우선, 글을 작성하기 전 이 글의 모든 내용은 김영한님의 JAVA 강의를 바탕으로 함을 알립니다.
💡Hash 알고리즘
List와 Set
List: 순서 유지, 중복 허용, 인덱스 접근 가능의 특징을 갖는 선형 자료구조 (앞에서 많이 언급)Set: 유일한 요소의 컬렉션- 특징
- 유일성 :
Set의 요소는 중복이 불가능 - 순서 미보장 :
Set의 요소는 순서가 정해져 있지 않음
- 유일성 :
- 용도 : 중복을 허용하지 않고, 요소의 유무만 중요한 경우 사용
- 특징
◻️ 직접 구현해보는 Set
public class MyHashSetV0 {
private int[] elementData = new int[10];
private int size = 0;
// O(n)
public boolean add(int value) {
if (contains(value)) {
return false;
}
elementData[size] = value;
size++;
return true;
}
// O(n)
public boolean contains(int value) {
for (int data : elementData) {
if (data == value) {
return true;
}
}
return false;
}
public int size() {
return size;
}
@Override
public String toString() {
return "MyHashSetV0{" +
"elementData=" + Arrays.toString(Arrays.copyOf(elementData,size)) +
", size=" + size +
'}';
}
}- 배열을 활용한
Set을 구현한 결과Set의 특성상 중복이 허용되면 안되기 때문에 add() 메서드에서 중복되지 않은 대상만 요소로 추가가 가능하도록 contains()를 통해 배열의 모든 요소를 검사하는 과정을 진행한다. - 즉, 성능이 O(n)으로 좋지않다.
Hash 알고리즘 도입
배열을 데이터의 저장소로 사용한 Set의 경우를 다시 생각해보자. 배열의 경우 인덱스를 통한 조회하는 기능은 O(1)으로 높은 성능을 갖는다. 그렇다면 데이터를 배열의 인덱스로 사용한다면 인덱스 조회와 데이터 검색이 함께 가능하지 않을까??
즉, 입력되는 데이터를 동일한 인덱스 공간에 저장하면 조회와 검색이 빨라지지 않을까?
◻️ 데이터 값을 배열 인덱스로 사용하는 경우
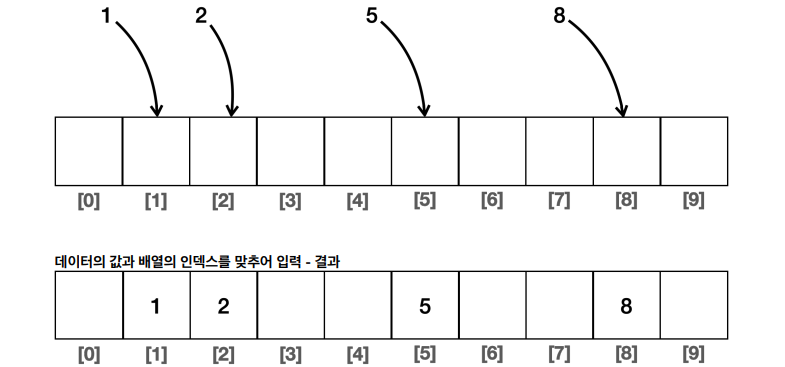
- 인덱스 1에는 데이터 1이 들어있고, 인덱스 8에는 데이터 8이 들어있다. 즉, 저장하는 데이터와 인덱스를 완전히 맞추어 인덱스 번호가 데이터가 되고, 데이터가 인덱스 번호가 되었다.
하지만 낭비되는 메모리가 너무 많다.만약에int의 모든 범위에서 특정 숫자를Set자료구조에 추가한다고 가정하면 빈공간으로만 메모리를 거의 다 사용하는 상황이 발생한다.
◻️ 나머지 연산
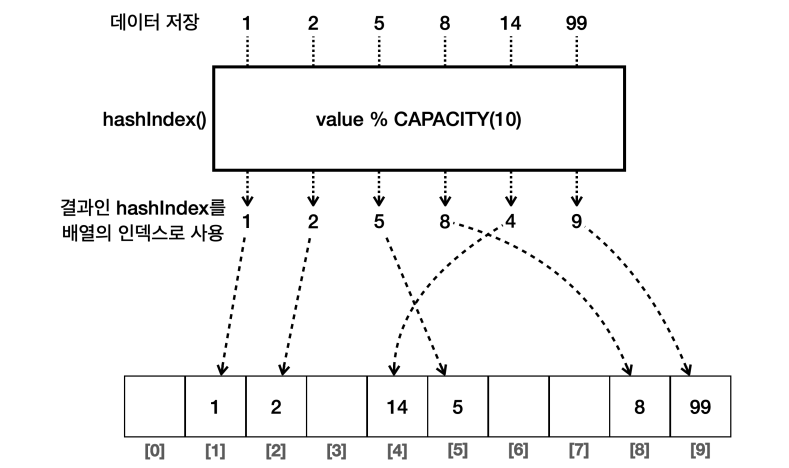
메모리를 절약하면서, 넓은 범위의 값을 사용할 수 없을까? 나머지 연산을 사용하면 가능하다. 예를들어, 배열의 크기를 10으로 고정했다고 가정하자.
1 % 10 = 12 % 10 = 23 % 10 = 34 % 10 = 45 % 10 = 524 % 10 = 499 % 10 = 9
나머지 연산을 활용하면, 나머지 연산의 결과는 절대로 배열의 크기를 넘지 않고 결국 배열의 크기만큼 배열에 저장할 수 있게 된다.
