2024.02.21
오늘 학습한 내용 : SQL 심화
1. Cmd를 사용하여 데이터 업로드 하기
-
명령 프롬트를 킨다
-
파일의 경로를 찾아 복사한다.
-
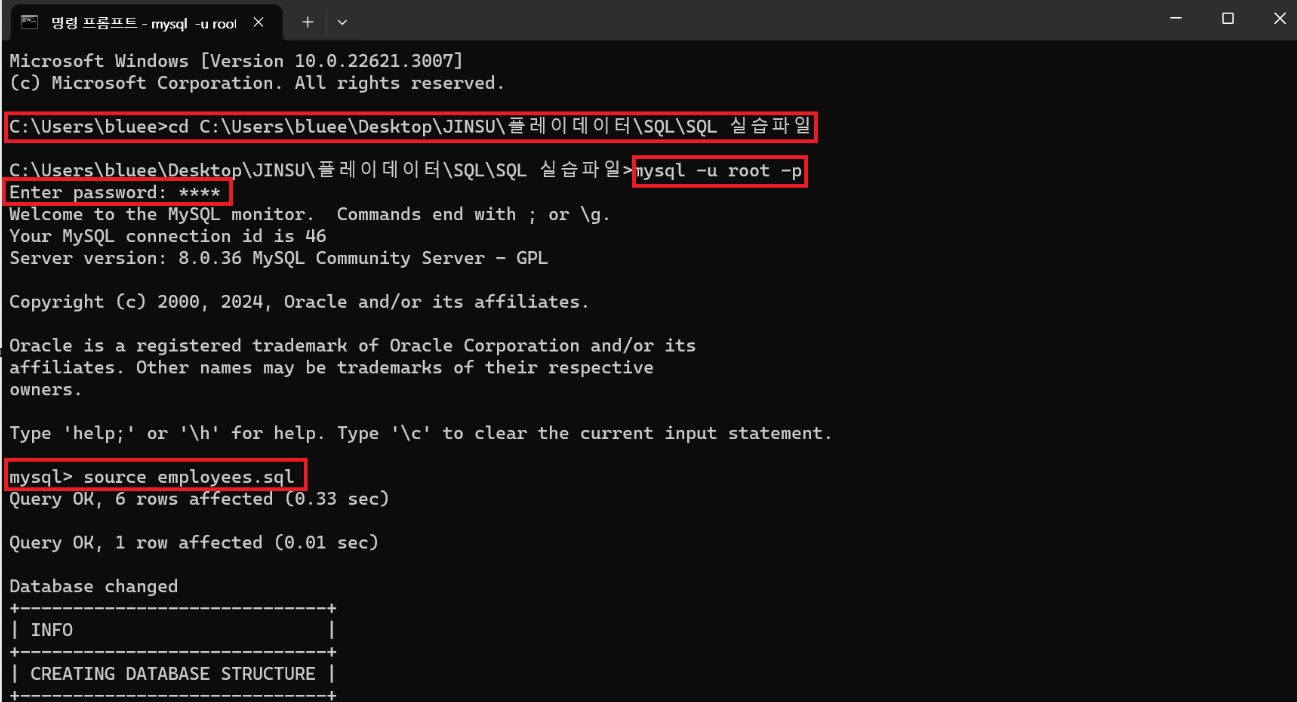
- cd 커맨드를 통해 디렉토리 경로를 파일의 경로로 변경한다.
-
- mysql -u root -p
-
- MySQL의 비밀번호를 기입
-
- source sql파일명
1~4를 통해 최종적으로 sql파일을 커맨드 프롬프트를 통해 사용이 가능하다.
2. SQL 고급
1. MySQL 데이터 형식
-
숫자 데이터 형식
- SMALLINT : 2byte/ 숫자범위 : -32,768~32,767 / 정수형
- INT
- BIGINT
- FLOAT
- DECIMAL
-
문자 데이터 형식
- CHAR
- VARCHAR
-
날짜와 시간 데이터 형식
- DATE
- DATETIME
2. 변수의 사용
-
SQL도 변수를 선언하고 사용할 수 있다. 형식은 다음과 같다.
