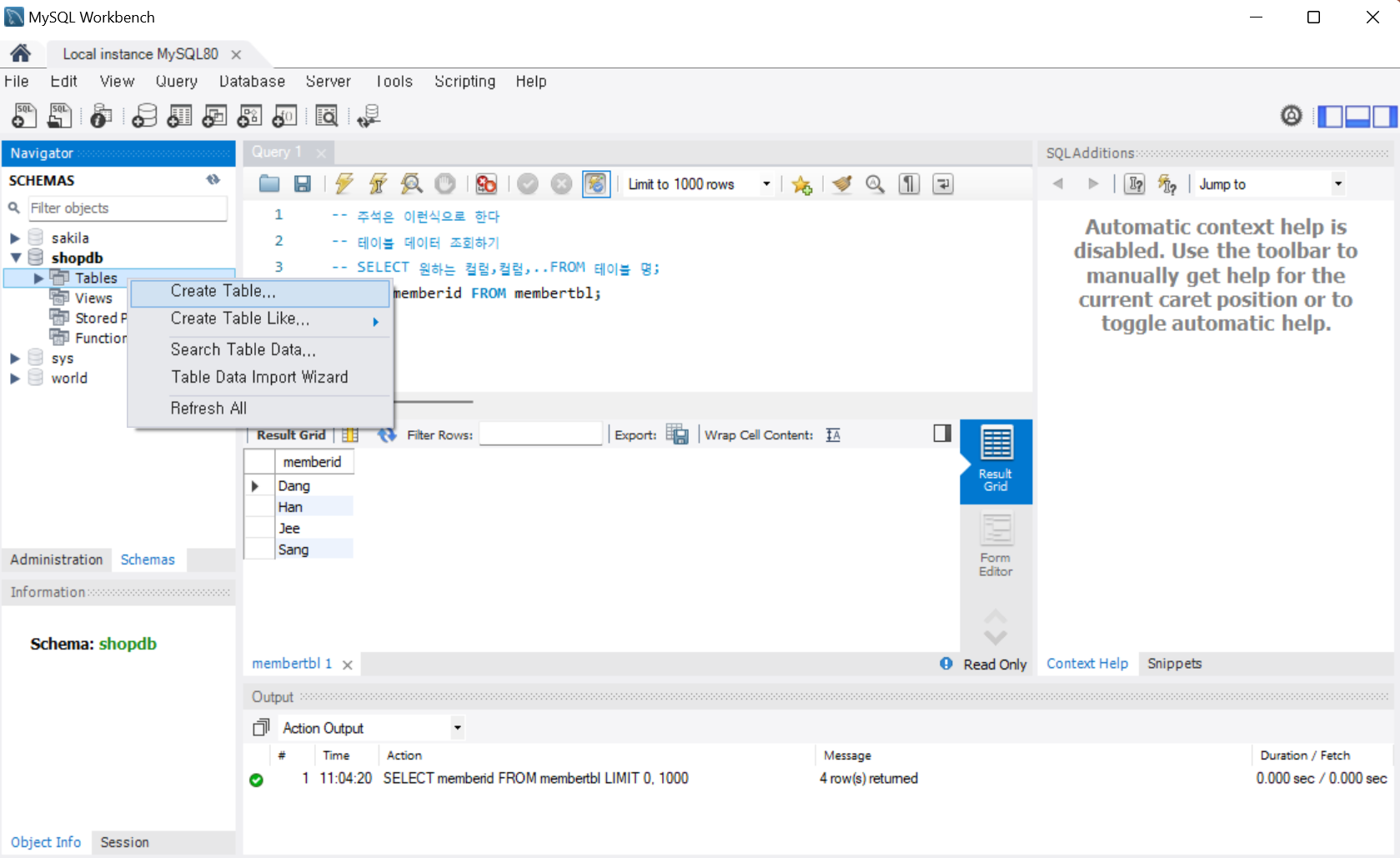
-
테이블의 내용을 입력한다.