◻️ 해시 인덱스
해시 인덱스(hashIndex) 란 배열의 인덱스로 사용할 수 있도록 원래의 값을 계산한 인덱스를 의미한다.
◻️ 해시 충돌
99와 9를 모두 10으로 나누면 동일한 나머지인 9를 해시 인덱스로 갖게 된다. 이렇게 해시 충돌이란 다른 값을 입력했지만 같은 해시 코드가 나오는 것을 의미한다. 어떻게 해야할까?
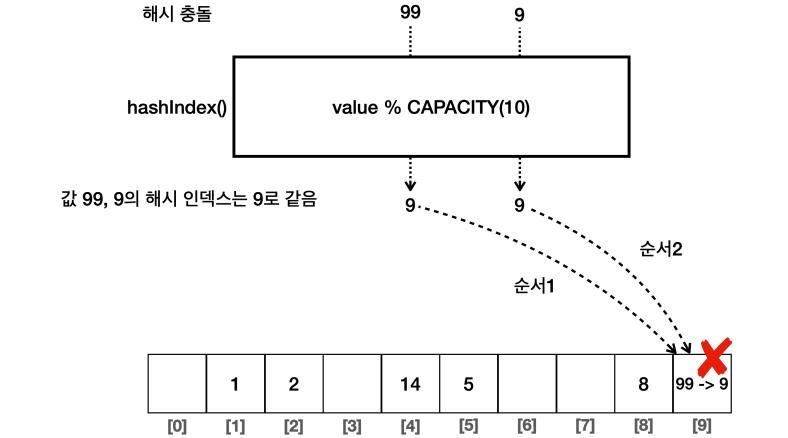
- 99와 9를 같이 저장하면 된다
- 배열의 원소를 또다른 배열로 만든다면 동시 저장이 가능하다

◻️ 해시 충돌 조회 및 성능
해시충돌이 발생한 경우 내부의 데이터를 하나씩 비교해보면 결과를 찾을 수 있다. 위의 예에서 99를 조회한다고 가정하자.
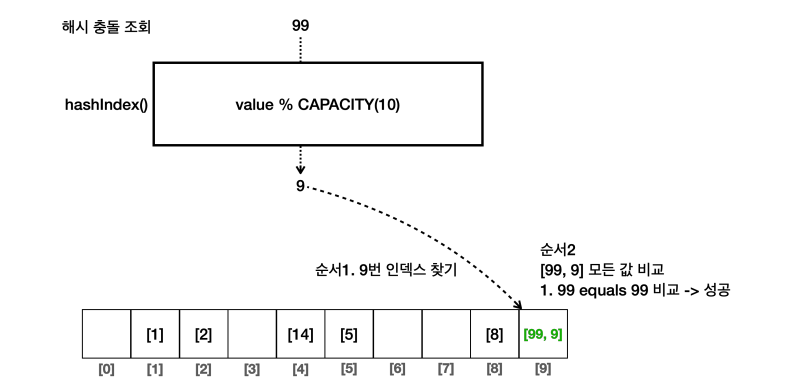
- 9번 인덱스까지 배열의 특성을 통해 조회
- 9번 인덱스의 내부 배열에서 반복문과
equals()를 통해 배열내의 모든 값을 비교하여99를 검색
해시 충돌 상황에서의 값 조회 과정을 살펴보니 추가되는 데이터에의해 특정 인덱스에 데이터가 많이 몰리는 경우가 발생할 수 있다.
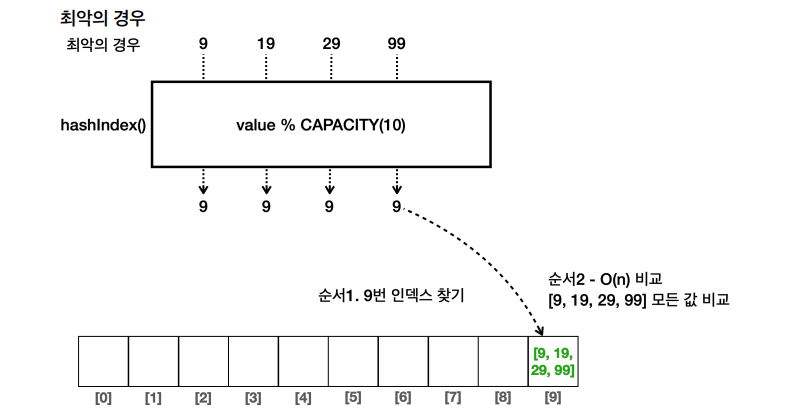
- 이 경우 모든 입력 데이터에 대한
해시 인덱스는9가 된다 - 따라서 9번 인덱스에 모든 데이터가 저장되고, 특정 데이터를 조회할 때 결국 반복문에 의해 저장된 데이터 수 만큼 비교가 이루어져야 한다
- 즉, 최악의 경우
O(n)의 성능을 갖게 된다.
정리
해시 알고리즘에 의한해시 인덱스를 사용하는 경우- 데이터 저장
- 평균 : O(1)
- 최악 : O(n)
- 데이터 조회
- 평균 : O(1)
- 최악 : O(n)
- 데이터 저장
- 해시 인덱스를 사용하는 방식에서 최악의 경우(해시 충돌에서의 최악 경우)는 거의 발생하지 않고 배열의 크기만 적절하게 잡아주면 대부분 O(1)의 성능을 갖는다

JINSU