-
형식>
SET @변수이름 = 변수의 값 ; -- 변수의 선언 및 값 대입
SELECT @변수이름 ; -- 변수의 값 출력- 실습>
-- 1. 변수 사용
USE sqldb;
set @myVar1 = 5;
set @myVar2 = 3;
set @myVar3 = 4.25;
set @myVar4 = '가수 이름 ==>';
select @myVar1, @myVar2; -- mysql 고유 문법임
select @myVar1 + @myVar3;
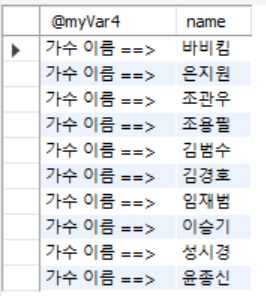
select @myVar4, name from usertbl; -- 변수를 열과 같이 사용가능 - Result>
3. 데이터 형 변환
3-1. 명시적 형 변환 (타입을 강제로 변환)
- cast()
-- 형태
-- avg(amount)값을 integer로 형변환
cast(avg(amount) as signed integer)- convert()
-- 형태
-- avg(amount)값을 integer로 형변환
-- cast()와 다르게 convert()는 함수이기에 파라미터처럼 작성
convert(avg(amount) , signed integer)- 실습>
select avg(amount) from buytbl; -- 결과는 2.9167
select cast(avg(amount) as signed integer) avgAmount from buytbl; -- 결과는 3 ,, 정수형으로 형변환됨.
select convert(avg(amount) , signed integer) avgAmount from buytbl; -- convert()는 함수이기에 cast()와 다르게 파라미터 형식으로 작성3-2. 묵시적 형 변환 (타입을 자동으로 변환)
- cast()나 convert()를 사용하지 않고 형이 변환되는 것
-- 묵시적 형변환 (자동으로 형변환)
-- cast(), convert()를 사용하지 않는 형변환
select '100'+'200';
select concat('100','200'); -- concat은 문자열을 이어주는 함수이기에 문자열이 그대로 문자열이 됨.
select concat(100,'200'); -- 정수와 문자를 연결 -> 정수가 문자로 반환되어 연결됨 (묵시적 형변환)
select 1 > '2mega'; -- 문자가 정수로 자동 형변환 '>' 연산자 때문이다. 결과 -> 1>2는 false 이기에 0 반환
select 3 > '2MEGA'; -- --> 1 반환4. MySQL 내장함수 (주말에 다시 정리)
4-1. 제어 흐름 함수
- IF(수식, 참, 거짓)
- IFNULL(수식1, 수식2)
- 수식1이 NULL이 아니면 수식1 반환, NULL이면 수식2 반환
SELECT IFNULL(NULL,'널이군요'),IFNULL(100,'널이군요);
- 수식1이 NULL이 아니면 수식1 반환, NULL이면 수식2 반환
- NULLIF(수식1, 수식2)
- 수식1과 수식2가 같으면 NULL 반환, 다르면 수식1반환
SELECT NULLIF(100,100),NULLIF(120,40);
- 수식1과 수식2가 같으면 NULL 반환, 다르면 수식1반환
- CASE ~ WHEN ~ ELSE ~END
- CASE는 정확히는 내장함수는 아니고 연산자로 분류된다.
SELECT CASE 10
WHEN 1 THEN '일'
WHEN 5 THEN '오'
WHEN 10 THEN '십'
ELSE '모름'
END AS 'CASE 연습'
- CASE는 정확히는 내장함수는 아니고 연산자로 분류된다.
4-2. 문자열 함수
4-3. 수학 함수
4-4. 날짜 및 시간함수
5. Pivot 구현
5-1. 피벗이란?
한 열에 포함된 여러 값을 출력하고, 이를 여러 열로 변환하여 테이블 반환 식을 회전하고 필요하면 집계까지 수행하는 것.