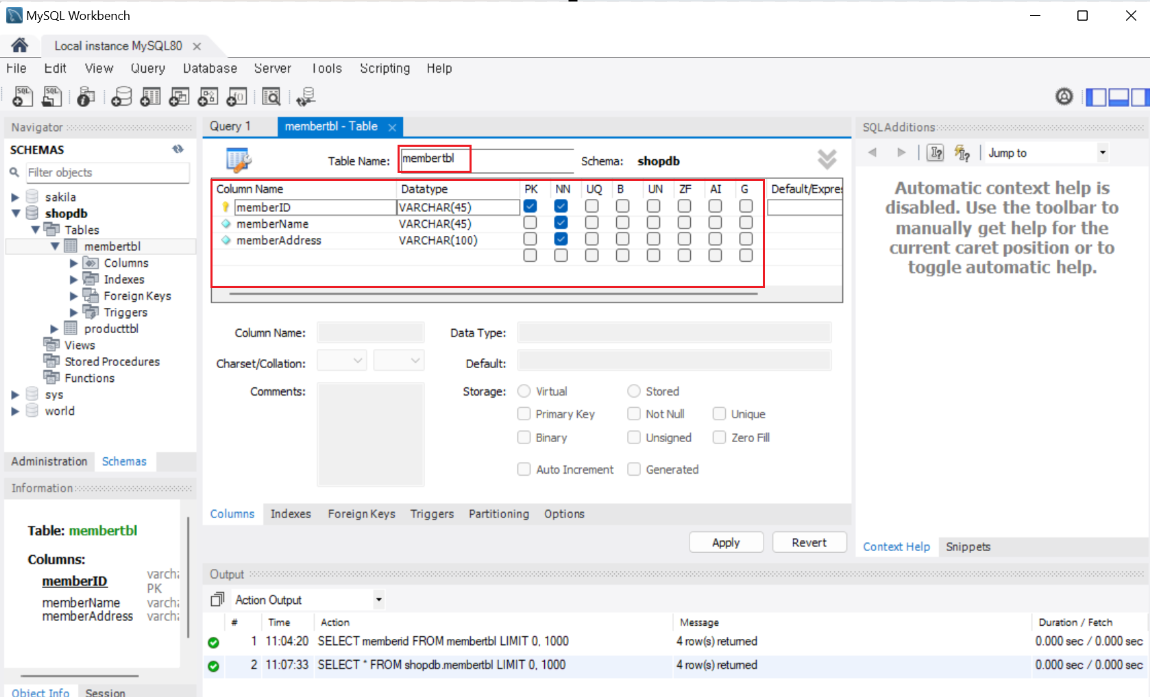
- 테이블 이름(TableName)에 memberTBL
- 열 이름 (Column Name)에 더블클릭을 통해 입력한다
- DataType은 데이터형을 선택하는 것이고 문자열은 char, varchar를 사용한다
- NN은 Not Null을 의미하는 것으로 null(아무것도 입력 x)를 허용여부를 체크하는 것이다.
- PK는 Primary Key로 해당 열을 기본 키로 설정한다는 의미이다.
-
apply를 통해 최종적으로 table을 생성한다
3. 데이터 입력
- 생성한 테이블에 실제 값을 입력하는 과정
- Navigator의 [SCHEMAS]에서 [membertbl]을 선택한 후, 마우스 오른쪽 버튼을 클릭하고 [Select Rows - Limits 1000]을 선택
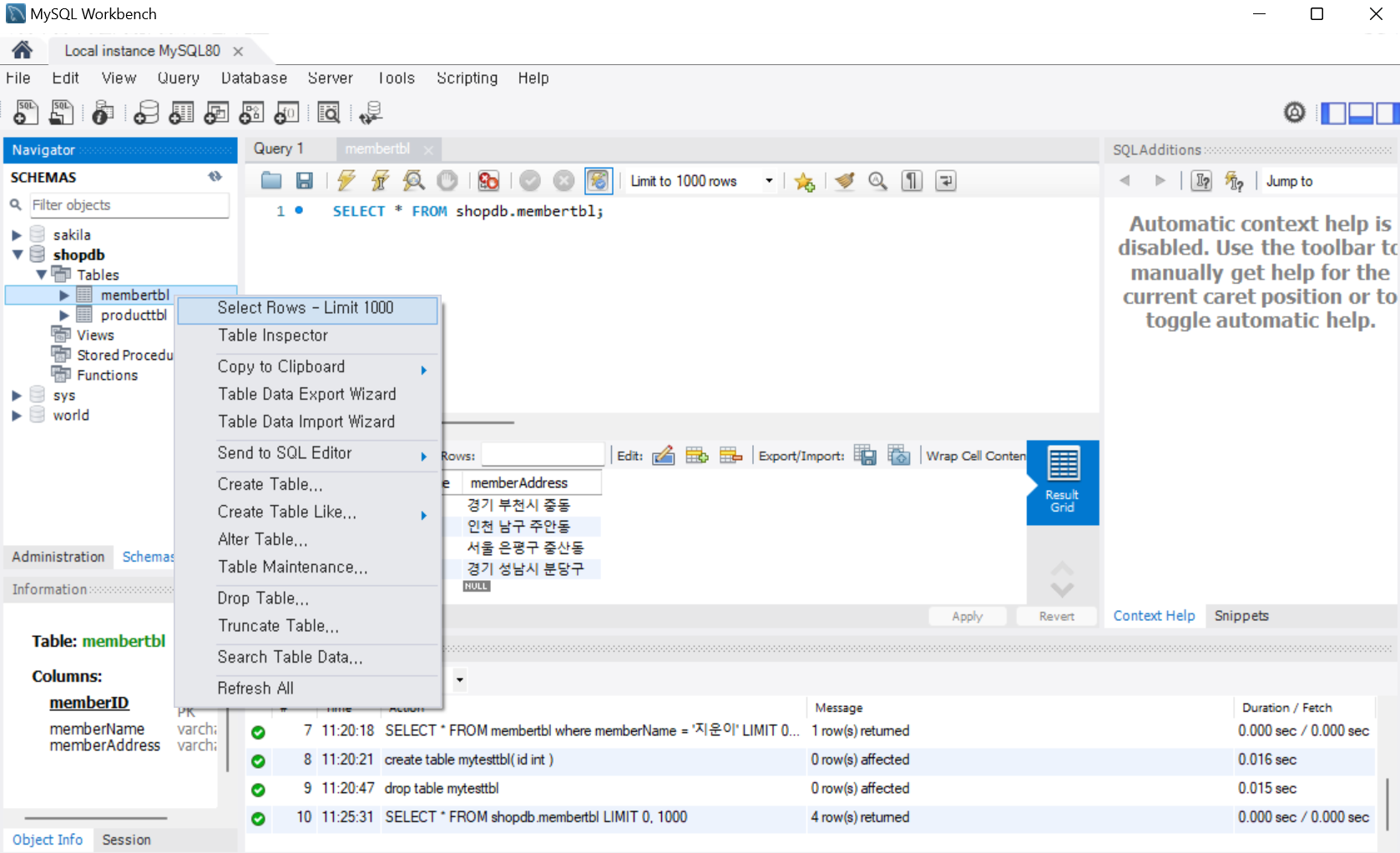
- 테이블에 실제 정보 더블 클릭을 통해 하나씩 입력
