Natural Join
두 개의 테이블이 갖는 공통 column으로 수행하는 join이다. 두 relation간에 일치하는 모든 column에 대해 join을 수행한다.
natural join은 간단하지만 여러 가지 오류를 만들 수 있다.
예를 들어, student table과 instructor table에 모두 id라는 attribute가 존재한다면 두 테이블의 id가 서로 다른 값을 나타내는데도 불구하고 해당 column을 기준으로 병합을 진행한다.
attribute 중복
다른 join과 달리 natural join은 동일 attribute의 중복을 허용하지 않는다.
이름이 같은 column을 모두 병합 기준으로 삼기 때문에 해당 column은 하나씩만 남겨둔다.
보통 join을 수행할 때는 on 명령어를 이용해 어떤 column을 기준으로 할 것인지 조건을 추가하지만 natural join은 중복 column에 대해 모두 적용하므로 따로 조건을 정해줄 필요가 없다.
따라서 using, on과 같이 사용할 수 없다.
조건을 명시하고 싶다면?
where문을 활용해서 조건을 제시할 수 있다.
select name
from student natural join takes, course
where takes.course_id = course.course_id혹은 조건을 주어야 하는 부분을 따로 빼서 inner join을 수행할 수도 있다.
select name
from (student natural join takes) join course using course_idOuter Join
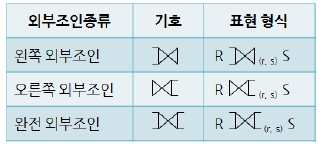
outer join은 대상이 되는 테이블의 값을 모두 보존하고, 채워지지 않는 부분은 null로 남겨두는 방식을 말한다.
inner join이 존재하는 값만 추려서 join하는 것과는 대조적이다.
Outer Join은 세 가지로 나뉜다.
left outer, right outer
left outer, right outer join은 join 기호를 기준으로 각각 왼쪽, 오른쪽에 있는 테이블의 값을 보존하는 것을 말한다. join을 하다 보면 특정 tuple이 다른 relation에 존재하지 않을 수 있는데, 기준 테이블의 tuple을 보존하기 위해 없는 값을 null처리하기도 한다.
full outer
두 relation의 모든 tuple을 보존하는 join이다.
using
using 으로 attribute 조건을 설정할 수도 있다. 두 relation 모두에 있는 atrribute를 조건으로 쓰고 full outer join을 하면 natural join과 같다.
중복 column 보존
inner, outer join을 수행하면 기준이 된 column이 중복 상태로 남아있는다.
왜냐하면 relation a에서는 값이 존재하지만 b에서는 값이 존재하지 않는 케이스가 발생하기 때문이다. 따라서 두 column은 이름만 같고 tuple 내용이 다를 수 있다.
Views
실제 존재하지는 않는 virtual relation을 view 라고 한다.
사용자들은 view를 테이블처럼 사용하지만 DB상에는 테이블로 정의되어있지 않다.
create view v as select ~
테이블과 구분되는 view의 기능적 특징은 대부분 읽기 전용이라는 점이다. view는 어차피 기준 테이블의 상태에 따라 계속 변하기 때문에 update를 할 필요가 없다.
table, with와 다른 점은?
view는 결과값이 아니라 저장된 select문으로, 함수에 가깝다.
이런 이유로 기준 테이블의 데이터가 바뀐다면 view가 보여주는 값도 변한다.
view는 다른 view를 사용해서 새로 정의할 수 있는데, 돌고 돌아서 자기 자신을 참조하게 되면 recursive하다고 한다.
이런 식으로 view를 정의할 때 다른 view를 조건으로 쓰면 create view 명령어 안에 기준 view가 들어가는데, 이것을 view expansion 이라고 부른다.
materialized view
view는 원래 가상 객체지만 실제화하면 materialized view가 된다.
Updates
view에 tuple을 삽입하려면 insert into view values(); 를 사용한다.
그런데 view 자체가 너무 복잡한 기능을 포함하지 않도록 제작된 것이기 때문에 대부분의 데이터베이스에서는 간단한 view를 대상으로만 수정을 일부 허용한다.
아래는 업데이트가 가능한 view의 조건이다.
- from절에서 하나의 테이블만 참조한다.
- select절은 distinct나 aggregate, expression을 포함하지 않는다.
- 집계와 관련이 있는 group by나 having을 쓰지 않는다.
- 업데이트 시 column을 새로 생성하면 null값으로 채워진다.
Transaction
DB에서 여러 가지 작업을 묶는 단위를 말한다.
begin;
update ~
update ~
end;트랜잭션은 작업이 성공적으로 끝나서 확정하는 commit work,
또는 작업이 실패해서 이전으로 되돌리는 rollback work 두 가지의 상태를 가진다.