실습>
-- 1. pivottest를 위한 테이블 만들기
create table pivotTest(
uname varchar(5),
season varchar(2),
amount int
);
-- 2. 테이블에 insert를 통해 실제값 삽입
insert into pivotTest values
('a','봄',20),('b','여름',20),('c','가을',20),
('d','봄',20),('e','겨울',20),('f','여름',20)
;
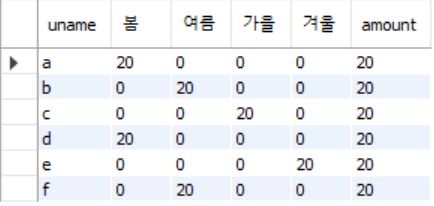
select * from pivottest;
select
uname,
sum(if(season ='봄', amount, 0)) '봄',
sum(if(season ='여름', amount, 0)) '여름',
sum(if(season ='가을', amount, 0)) '가을',
sum(if(season ='겨울', amount, 0)) '겨울',
sum(amount) as amount
from pivottest
group by 1; Result>
6. JOIN
두 개 이상의 테이블을 서로 묶어서 하나의 결과 집합으로 만들어 내는 것
6-1. INNER JOIN
- JOIN중에 가장 많이 사용
- 두 개 이상의 테이블의 공통부분을 기준으로 묶는, join 함
- 형태
select 열목록
from 첫번째 테이블 inner join 두번째 테이블
on 첫번째 테이블명.공통열 =두번째 테이블명.공통열 - 실습>
select *
from usertbl ut inner join buytbl bt on ut.userID = bt.userID -- userID가 공통조건임을 알 수 있음
where ut.name = '바비킴'; - Result>

6-2. OUTER JOIN
- 조인의 조건에 만족되지 않은 '행'까지도 포함시키는 JOIN
- LEFT OUTER JOIN , RIGHT OUTER JOIN이 존재
- LEFT OUTER JOIN이란 왼쪽 테이블의 것은 모두 출력하는 OUTER JOIN을 의미
- RIGHT OUTER JOIN은 잘 안씀 -> 테이블의 위치를 바꾸어 LEFT를 사용하면 되기에..
- 실습 >
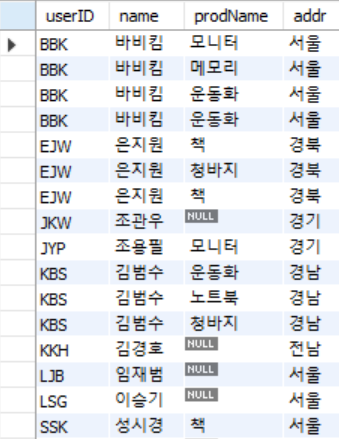
select ut.userID, ut.name, bt.prodName, ut.addr
from usertbl ut left outer join buytbl bt on ut.userID = bt.userID
order by ut.userID;- Result>
6-3. CROSS JOIN
- 한쪽 테이블의 모든 행과 다른 쪽 테이블의 모든 행을 조인
- 전체 개수 : 한쪽 테이블의 모든 행의 수 X 다른 쪽 테이블의 모든 행의 수
- 실습>
-- cross join ,, 많이 사용은 안함
create table usertbl_copy1
select * from usertbl limit 1;
select *
from usertbl_copy1 cross join buytbl;6-4. SELF JOIN
- 별도의 구문은 없고 '자기 자신'과 '자기 자신'이 조인하는 것
- 특정 열과 해당 테이블 내의 다른 행들 사이의 관계를 파악하거나, 특정 상황에서 자기 자신과의 비교를 위해 사용
- ex. 조직도 (책 참고하기)
- 실습>
-- self join
create table emptbl_1 -- 테이블 생성
(
emp varchar(10),
manager varchar(10),
tel varchar(10)
);
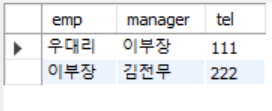
insert into emptbl_1 values -- 생성된 테이블에 값 삽입
('우대리','이부장','111'),('이부장','김전무','222');
select * from emptbl_1;
select * from emptbl_1 A inner join emptbl_1 B on A.emp = B.manager;Result>
1. emptbl_1 테이블
2. self join

6-5. UNION / UNION ALL / NOT IN / IN
-
UNION
- 두 쿼리의 결과를 행으로 합치는 것
- 형태
-- 문장1 과 문장2의 쿼리 결과를 행으로 합친다 SELECT 문장1 UNION[ALL] SELECT 문장2- 단, 문장1과 문장2의 결과 열의 개수가 같아야한다
- 데이터 형식도 각 열 단위로 같거나 서로 호환되는 데이터 형식이어야 한다
- UNION : 중복 된 열 제거 , UNION ALL : 중복 된 열 포함
-
NOT IN / IN
-
NOT IN
- 첫 번째 쿼리의 결과 중 두 번째 쿼리에 해당하지 않은 것을 조회
-
IN
- 첫 번쨰 쿼리의 결과 중 두 번째 쿼리에 해당되는 것만 조회
-
7. Stored Procedure
- Stored Procedure(저장 프로시저)는 데이터베이스에서 미리 컴파일되고 저장된 SQL 쿼리의 집합
- 즉, MySQL에서 제공하는 프로그래밍 기능이다
- 밑에서 더 자세히 다룰 것.
