우선, 글을 작성하기 전 이 글의 모든 내용은 김영한님의 JAVA 강의를 바탕으로 함을 알립니다.
💡Set 인터페이스
이전 포스팅에서 Set 자료구조의 특징과 Hash 알고리즘에 대해서 학습하였다. JAVA는 컬렉션을 통해 Set 인터페이스를 제공하고 대표적으로 HashSet,LinkedHashSet,TreeSet이 구현체로 다양한 Set 자료 구조 기능을 제공한다.
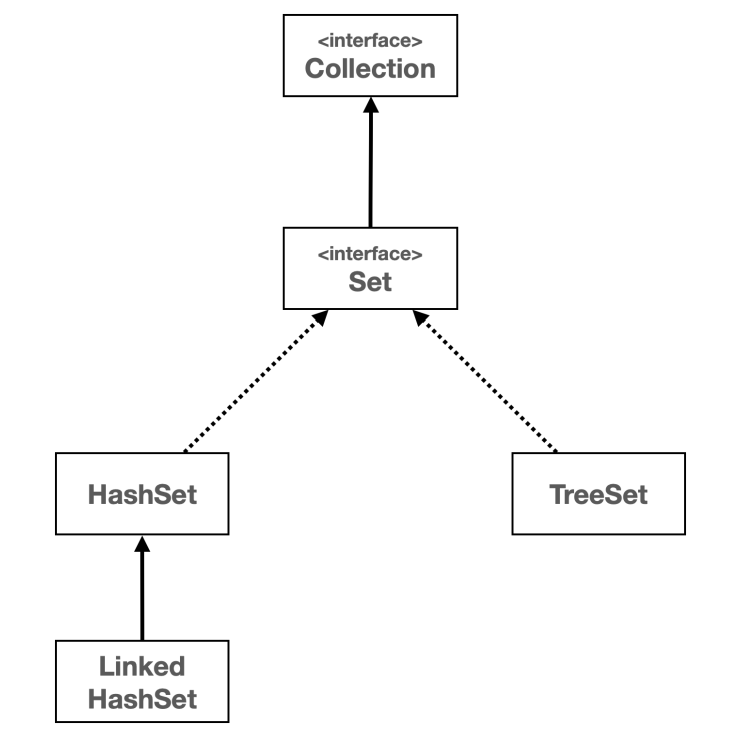
HashSet:Hash알고리즘에 기반한Set자료구조LinkedHashSet:HashSet의 데이터 저장 공간을LinkedList로 구성하여데이터 입력 순서를 보장하는Set자료구조TreeSet:이진 탐색을 기반으로데이터를 정렬한Set
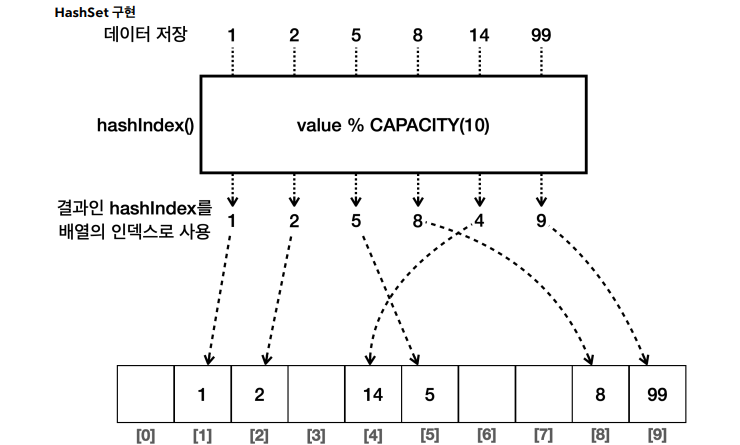
HashSet
구현:Hash자료구조를 사용하여 요소 저장순서: 데이터 입력 순서를 보장 x시간복잡도: 주요 연산(추가, 삭제, 검색)은 평균적으로 O(1)용도: 데이터 순서 상관없이 데이터의 유일성이 중요한 경우
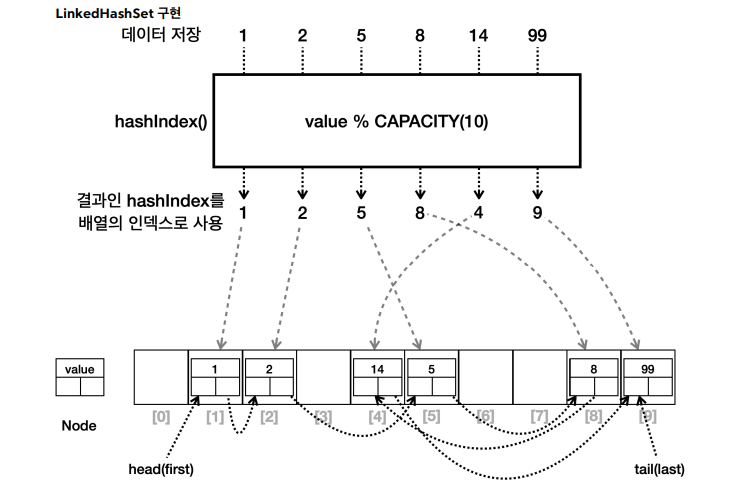
LinkedHashSet
구현:HashSet에LinkedList를 추가하여 입력된 요소들의 순서를 보장순서: 데이터 입력에 따른 순서 보장시간복잡도: 주요 연산(추가, 삭제, 검색)은 평균적으로 O(1)용도: 데이터의 유일성과 데이터 입력 순서 모두를 보장해야 하는 경우
TreeSet
구현:TreeSet은 이진 탐색 트리를 개선한 레드-블랙 트리를 내부에서 사용순서: 요소들은 정렬된 순서로 저장됨. 순서의 기준은 비교자(Comparator)로 변경 가능시간 복잡도: 주요 연산은O(log n)의 시간 복잡도를 가짐용도: 데이터를 정렬된 순서로 유지하면서 Set의 특성을 활용해야 하는 경우
◻️ Tree 구조