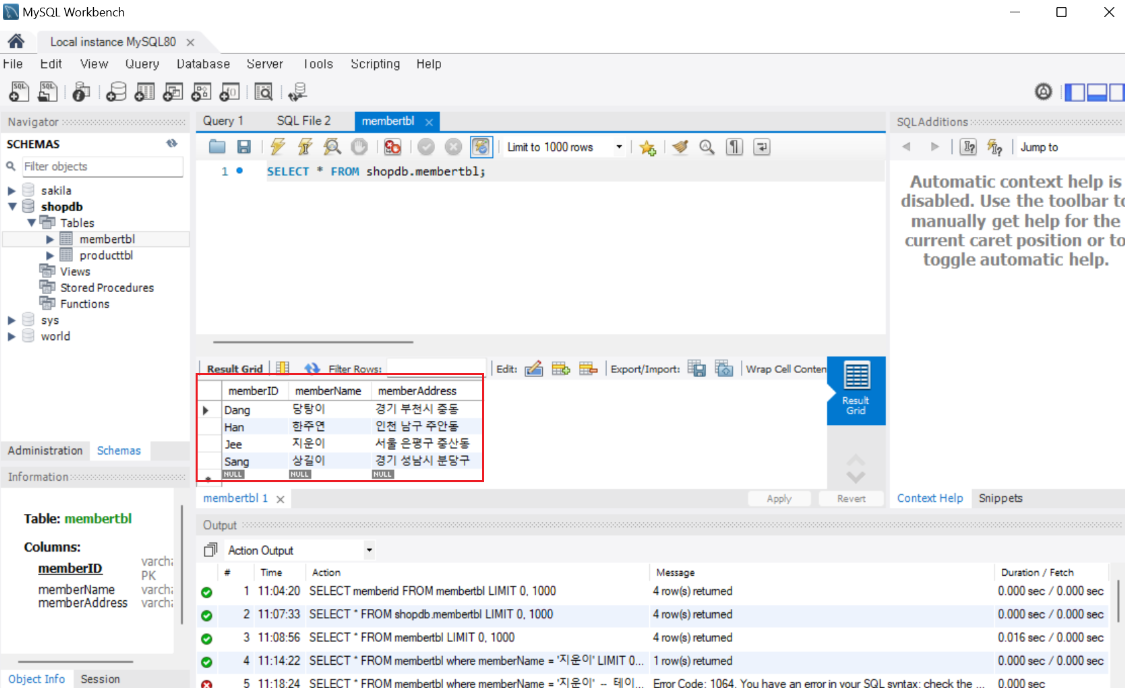
- Apply를 누르면 최종적으로 테이블에 데이터 입력 완료
- Navigator의 [SCHEMAS]에서 [membertbl]을 선택한 후, 마우스 오른쪽 버튼을 클릭하고 [Select Rows - Limits 1000]을 선택
6. SQL 기본
-
SELECT의 기본 형식 : SELECT 열 이름 FROM 테이블 이름[WHERE 조건]
SELECT 열 이름
FROM 테이블 이름
WHERE 조건 -
USE 구문
- 여러 데이터베이스 중 사용할 데이터베이스를 지정하는 구문
USE 데이터베이스_이름;
-
WHERE 절
- 조회하는 결과에 특정 조건을 줘서 원하는 데이터만 보고 싶을때 사용
SELECT 필드이름 FROM 테이블이름 WHERE 조건식;
-
관계 연산자의 사용
- OR 연산자
- AND 연산자
- 조건 연산자(=,<,<=,>,>=,<>,!= 등)
SELECT userID, NAME FROM USERTBL WHERE NAME = 'ㅇㅈㅅ';
-
BETWEEN, IN, LIKE
- 데이터가 숫자로 구성되어 있으며 연속적인 값 : BETWEEN
SELECT * FROM USERTBL WHERE BIRTHYEAR BETWEEN 1970 AND 1980
- 이산적인 값의 조건 : IN
SELECT * FROM USERTBL WHERE BIRTHYEAR IN(1972,1979,1971)
- 문자열의 내용 검색 : LIKE
- '김%' : '김'으로 시작하는 문자열 전부
- '%김% : 문자열에 '김'이 포함되어 있는 문자열 전부
- '%김' : '김'으로 끝나는 문자열 전부
SELECT * FROM USERTBL WHERE NAME LIKE '김%'
- 데이터가 숫자로 구성되어 있으며 연속적인 값 : BETWEEN
-
Subquery
-
쿼리문안에 또 쿼리문이 들어있는 것
- EX. USERTBL에서 가장 큰 키와 가장 작은 키의 회원 이름과 키를 출력하시오.