8. 테이블과 뷰
8-1. 제약 조건
-
데이터의 무결성을 지키기 위한 제한된 조건
-
특정 데이터를 입력할 때 무조건적으로 입력되는 것이 아닌, 어떠한 조건을 만족했을 때에 입력되도록 제한
a. 기본키(Primary Key) 제약 조건
-
기본 키에 입력되는 값은 중복될 수 없으며 NULL 값이 입력될 수 없다.
-
기본 키로 생성된 것은 자동으로 '클러스터형 인덱스'가 생성된다.
-
테이블에서 기본키를 하나 이상의 열에 설정이 가능하다
-
설정방법> 예약어 'Primary key'를 이용한다.
USE tabledb; drop table if exists buytbl, usertbl; -- 조건문 만족시 테이블 삭제 create table usertbl -- 테이블 생성 ( userid varchar(8) not null primary key, name varchar(10) not null, birth year int not null ); -
Describe문을 통해 테이블 정보를 볼 수 있다.
Describe usertbl;
b. 외래키(Foriegn Key) 제약 조건
- 외래 키 테이블이 참조하는 기준 테이블의 열은 반드시 Primary Key이거나 Unique 제약 조건이 설정되어야 함
c. unique 제약 조건
d. check 제약 조건
e. default 정의 -
10. 뷰 (view)
- 가상의 테이블
- 복잡한 쿼리나 빈번하게 사용한 쿼리를 묶어서 사용하고 싶을 때 사용
- 형태>
-- view 형태
create view 뷰명 as
select 열1,열2,... from 기존 테이블 명;
-- view 호출 (query문과 동일하게 사용 즉, 뷰를 테이블로 봐도 무방)
select 열1,.. from 뷰명 ;11. 인덱스 (index)
-
데이터베이스에서 검색 속도를 향상시키기 위해 사용되는 데이터 구조
-
즉, 데이터를 조회할 때(특히 select문 - query) 빠르게 접근하도록 도와준다.
-
Primary Key로 지정한 열은 클러스터형 인덱스 생성
-
장점
- 검색 속도가 빨라질 수 있다.(단, 항상 그런것은 아님)
- 해당 쿼리의 부하가 줄어들어 시스템 전체 성능이 향상된다.
-
단점
- 데이터베이스 크기의 10%정도 추가 공간이 필요하다
- 처음 인덱스를 생성하는데 시간이 많이 소요될 수 있다
- 데이터의 변경 작업(insert,update,delete)이 자주 일어나면 오히려 성능이 나빠질 수 있다.
-
클러스터형 인덱스(clustered index)
- '영어 사전'이라고 생각하면 편하다.
- 테이블당 한 개만 생성 가능
- 행 데이터를 인덱스로 지정한 열에 맞춰서 자동 정렬한다. (영어사전으로 비유하면 -> 알파벳 순서로 제공되는 영어사전에 새로운 단어를 추가하면 해당 단어의 맨 앞 글자를 통해 '자동정렬'한다.)
- Primary Key를 설정하면 자동으로 클러스터형 인덱스가 형성된다. 즉,Primary Key로 설정한 '열'을 기준으로 자동 정렬 된다.
-
보조 인덱스(secondary index)
- 책 앞쪽 부분의 '찾아보기' 또는 목차에 제시된 페이지라고 생각하면 편하다
- 테이블당 여러개 생성 가능
- Unique Key를 설정하면 자동으로 보조 인덱스가 형성된다.