- 트리구조는 부모 노드와 자식 노드로 구성
이진 트리: 자식이 2개까지 올 수 있는 트리이진 탐색 트리: 특정 노드의 왼쪽 자손은 더 작은 값, 오른쪽 자손은 더 큰 값을 가져정렬이 된 것을이진 탐색 트리라고 한다
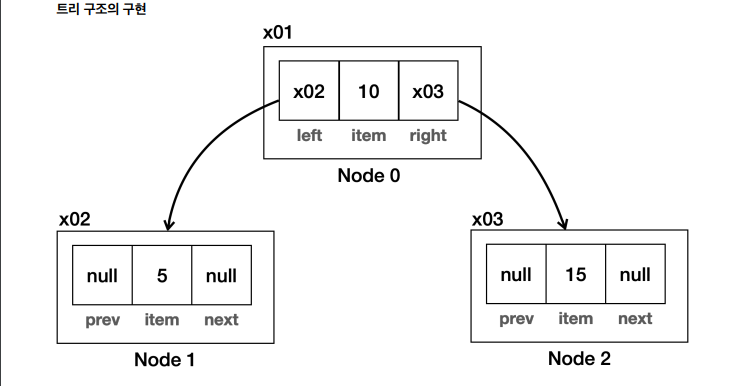
class Node {
Object item;
Node left;
Node right;
}◻️ 이진 탐색 트리의 Big-O
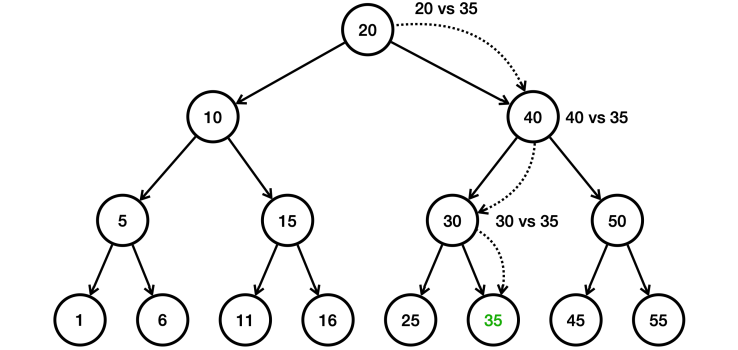
위의 Tree 구조에서 사용한 데이터를 보면, 15개의 데이터로 구성되어 있는 것을 확인할 수 있다. 여기서 숫자 35를 검색한다고 가정하면 다음과 같은 과정이 진행된다.
- 1번 : root인 20과 검색 대상인 35를 비교 -> 35가 크기에 오른쪽으로 찾아감
- 2번 : 40 vs 35 -> 40이 크기에 왼쪽으로 찾아감
- 3번 : 30 vs 35 -> 35가 크기에 오른쪽으로 찾아감
- 4번 : 35 vs 35 -> 35를 찾음
15개의 데이터에서 4번의 연산만으로 결과를 얻음. 이는 List의 검색(O(n)) 보단 성능이 좋고 Hash의 검색(O(1))보다는 느리다.
이진 탐색의 핵심원리는 한번의 연산으로 데이터의 절반을 날릴 수 있다는 점이다. 비교 대상 기준 크다 와 작다의 이분법적 개념으로만 접근하기 때문이다. 예를들어, 검색 대상이 35인 경우 root(20) vs 35 에서 35가 root 보다 크기 때문에 root 보다 작은, 왼쪽에 있는 데이터들은 고려할 필요가 없어진다.
즉, 16개의 데이터 기준 이진 탐색은 16->8->4->2->1 ,4번의 연산만으로 목표에 도달할 수 있다는 의미이고 이를 일반화 하면 n개의 데이터 기준 logN (밑은 2이다)의 연산이 필요 함을 알 수 있다.
따라서, 이진 탐색 트리의 Big-O 는 O(logN) 이다.

JINSU