SELECT NAME, HEIGHT FROM USERTBL WHERE HEIGHT = (SELECT MAX(HEIGHT) FROM USERTBL) OR HEIGHT = (SELECT MIN(HEIGHT) FROM USERTBL);
-
-
ANY, ALL
- Any : 하위 쿼리의 결과 집합 중 하나라도 조건을 만족하는 경우
- ALL : 하위 쿼리의 결과 집합에 있는 모든 값이 조건을 만족하는지 확인
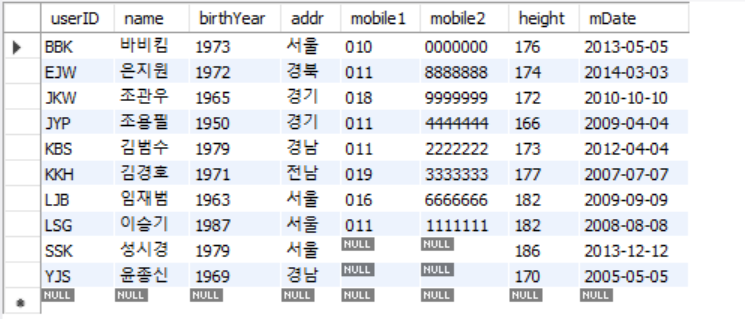
SELECT NAME, HEIGHT FROM USERTBL WHERE HEIGHT >= ANY(SELECT HEIGHT FROM USERTBL WHERE USERID LIKE 'K%'); -- SOME도 동일 ( 173보다 크거나 또는 177보다 큰) SELECT NAME, HEIGHT FROM USERTBL WHERE HEIGHT = ANY(SELECT HEIGHT FROM USERTBL WHERE USERID LIKE 'K%'); -- SOME도 동일 (173 또는 177) SELECT NAME, HEIGHT FROM USERTBL WHERE HEIGHT >= ALL(SELECT HEIGHT FROM USERTBL WHERE USERID LIKE 'K%'); -
DISTINCT : 중복제거 (출력문의 중복 제거)
SELECT DISTINCT ADDR FROM USERTBL;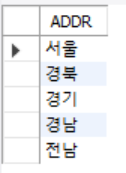
-
LIMIT : 상위 A개 출력, LIMIT A,B 상위 A~B 출력
SELECT DISTINCT ADDR FROM usertbl LIMIT 2 # 상위 2개 출력 -
테이블 복사 query
- create table .. select 구문은 테이블을 복사해서 사용할 경우 사용
- 주로 원본 테이블은 유지하고(백업) 복사본을 만들어 데이터를 다룰때 사용
형식
- create table 새로운 테이블 (select 복사할 열 from 기존 테이블)
- create table 새로운 테이블 as select 복사할 열 from 기존 테이블
기존 테이블>
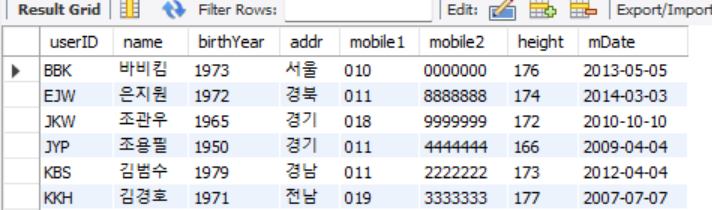
-- 테이블 복사 쿼리 --1 CREATE TABLE USERTBL_COPY (SELECT * FROM USERTBL); SELECT * FROM USERTBL_COPY; -- 원본은 유지하고 카피를 통해 데이터 조작할때 사용 --2 CREATE TABLE USERTBL_COPY2 (SELECT NAME FROM USERTBL); -- 일부분만 카피도 가능 SELECT * FROM usertbl_COPY2; --3 CREATE TABLE USERTBL_COPY3 AS SELECT NAME, ADDR FROM USERTBL; SELECT * FROM usertbl_COPY3; -