- 실습>
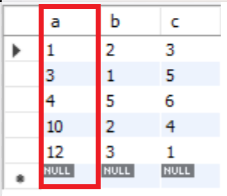
use sqldb; -- sqldb DB 사용 create table tb1 -- 간단한 테이블 형성 ( a int primary key -- primary key -> 자동으로 클러스터형 인덱스 생성 , b int unique -- secondary key -> 보조 인덱스 생성 , c int unique ); -- 데이터 삽입 insert into tb1 values(1,2,3); insert into tb1 values(4,5,6); insert into tb1 values(10,2,4); insert into tb1 values(3,1,5); insert into tb1 values(12,3,1); -- 데이터 조회 select * from tb1; -- 결과를 보면 a열(Primary key column)이 자동정렬이 된 것을 알 수 있음 show index from tb1; -- show index 구문을 통해 해당 테이블의 인덱스를 볼 수 있다. - Result>

-
인덱스 내부 동작
- B-Tree(Balanced Tree, 균형트리)
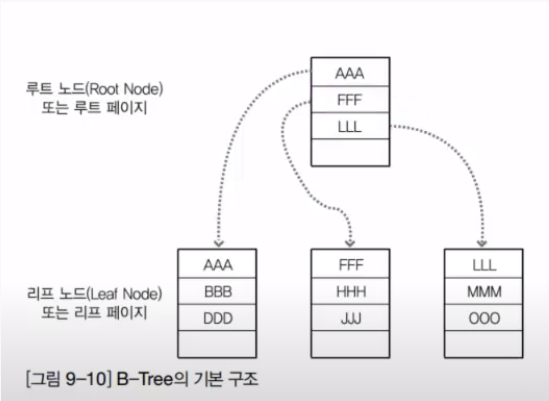
- B-Tree(Balanced Tree, 균형트리)
12. Stored program
-
MySQL에서 제공되는 프로그래밍 기능
-
'쿼리문의 집합'으로 어떤 동작을 일괄처리하기 위한 용도
-
프로그래밍에서의 '모듈'이라고 생각하면 된다.
-
만드는 방법은 2가지 존재
-
방법1 >
DELIMITER $$ CREATE PROCEDURE 스토어드 프로시저 명 (IN 또는 OUT 파라미터1, .. ) BEGIN SQL 프로그래밍 코딩 (Query문) END $$ DELIMITER ; -- 호출 call 스토어드 프로시저 명(); -
방법2>
Begin과 End 사이에 Query문을 넣고 apply를 하면 된다.
-
-
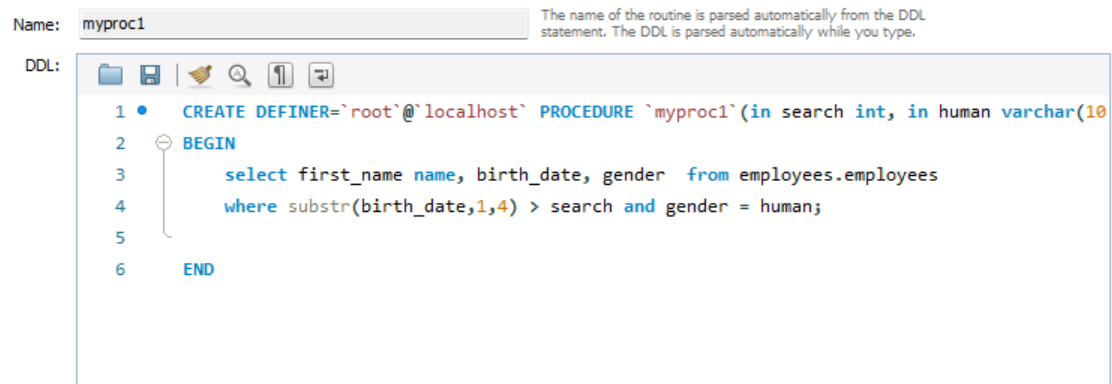
실습1>
-- birth_date > 1950 직원중에 남성만 추출 --> 파라미터를 넣어서 만들어보기
-- sp : myproc1으로 만들기
call myproc1(1950, 'F'); -- 이런식으로 만들면됨
- 실습2>
-- 국가명을 입력하면 수도를 찾아서 수도의 이름을 출력하는 프로시저
select * from world.city where id = 2331;
select * from world.country where code = 'KOR';
-- 조인 (QUERY문 만들기)
select wci.CountryCode Country, wci.name capital from world.city wci inner join world.country wco on wci.CountryCode = wco.code
where wci.CountryCode = 'KOR' and wci.id = wco.Capital;
call country_procedure('ARG');
보완점 >
- 내장 함수
- UNION -> 실습해보기
- INDEX -> 인덱스 구조 공부하기
1,2,3은 주말에 다시 보완해야한다.
