데이터베이스
1.[DB] DBMS
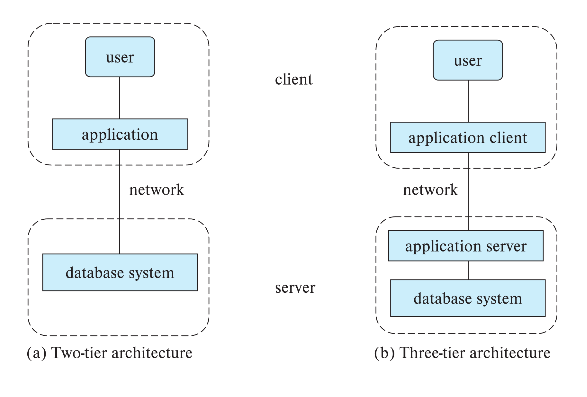
DBMS Atomicity of updates DB에서 업데이트 단위가 있을 때 단위 안에서 여러 기능이 수행되더라도 업데이트 자체는 성공 혹은 실패 케이스만 남겨야 한다. Concurrent access by multiple users 여러 유저에게 동시에 업데이
2.[DB] 기초 용어

DB에서만 특수하게 쓰이는 비절차적 언어일반 프로그래밍 언어와 혼용할 수 있음JAVA, C등의 호스트 언어 안에 SQL이 임베디드로 들어간 경우API로 함수를 호출하여 사용하는 경우logical design1\. 필요한 attribute 결정2\. relation sc
3.[DB] 관계형 데이터베이스
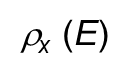
attributes -> relation schema각 데이터가 공유하는 타입을 domain이라고 한다. 관계형 DB에서 attribute 값은 더 쪼개질 수 없는 가장 작은 단위에 해당한다.keyDB상에 중복 없이 하나만 존재하여 인덱싱에 쓰이는 값superkeyke
4.[DB] SQL
SQL에 대해 알아보자
5.[DB] Intermediate SQL
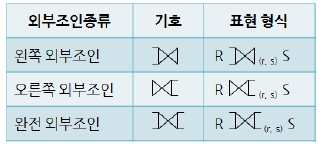
두 개의 테이블이 갖는 공통 column으로 수행하는 join이다. 두 relation간에 일치하는 모든 column에 대해 join을 수행한다.inner join과 다른 점은?inner join을 하면 같은 이름의 column이 테이블에 그대로 남아 각각 존재하지만,
6.[DB] Advanced SQL
보충 필요
7.[DB] SQL 문법 정리 - (1)
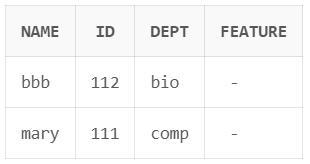
기초 문법, update, alter, set operations, aggregate functions
8.[DB] E-R모델과 DB 디자인
예상되는 DB유저에게 필요한 데이터를 정의한다.데이터 모델을 선택한다.추상화한 데이터 모델을 DB 스키마로 구현한다.이 단계에서 논리적 디자인과 물리적 디자인을 정한다.DB를 설계할 때 생각할 점중복을 최대한 피해야 한다.덜 구현한 부분이나 기능이 모자란 부분이 없도록
9.[DB] 정규화
DB를 join하다보면 데이터 중복이 생겨 수정이 어려워지기도 한다.이런 상황에 데이터 정규화(Normalization)가 필요하다.테이블을 두 테이블로 나눠서 중복값을 제거하는 방법이다.데이터 분할 시 손실이 발생하는 경우 lossy decomposition 이라고
10.[DB] 데이터베이스의 물리적 구조
Redundant Arrays of Independent Disks의 줄임말이다.여러 개의 디스크를 병렬로 쓴다.용량이 크고 속도도 빠르다.하나의 디스크에서 오류가 발생하더라도 백업이 있으므로 안정적이다.미러링(섀도잉)모든 디스크를 복제해서 논리 디스크가 두 개의 물리
11.[DB] 데이터 스토리지 구조
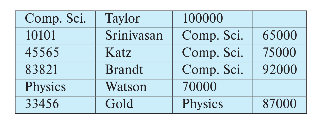
데이터 스토리지에서 레코드를 저장하는 방법과 버퍼를 다루는 방법을 알아보자.