집계함수
- Group by와 함께 쓰이며 데이터를 그룹화 해주는 기능을 하는 함수
-- group by : ~별 ~ SELECT ADDR FROM USERTBL GROUP BY 1; -- 각 그룹별 로 ADDR을 묶으면 서울 경북, 경기, .. 등 지역별로 나열된다 여기서 다른 열을 추가하면 기존 데이터에서 그룹화된 열으 기준으로 데이터가 정렬된다 SELECT ADDR, AVG(HEIGHT) FROM USERTBL GROUP BY 1; -- 문제. 각 고객별, 평균 구매 갯수 SELECT * FROM buytbl; SELECT USERID, AVG(AMOUNT)AS AVG_AMOUNT FROM buytbl GROUP BY 1 ; -- 고객별 평균 구매액 SELECT * FROM buytbl; SELECT USERID, AVG(PRICE*AMOUNT)AS AVG_BUY_PRICE FROM buytbl GROUP BY 1; ``` 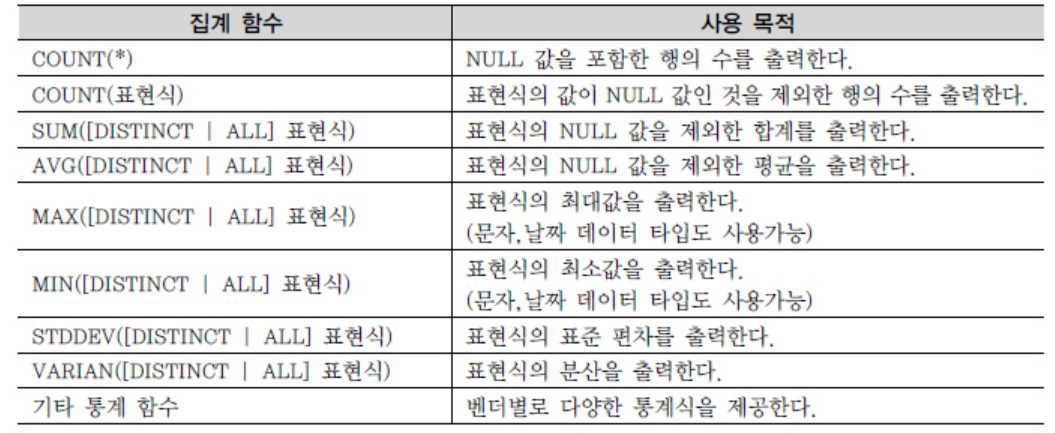 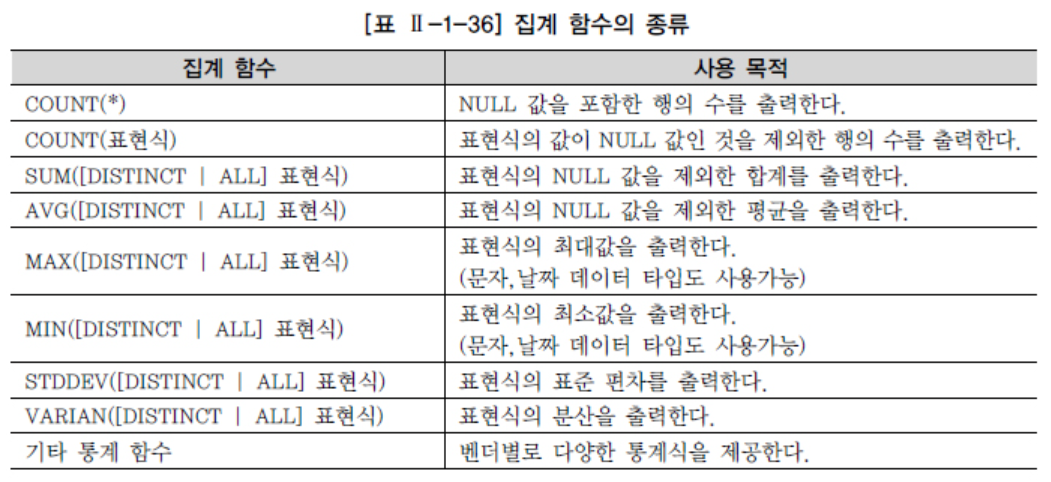 [출처]http://www.gurubee.net/lecture/2373
-
Having 절
-
Having 절은 그룹 함수를 사용하여 그룹화된 결과에 대한 조건을 지정하는 데 사용
-
where절 vs Having 절
- where절 : 개별 레코드에 대한 조건을 지정하는 데 사용
- Having절 : 그룹화된 결과에 대한 조건을 지정하는 데 사용
-
사용자 별 총 구매액 구하기
-- where절 사용 select * from(select userid as id, sum(price*amount) as total_price from buytbl group by 1)T where T.total_price > 1000 -- Having절 사용 select userid as id, sum(price*amount) as total_price from buytbl group by 1 having sum(price*amount) > 1000 -
위의 문제에서 where절의 경우 개별 열에 대한 조건을 줄수 있기에 직접적으로 sum(price*amount)에 대한 접근이 불가능하고 subquery를 통해 where절을 사용한 것이다.
-
Having절의 경우 group by로 묶인 userid에 대한 sum(price*amount)이기에 직접 접근이 가능하다.