트랜잭션의 조건
- 고립성
동시에 발생하는 다른 트랜잭션이 서로 간섭하면 안 된다. - 원자성
트랜잭션은 더 쪼개질 수 없다.
단위에 해당하는 모든 작업이 전부 성공하거나 전부 실패해야 한다. - 무결성
작업 완료 전후로 데이터의 무결성을 보장해야 한다.
이를 위해 몇 가지 조건을 세워두고 검사하는 경우가 있다.
트랜잭션의 데이터 제약사항
무결성을 지키기 위해 트랜잭션은 대상 relation에 대해 작업 전후로 몇 가지 조건을 확인한다.
무엇을 조건으로 쓰는지는 relation마다 다르며 예시는 다음과 같다.
- not null
- primary key
- unique
- check(P) (조건을 만족해야 삽입/수정 가능)
constraints 확인 시점
check, unique, not null등의 조건은 트랜잭션 커밋 시점에 확인하므로 수행되는 동안 일시적으로 위반되어도 괜찮다.
unique
unique로 선언한 attribute는 candidate key가 될 수 있다. primary key와 다르게 이 경우 null값을 허용한다.
referential intergrity
레퍼런스 무결성이란 테이블 간에 공유하는 foreign key와 관련이 있는 개념이다.
두 테이블 사이에 공유하는 외래 키가 어느 한 쪽에서만 삭제된다면 데이터 무결성이 훼손되었다고 볼 수 있다.
그래서 보통은 참조되는 테이블의 primary key를 이용해 레퍼런스를 정한다.
referential intergrity를 위해 cascading action을 적용할 수 있다.
cascading action이란?
table a가 table b를 참조했을 때, table b에서 해당 값이 지워지면 a에 있는 데이터도 삭제하는 기능이다. 이를 통해 데이터 무결성을 지킬 수 있다.
on delete cascade, on update cascade 등의 명령어로 사용할 수 있다.
// cascade를 활용하여 키를 생성하는 예시
CREATE TABLE orders (
order_id INT PRIMARY KEY,
order_date DATE,
customer_id INT,
FOREIGN KEY (customer_id) REFERENCES customers(customer_id) ON DELETE CASCADE
);cascading action을 사용하는 대신 set default나 null값으로 아예 초기화할 수도 있다.
Built-in Data Types in SQL
date : 'yyyy-mm-dd' 등 다양한 표시 방법 사용
time : 'hh:mm:ss' 또는 여기에 ms까지 추가
timestamp : 날짜 + 시간
interval : 시간을 기간으로 표시
Large-object Types
사진, 동영상, CAD 파일 등 대용량 파일은 해당 타입에 저장된다.
blob : binary large object
clob : character large object
쿼리는 large object type 파일 자체를 반환하지 않고, 해당 객체가 저장된 주소를 반환한다.
User-defined Types
create type 명령어를 통해서 타입을 정의할 수 있다.
// 예시
create type Dollars as numeric (12, 2) finalcreate domain 명령어를 사용하면 도메인을 정의할 수 있다.
도메인은 타입과 비슷하지만, 제약 조건(constraints)을 포함할 수 있다.
create domain person_name char(20) not nullIndex Creation
자주 사용하는 데이터에 색인을 부여할 수 있다.
다음 구문을 자주 사용한다고 생각해보자.
select *
from employee
where dept_name='CS'이때 매번 select문의 전체 column을 조사하기보다는, 직원의 dept_name 목록을 따로 두었을 때 더 빠르게 작업이 가능할 것이다.
특히 인덱스는 데이터가 어떤 테이블의 어떤 위치에 존재하는지도 저장하기 때문에 효율적이다.
// 인덱스 생성
create index index_employee_dept
on employee(dept_name)
// 인덱스 삭제
drop index_employee_deptAuthorization
권한은 크게 read(select라고도 한다), insert, update, delete에 대해 주어진다.
해당 권한을 가진 사람은 resource 변조, index 생성과 삭제, alteration, drop를 수행할 수 있다.
권한을 부여할 때는 grant 명령어를 사용하고 회수할 때는 revoke 를 사용한다.
grant <privilege list> on <relation or view> to <user list>이 때 user list에는 user id또는 public, role등을 지정할 수 있다.
public으로 지정할 시 모두에게 권한을 준다는 것을 의미한다.
// 권한 부여
grant select on department to ami, peter
// 권한 회수
revoke select on student from peterRoles
유저들 중에서 특정 권한을 가진 사람과 아닌 사람을 분류하여 구별하기 위해 세운 기준이다.
// 역할 생성
create role instructor
// 역할 부여
grant instructor to saariaReference Authorization
foregin key를 만들 수 있는 권한을 참조 권한(references)이라고 한다.
참조 권한이 필요한 이유는?
테이블의 key가 주민등록번호, 계좌번호 등 민감한 정보라면 다른 테이블에서 이를 foregin key로 이용하려고 할 때