-
-
ROLL UP
- 총합 또는 중간 합계가 필요할 때 Group by절과 함께 WITH ROLLUP구문을 사용하면 된다.
select num,groupName, sum(price*amount) as '비용'
from buytbl
group by 1,2
with rollup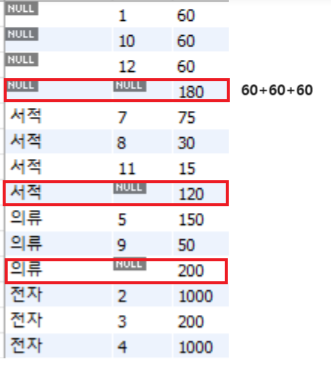
- Insert : 데이터 삽입
INSERT INTO 테이블명(열1,열2,,,) VALUES (값1,값2,,,,)
create table testtbl5 (id int, username varchar(45), age int); -- 새로운 테이블 생성
-- 1. 기본
insert into testtbl5 values (1, '홍길동', 25);
-- 2. 테이블의 열중 값을 넣고 싶지 않을 때
insert into testtbl5(id, username) values (2,'옥현승'); -- age를 입력하고 싶지않다면(null) 테이블 이름 뒤에 입력할 열의 목록을 언급해야한다.
-- 3. 테이블의 열을 순서를 바꾸어 insert 하고 싶을 때
insert into testtbl5(username, id, age) values ('신민석', 3, 27); -- 입력할 열의 순서를 바꾸고 싶어도 열의 순서를 고려하여 언급해야한다.
select * from testtbl5결과>
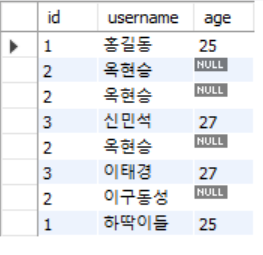
결과는 3가지의 insert문을 username만 바꿔가며 계속해서 insert 해준 결과이다.
-
Insert : auto_increment
- 테이블 속성이 auto_increment로 지정되어 있다면, insert에서는 해당 열이 없다고 생각하면 된다.
- auto_increment는 자동으로 1씩 증가시켜주는 기능을 제공
- 따라서, auto_increment로 지정된 열은 insert문에서 null값을 지정하면 자동으로 값이 입력된다.
- 단, auto_increment로 지정할 때는 꼭 primary key 또는 unique로 지정해주어야 한다.
-- 자동으로 증가하는 AUTO_INCREMENT
create table testtbl6(id int auto_increment primary key, username varchar(45), age int);
-- auto_increment가 설정된 속성은 insert시 null로 지정한다.
insert into testtbl6 values(null,'도언',27);
insert into testtbl6 values(null,'동후',7);
insert into testtbl6 values(null,'제건',90);
-- 여러개의 데이터 한 번에 insert하기
insert into testtbl6 values(null,'동성',27),(null,'민석',27),(null,'승진',27);
select * from testtbl6 Result>
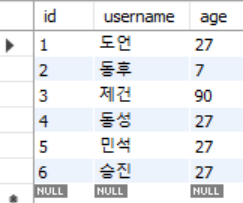
결과를 보면 id가 auto_increment에 의해 자동으로 1씩 증가된 것을 알 수있다.
-
대량의 샘플 데이터 생성하기
- select를 통해 기존의 테이블의 데이터를 갖고와 insert를 통해 다른 테이블에 넣는 방식.
형식1 (테이블 -> 테이블 by insert):
INSERT INTO 테이블명 (열1, 열2, ...)
SELECT문 ;
형식2 (테이블 생성 과정에서 다른 테이블 데이터 갖고오기):
create 새로운 테이블명
(selet 열1,열2,열3,... from 기존 테이블명);
예시>
-- 대량의 샘플 데이터 생성
-- 1. 테이블 -> 테이블
create table testtbl8 (id int, username varchar(45), age int);
insert into testtbl8
select id, username, age from testtbl6;
select * from testtbl8;
-- 2. 테이블 생성부터 데이터 갖고오기
create table testtbl9
(select id, username, age from testtbl6);
select * from testtbl9;Result>
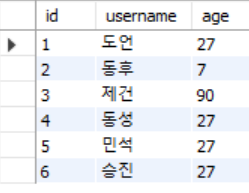
testtbl8, testtbl9 모두 testtbl6의 데이터를 그대로 갖고왔기에 결과는 다음과 같다.
